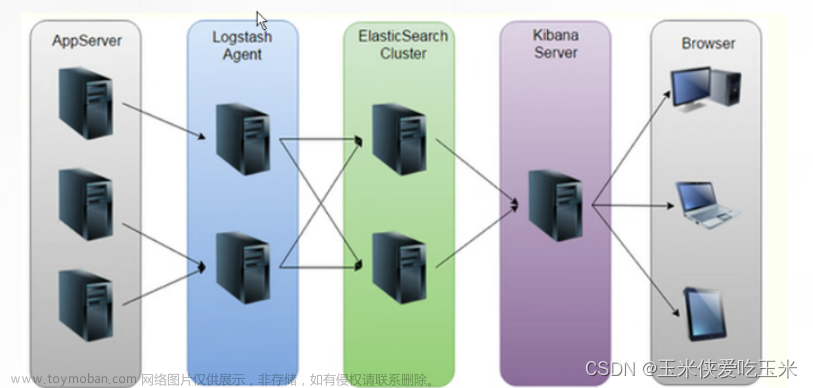
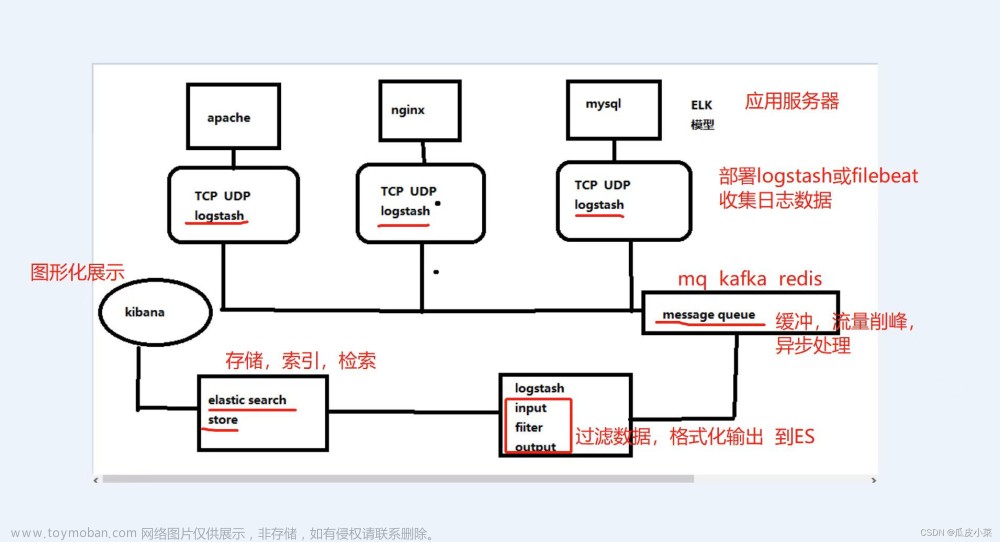
简介
Graylog 是一个用于集中式日志管理的开源平台。在现代数据驱动的环境中,我们需要处理来自各种设备、应用程序和操作系统的大量数据。Graylog提供了一种方法来聚合、组织和理解所有这些数据。它的核心功能包括流式标记、实时搜索、仪表板可视化、告警触发、内容包快速配置、索引设置、日志发射器管理和处理管道。
-
流(Streams):流作为对传入消息进行标记的方法。它可以实时将消息路由到不同的类别,并使用规则指示Graylog将消息路由到适当的流中。
-
搜索(Search):Graylog提供了一个搜索页面,可以直接搜索日志。使用类似于Lucene的简化语法,用户可以从下拉菜单中配置相对或绝对的时间范围。搜索结果可以保存,也可以作为仪表板小部件进行可视化,从搜索界面直接添加到仪表板中。
-
仪表板(Dashboards):仪表板是对日志事件中包含的信息进行可视化或摘要的方式。每个仪表板由一个或多个小部件组成,通过使用字段值生成数据来可视化或摘要事件日志数据,如计数、平均值或总数。用户可以创建指标、图表、图形和地图来更直观地呈现数据。
-
告警(Alerts):通过事件定义和条件创建告警。当特定条件满足时,将其存储为事件,并触发通知。
-
内容包(Content Packs):内容包可以加速特定数据源的设置过程。它可以包含输入/提取器、流、仪表板、告警和处理管道。例如,用户可以为支持安全用例创建自定义输入、流、仪表板和告警。然后,将内容包导出,并在新安装的Graylog实例上导入,以便节省配置时间和工作量。
-
索引(Indexes):索引是OpenSearch和Elasticsearch中存储数据的基本单位。索引集提供了保留、分片和复制等存储数据的配置选项。通过在每个索引上设置值,如保留和轮换策略,可以对不同的数据应用不同的处理规则。
-
Graylog Sidecar:Graylog Sidecar是一种管理日志发射器(如Beats或NXLog)的代理工具。这些日志发射器用于收集Linux和Windows服务器的操作系统日志。日志发射器读取本地日志文件,然后将其发送到集中式日志管理解决方案。Graylog支持管理任何日志发射器作为后端。
-
处理管道(Processing Pipelines):Graylog的处理管道允许用户对特定类型的事件运行规则或一系列规则。通过与流关联,管道可实现消息的路由、拒绝列表、修改和丰富,提高数据处理的灵活性。
通过这些核心功能,Graylog提供了强大而灵活的工具来帮助用户收集、解析和分析日志数据,从而发现问题并做出相应决策。无论是小型企业还是大型组织,Graylog都为日志管理提供了全面可靠的解决方案。
Graylog最简架构
Graylog基于把日志存储在数据节点、使用Elasticsearch或OpenSearch作为搜索引擎来提供强大的日志管理和分析功能。
- Graylog服务器
Graylog服务器是Graylog架构中的核心组件,它通过与数据节点交互,为用户提供一个简化的数据访问和搜索接口。用户可以通过Graylog服务器提交搜索查询,而无需直接与数据节点进行交互,从而极大地简化了数据的访问和处理过程。 - 数据节点
日志数据存储在数据节点中,其中可以使用Elasticsearch或OpenSearch作为存储引擎。这两个开源搜索引擎具备强大的索引和搜索能力,使用户能够高效地查询和分析大量的日志数据。Graylog 5.1仅支持Elasticsearch的7.10.2版本!我们建议您使用OpenSearch 2.5作为数据节点以支持Graylog 5.1。 - MongoDB
MongoDB用于存储元数据,如用户信息和流配置。这些数据并不包含实际的日志数据,因此对系统性能影响较小。MongoDB运行在Graylog服务器进程旁边,占用的磁盘空间很小。
之前的文章中【Graylog之最小化部署安装(Ubuntu 22.04)】有介绍如何在Ubuntu 22.04上最小化安装Graylog,这次我们换成在Docker中最小化来部署Garylog,同时我们也将原来的Elasticsearch换成了OpenSearch。
部署
主机设置
在启动 OpenSearch 之前,您应该查看一些重要的系统设置,这些设置可以影响服务的性能。
- 关闭主机上的内存分页和交换以提高性能。
sudo swapoff -a
- 增加 OpenSearch 可用的内存映射数量。
# 检查 sysctl.conf 文件中是否已经存在 vm.max_map_count 设置
if grep -q "vm.max_map_count" /etc/sysctl.conf; then
# 如果已存在设置,则使用 sed 命令将其修改为 262144
sudo sed -i 's/vm.max_map_count.*/vm.max_map_count=262144/' /etc/sysctl.conf
else
# 如果不存在设置,则在文件末尾添加新的设置
echo "vm.max_map_count=262144" | sudo tee -a /etc/sysctl.conf
fi
# 重新加载内核参数
sudo sysctl -p
# 通过检查值来验证更改是否已应用
cat /proc/sys/vm/max_map_count
拉取如下三个镜像
docker pull mongo
docker pull opensearchproject/opensearch:latest
docker pull graylog/graylog:5.1
编辑Docker Compose文件并启动
version: '3'
services:
mongo:
image: mongo
restart: always
volumes:
- mongo_data:/data/db
networks:
- graylog-net
opensearch:
image: opensearchproject/opensearch:latest
restart: always
environment:
- cluster.name=graylog
- node.name=opensearch
- discovery.type=single-node
- network.host=0.0.0.0
- action.auto_create_index=false
- plugins.security.disabled=true
- "OPENSEARCH_JAVA_OPTS=-Xms1g -Xmx1g"
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
volumes:
- opensearch_data:/usr/share/opensearch/data
networks:
- graylog-net
graylog:
image: graylog/graylog:5.1
restart: always
environment:
- GRAYLOG_PASSWORD_SECRET=GrayLog@12345678
- GRAYLOG_ROOT_PASSWORD_SHA2=8c6976e5b5410415bde908bd4dee15dfb167a9c873fc4bb8a81f6f2ab448a918
- GRAYLOG_HTTP_EXTERNAL_URI=http://127.0.0.1:9000/
- GRAYLOG_TRANSPORT_EMAIL_ENABLED=true
- GRAYLOG_TRANSPORT_EMAIL_HOSTNAME=smtp.tech.com
- GRAYLOG_TRANSPORT_EMAIL_PORT=25
- GRAYLOG_TRANSPORT_EMAIL_USE_AUTH=false
- GRAYLOG_TRANSPORT_EMAIL_USE_TLS=false
- GRAYLOG_TRANSPORT_EMAIL_USE_SSL=false
- GRAYLOG_ELASTICSEARCH_HOSTS=http://opensearch:9200
- GRAYLOG_ROOT_TIMEZONE=Asia/Shanghai
entrypoint: /usr/bin/tini -- wait-for-it opensearch:9200 -- /docker-entrypoint.sh
networks:
- graylog-net
depends_on:
- mongo
- opensearch
ports:
- 9000:9000
- 1514:1514
- 1514:1514/udp
- 2055:2055
volumes:
- graylog_data:/usr/share/graylog/data
- /etc/timezone:/etc/timezone
- /etc/localtime:/etc/localtime
volumes:
mongo_data:
driver: local
opensearch_data:
driver: local
graylog_data:
driver: local
networks:
graylog-net:
以上主要定义了三个服务:MongoDB、OpenSearch和Graylog,并设置了它们的相关配置。
MongoDB服务使用mongo镜像,设置了持续重启(restart: always)。它将/data/db目录挂载为mongo_data卷,并与graylog-net网络关联。
OpenSearch服务使用opensearchproject/opensearch:latest镜像,同样设置了持续重启。它定义了一系列环境变量用于配置OpenSearch,包括集群名称、节点名称、发现类型、网络主机、禁用安全插件等等。此外,还设置了内存锁定和文件打开限制等系统限制。/usr/share/opensearch/data目录被挂载为opensearch_data卷,并与graylog-net网络关联。
Graylog服务使用graylog/graylog:5.1镜像,同样设置了持续重启。它定义了一系列环境变量来配置Graylog,包括密码密钥、根密码哈希、HTTP外部URI、电子邮件传输配置、OpenSearch主机等等。入口点是/usr/bin/tini -- wait-for-it opensearch:9200 -- /docker-entrypoint.sh,它在启动Graylog之前将等待OpenSearch服务就绪。Graylog服务与graylog-net网络关联,并依赖于MongoDB和OpenSearch服务。端口映射包括9000用于Web界面、1514和2055用于接收日志数据。关于Graylog的一系列环境变量都可以通过环境变量进行设置。只需将参数名称以GRAYLOG_为前缀,并全部使用大写字母。具体配置参考【service.conf】。
另外,该docker-compose.yml文件定义了三个卷:mongo_data、opensearch_data和graylog_data,它们分别用于持久化存储MongoDB、OpenSearch和Graylog的数据。
最后,定义了一个名为graylog-net的网络,用于连接MongoDB、OpenSearch和Graylog服务。
请注意,您需要根据您自己的配置和需求进行适当的更改,例如更改密码、主机名、网络配置等。保存并命名为docker-compose.yml文件,然后在包含该文件的目录中运行以下命令启动这三个服务:
docker-compose up -d
这将启动MongoDB、OpenSearch和Graylog服务,并您可以通过访问http://hostip:9000/来访问Graylog的Web界面。以上YML文件中定义的默认用户名密码为 admin/admin 文章来源:https://www.toymoban.com/news/detail-652891.html
文章来源:https://www.toymoban.com/news/detail-652891.html
Reference:
[1] https://opensearch.org/docs/latest/install-and-configure/install-opensearch/docker/
[2] https://go2docs.graylog.org/5-0/setting_up_graylog/server.conf.html
[3] https://www.joda.org/joda-time/timezones.html
[4] https://go2docs.graylog.org/5-1/downloading_and_installing_graylog/docker_installation.htm
[5] https://hub.docker.com/r/graylog/graylog
[6] https://hub.docker.com/r/opensearchproject/opensearch
[7] https://hub.docker.com/_/mongo文章来源地址https://www.toymoban.com/news/detail-652891.html
到了这里,关于【Ubuntu】简洁高效企业级日志平台后起之秀Graylog的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![[ELK] ELK企业级日志分析系统](https://imgs.yssmx.com/Uploads/2024/01/810686-1.png)