消息队列基础
适合消息队列解决的问题
- 异步处理:处理完关键步骤后直接返回结果,后续放入队列慢慢处理
- 流量控制:
- 使用消息队列隔离网关和后端服务,以达到流量控制和保护后端服务的目的。能根据下游的处理能力自动调节流量,达到“削峰填谷”的作用
- 网关在收到请求后,将请求放入请求消息队列;
- 后端服务从请求消息队列中获取 APP 请求,完成后续秒杀处理过程,然后返回结果。
- 用消息队列实现一个令牌桶,更简单地进行流量控制。
- 原理:单位时间内只发放固定数量的令牌到令牌桶中,规定服务在处理请求之前必须先从令牌桶中拿出一个令牌,如果令牌桶中没有令牌,则拒绝请求。这样就保证单位时间内,能处理的请求不超过发放令牌的数量,起到了流量控制的作用。
- 实现:只要网关在处理 APP 请求时增加一个获取令牌的逻辑。
- 使用消息队列隔离网关和后端服务,以达到流量控制和保护后端服务的目的。能根据下游的处理能力自动调节流量,达到“削峰填谷”的作用
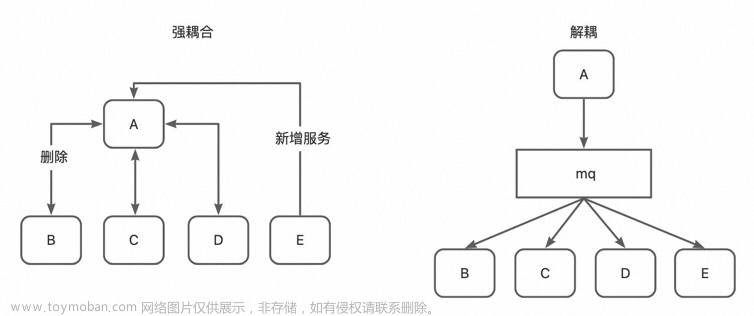
- 服务解耦
网关如何接收服务端的秒杀结果
处理 APP 请求的线程
- 网关在收到 APP 的秒杀请求后,直接给消息队列发消息。消息的内容只要包含足够的字段就行了,比如用户 ID、设备 ID、请求时间等等。另外,还需要包含这个请求的 ID 和网关的 ID。
- 如果发送消息失败,可以直接给 APP 返回秒杀失败结果,成功发送消息之后,线程就阻塞等待秒杀结果,设定一个等待的超时时间。
- 等待结束之后,去存放秒杀结果的 Map 中查询是否有返回的秒杀结果,如果有就构建 Response,给 APP 返回秒杀结果,如果没有,按秒杀失败处理。
网关如何来接收从后端秒杀服务返回的秒杀结果。
- 选择用 RPC 的方式来返回秒杀结果,这里网关节点是 RPC 服务端,后端服务为客户端。之前网关发出去的消息中包含了网关的 ID,后端服务可以通过这个网关 ID 来找到对应的网关实例,秒杀结果中需要包含请求 ID,这个请求 ID 也是从消息中获取的。、
- 网关收到后端服务的秒杀结果之后,用请求 ID 为 Key,结果保存到秒杀结果的 Map 中,然后通知对应的处理 APP 请求的线程,结束等待。处理 APP 请求的线程,在结束等待之后,会去秒杀的结果 Map 中查询这个结果,然后再给 APP 返回响应。
如何选择消息队列
- 选择标准
- 开源产品、社区活跃
- 消息的可靠传递:确保不丢消息;
- Cluster:支持集群,确保不会因为某个节点宕机导致服务不可用,当然也不能丢消息;
- 性能:具备足够好的性能,能满足绝大多数场景的性能要求。
- 消息队列产品
- RabbitMQ
- RocketMQ
- Kafka
消息模型:主题和队列有什么区别?
- 队列:生产者,消费者,存放消息的容器称为队列
- 主题:发布者,订阅者,服务端存放消息的容器称为主题。订阅者先订阅主题
rabbitMq
- 使用队列解决多个消费者问题
- Exchange 位于生产者和队列之间,生产者将消息发送给 Exchange,由 Exchange 上配置的策略来决定将消息投递到哪些队列中。
- 同一份消息如果需要被多个消费者来消费,需要配置 Exchange 将消息发送到多个队列,每个队列中都存放一份完整的消息数据,可以为一个消费者提供消费服务。这也可以变相地实现新发布 - 订阅模型中,“一份消息数据可以被多个订阅者来多次消费”这样的功能。
RocketMQ和kafka
- 假设结构:主题MyTopic,为主题创建5个队列(Q1Q2Q3Q4Q5),分布在2个broker中(broker0,broker1),3 个生产者实例:Produer0,Produer1 和 Producer2。
- 3 个生产者不用对应,随便发。
- 每个消费组就是一份订阅,要消费主题 MyTopic 下,所有队列的全部消息。
- 注意:队列里的消息并不是消费掉就没有了,这里的“消费”,只是去队列里面读了消息,并没有删除,消费完这条消息还是在队列里面。
- 多个消费组在消费同一个主题时,消费组之间是互不影响的。
- 比如 2 个消费组:G0 和 G1。G0 消费了哪些消息,G1 是不知道的,G0 消费过的消息,G1 还可以消费。即使 G0 积压了很多消息,对 G1 来说也没有任何影响。
- 消费组的内部:在同一个消费组里面,每个队列只能被一个消费者实例占用。至于如何分配,这里面有很多策略。保证每个队列分配一个消费者就行了。
- 比如,可以让消费者 C0 消费 Q0,Q1 和 Q2,C1 消费 Q3 和 Q4,如果 C0 宕机了,会触发重新分配,这时候 C1 同时消费全部 5 个队列。
- 队列占用只是针对消费组内部来说的,对于其他的消费组来说是没有影响的。
- 比如队列 Q2 被消费组 G1 的消费者 C1 占用了,对于消费组 G2 来说,是完全没有影响的,G2 也可以分配它的消费者来占用和消费队列 Q2。
- 消费位置:每个消费组内部维护自己的一组消费位置,每个队列对应一个消费位置。消费位置在服务端保存,并且,消费位置和消费者是没有关系的。每个消费位置一般就是一个整数,记录这个消费组中,这个队列消费到哪个位置了,这个位置之前的消息都成功消费了,之后的消息都没有消费或者正在消费。
实现单个队列的并行消费?
比如说,队列中当前有 10 条消息,对应的编号是 0-9,当前的消费位置是 5。同时来了三个消费者来拉消息,把编号为 5、6、7 的消息分别给三个消费者,每人一条。过了一段时间,三个消费成功的响应都回来了,这时候就可以把消费位置更新为 8 了,这样就实现并行消费。
编号为 6、7 的消息响应回来了,编号 5 的消息响应一直回不来,怎么办?
这个位置 5 就是一个消息空洞。为了避免位置 5 把这个队列卡住,可以先把消费位置 5 这条消息,复制到一个特殊重试队列中,然后依然把消费位置更新为 8,继续消费。再有消费者来拉消息的时候,优先把重试队列中的那条消息给消费者就可以了。
这是并行消费的一种实现方式。需要注意的是,并行消费开销还是很大的,不应该作为一个常规的,提升消费并发的手段,如果消费慢需要增加消费者的并发数,还是需要扩容队列数。
保证消息的严格顺序
主题层面是无法保证严格顺序的,只有在队列上才能保证消息的严格顺序。
-
如果业务必须要求全局严格顺序,就只能把消息队列数配置成 1,生产者和消费者也只能是一个实例,这样才能保证全局严格顺序。
-
大部分情况下只要保证局部有序就可以满足要求了。比如,在传递账户流水记录的时候,只要保证每个账户的流水有序就可以了,不同账户之间的流水记录是不需要保证顺序的。
- 保证局部严格顺序实现。在发送端,使用账户 ID 作为 Key,采用一致性哈希算法计算出队列编号,指定队列来发送消息。一致性哈希算法可以保证,相同 Key 的消息总是发送到同一个队列上,这样可以保证相同 Key 的消息是严格有序的。如果不考虑队列扩容,也可以用队列数量取模的简单方法来计算队列编号。
利用事务消息实现分布式事务
引
消息队列中的“事务”,主要解决的是消息生产者和消息消费者的数据一致性问题。
例:订单系统,购物车系统订阅主题,接收订单创建的消息,清理购物车,删除购物车的商品。
可能的异常:
- 创建了订单,没有清理购物车
- 订单没有创建成功,购物车里面的 商品被清理掉了
要保证订单库和购物车库这两个库的数据一致性。
问题的关键点集中在订单系统,创建订单和发送消息这两个步骤要么都操作成功,要么都操作失败,不允许一个成功而另一个失败的情况出现。
分布式事务
常见的分布式事务实现有 2PC(Two-phase Commit,也叫二阶段提交)、TCC(Try-Confirm-Cancel) 和事务消息。每一种实现都有其特定的使用场景,也有各自的问题,都不是完美的解决方案。
消息队列是如何实现分布式事务的?
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JAtvDcUH-1692190252202)(C:\Users\308158\AppData\Roaming\Typora\typora-user-images\image-20230808102403197.png)]
-
订单系统在消息队列上开启一个事务。
-
订单系统给消息服务器发送一个“半消息”(包含的内容就是完整的消息内容,但在事务提交之前,对于消费者来说,这个消息是不可见的。)
-
半消息发送成功后,订单系统就可以执行本地事务了,在订单库中创建一条订单记录,并提交订单库的数据库事务。
- 如果订单创建成功,那就提交事务消息,购物车系统就可以消费到这条消息继续后续的流程。
- 如果订单创建失败,那就回滚事务消息,购物车系统就不会收到这条消息。
-
有一个问题是没有解决的。如果在第四步提交事务消息时失败了怎么办?
- Kafka 的解决方案比较简单粗暴,直接抛出异常,让用户自行处理。可以在业务代码中反复重试提交,直到提交成功,或者删除之前创建的订单进行补偿。
- RocketMQ :增加了事务反查的机制来解决事务消息提交失败的问题。如果 Producer 也就是订单系统,在提交或者回滚事务消息时发生网络异常,RocketMQ 的 Broker 没有收到提交或者回滚的请求,Broker 会定期去 Producer 上反查这个事务对应的本地事务的状态,然后根据反查结果决定提交或者回滚这个事务。
如何确保消息不会丢失
- 利用消息队列的有序性来验证是否有消息丢失
- 在 Producer 端,给每个发出的消息附加一个连续递增的序号,然后在 Consumer 端来检查这个序号的连续性。
- 大多数消息队列的客户端都支持拦截器机制,利用拦截器机制,在 Producer 发送消息之前的拦截器中将序号注入到消息中,在 Consumer 收到消息的拦截器中检测序号的连续性。消息检测的代码不会侵入业务代码中,待系统稳定后,也方便将这部分检测的逻辑关闭或者删除。
- 在分布式系统中实现这个检测方法
- Kafka 和 RocketMQ 不保证在 Topic 上的严格顺序的,只能保证分区上的消息是有序的,在发消息时必须要指定分区,并在每个分区单独检测消息序号的连续性。
- Producer 如果是多实例的,由于并不好协调多个 Producer 之间的发送顺序,所以也需要每个 Producer 分别生成各自的消息序号,并且需要附加上 Producer 的标识,在 Consumer 端按照每个 Producer 分别来检测序号的连续性。
- Consumer 实例的数量最好和分区数量一致,做到 Consumer 和分区一一对应,方便在 Consumer 内检测消息序号的连续性。
- 确保消息可靠传递
- 丢失
-
生产阶段: 从消息在 Producer 创建出来,经过网络传输发送到 Broker 端。
- 正确处理返回值或者捕获异常,就可以保证这个阶段的消息不会丢失
- 同步发送,捕获异常
- 异步发送,在回调方法里进行检查
- 正确处理返回值或者捕获异常,就可以保证这个阶段的消息不会丢失
-
存储阶段: 消息在 Broker 端存储,如果是集群,消息会在这个阶段被复制到其他的副本上。
- 如果 Broker 出现了故障,比如进程死掉了或者服务器宕机了,还是可能会丢失消息的。
- 对于单个节点的 Broker,需要配置 Broker 参数,在收到消息后,将消息写入磁盘后再给 Producer 返回确认响应,这样即使发生宕机,由于消息已经被写入磁盘,就不会丢失消息,恢复后还可以继续消费。
- 如果是 Broker 是由多个节点组成的集群,需要将 Broker 集群配置成:至少将消息发送到 2 个以上的节点,再给客户端回复发送确认响应。这样当某个 Broker 宕机时,其他的 Broker 可以替代宕机的 Broker,也不会发生消息丢失
- 如果 Broker 出现了故障,比如进程死掉了或者服务器宕机了,还是可能会丢失消息的。
-
消费阶段: Consumer 从 Broker 上拉取消息,经过网络传输发送到 Consumer 上。
- 不要在收到消息后就立即发送消费确认,而是在执行完所有消费业务逻辑之后,再发送消费确认。
- 你可以看到,在消费的回调方法 callback 中,正确的顺序是,先是把消息保存到数据库中,然后再发送消费确认响应。这样如果保存消息到数据库失败了,就不会执行消费确认的代码,下次拉到的还是这条消息,直到消费成功。
- 不要在收到消息后就立即发送消费确认,而是在执行完所有消费业务逻辑之后,再发送消费确认。
-
生产阶段: 从消息在 Producer 创建出来,经过网络传输发送到 Broker 端。
- 丢失
处理消费过程中的重复消息?
- 消息重复情况
- At most once: 至多一次。消息在传递时,最多会被送达一次。换一个说法就是,没什么消息可靠性保证,允许丢消息。一般都是一些对消息可靠性要求不太高的监控场景使用,比如每分钟上报一次机房温度数据,可以接受数据少量丢失。
- At least once: 至少一次。消息在传递时,至少会被送达一次。也就是说,不允许丢消息,但是允许有少量重复消息出现。
- Exactly once:恰好一次。消息在传递时,只会被送达一次,不允许丢失也不允许重复,这个是最高的等级。
- 幂等性解决重复消息问题
- 在消费端,让消费消息的操作具备幂等性。
- 从业务逻辑设计上入手,将消费的业务逻辑设计成具备幂等性的操作。
- 利用数据库的唯一约束实现幂等
- 例如:对于同一个转账单同一个账户只能插入一条记录,后续重复的插入操作都会失败,这样就实现了一个幂等的操作。
- 为更新的数据设置前置条件
- 例如:给数据增加一个版本号属性,每次更数据前,比较当前数据的版本号是否和消息中的版本号一致,如果不一致就拒绝更新数据,更新数据的同时将版本号 +1,一样可以实现幂等更新。
- 记录并检查操作
- 在执行数据更新操作之前,先检查一下是否执行过这个更新操作。
- 在发送消息时,给每条消息指定一个全局唯一的 ID,消费时,先根据这个 ID 检查这条消息是否有被消费过,如果没有消费过,才更新数据,然后将消费状态置为已消费。
- 利用数据库的唯一约束实现幂等
处理消息积压
消息积压的直接原因:系统中的某个部分出现了性能问题,来不及处理上游发送的消息,才会导致消息积压。
- 优化性能避免消息积压
- 发送端性能优化
- 如果代码发送消息的性能上不去,需要优先检查是不是发消息之前的业务逻辑耗时太多导致的。
- 只需要注意设置合适的并发和批量大小,就可以达到很好的发送性能。
- 消费端性能优化
- 如果消费的速度跟不上发送端生产消息的速度,就会造成消息积压。
- 设计系统时,一定要保证消费端的消费性能要高于生产端的发送性能
- 消费端的性能优化除了优化消费业务逻辑以外,也可以通过水平扩容,增加消费端的并发数来提升总体的消费性能。注意:在扩容 Consumer 的实例数量的同时,必须同步扩容主题中的分区(也叫队列)数量,确保 Consumer 的实例数和分区数量是相等的。如果 Consumer 的实例数量超过分区数量,这样的扩容实际上是没有效果的
- 发送端性能优化
- 处理消息积压
- 某一个时刻,突然就开始积压消息并且积压持续上涨。这种情况下需要你在短时间内找到消息积压的原因,迅速解决问题才不至于影响业务。
- 能导致积压突然增加,最粗粒度的原因:要么是发送变快了,要么是消费变慢了。
- 如果是单位时间发送的消息增多,比如赶上大促或者抢购,短时间内不太可能优化消费端的代码来提升消费性能,唯一的方法是通过扩容消费端的实例数来提升总体的消费能力。
- 如果短时间内没有足够的服务器资源进行扩容,将系统降级,通过关闭一些不重要的业务,减少发送方发送的数据量,最低限度让系统还能正常运转,服务一些重要业务。
- 或者,无论是发送消息的速度还是消费消息的速度和原来都没什么变化,需要检查一下消费端,是不是消费失败导致的一条消息反复消费这种情况比较多,这种情况也会拖慢整个系统的消费速度。
- 监控到消费变慢了,需要检查消费实例,分析一下是什么原因导致消费变慢。优先检查日志是否有大量的消费错误,如果没有错误,可以通过打印堆栈信息,看一下消费线程是不是卡在什么地方不动了,比如触发了死锁或者卡在等待某些资源上了。
- 某一个时刻,突然就开始积压消息并且积压持续上涨。这种情况下需要你在短时间内找到消息积压的原因,迅速解决问题才不至于影响业务。
使用异步设计提升系统性能
异步模式设计的程序可以显著减少线程等待,从而在高吞吐量的场景中,极大提升系统的整体性能,显著降低时延。
异步设计提升系统性能
-
同步实现的性能瓶颈
- 每处理一个请求需要耗时 100ms,并在这 100ms 过程中是需要独占一个线程,
- 结论:每个线程每秒钟最多可以处理 10 个请求。每台计算机上的线程资源并不是无限的,假设使用的服务器同时打开的线程数量上限是 10,000,可以计算出这台服务器每秒钟可以处理的请求上限是: 10,000 (个线程)* 10(次请求每秒) = 100,000 次每秒。
- 如果请求速度超过这个值,那么请求就不能被马上处理,只能阻塞或者排队,服务的响应时延由 100ms 延长到了:排队的等待时延 + 处理时延 (100ms)。即在大量请求的情况下,微服务的平均响应时延变长了。
- 采用同步实现的方式,整个服务器的所有线程大部分时间都没有在工作,而是都在等待。
- 每处理一个请求需要耗时 100ms,并在这 100ms 过程中是需要独占一个线程,
-
采用异步实现解决等待问题
- 方法增加参数,一个回调方法。区别只是在线程模型上由同步顺序调用改为了异步调用和回调的机制。
- 性能分析:
- 低请求数量的场景下,平均响应时延一样是 100ms。
- 超高请求数量场景下,异步的实现不再需要线程等待执行结果,只需要个位数量的线程,即可实现同步场景大量线程一样的吞吐量。
- 由于没有了线程的数量的限制,总体吞吐量上限会大大超过同步实现,并且在服务器 CPU、网络带宽资源达到极限之前,响应时延不会随着请求数量增加而显著升高,几乎可以一直保持约 100ms 的平均响应时延。
简单实用的异步框架: CompletableFuture
CompletableFuture add(int account, int amount);
接口中定义的方法的返回类型都是一个带泛型的 CompletableFeture,尖括号中的泛型类型就是真正方法需要返回数据的类型,我们这两个服务不需要返回数据,所以直接用 Void 类型就可以。
return accountService.add(fromAccount, -1 * amount).thenCompose(v -> accountService.add(toAccount, amount)); 实现异步依次调用两次账户服务完整转账。
调用异步方法获得返回值 CompletableFuture 对象后,既可以调用 CompletableFuture 的 get 方法,像调用同步方法那样等待调用的方法执行结束并获得返回值,也可以像异步回调的方式一样,调用 CompletableFuture 那些以 then 开头的一系列方法,为 CompletableFuture 定义异步方法结束之后的后续操作。
实现高性能的异步网络传输
同步模型和异步模型
- 同步模型会阻塞线程等待资源
- 异步模型不会阻塞线程,它是等资源准备好后,再通知业务代码来完成后续的资源处理逻辑。可以很好的解决IO 等待的问题.
IO 密集型和计算密集型
- IO 密集型系统大部分时间都在执行 IO 操作(包括网络 IO 和磁盘 IO,以及与计算机连接的一些外围设备的访问)。适合使用异步的设计来提升系统性能
- 计算密集型系统,大部分时间都是在使用 CPU 执行计算操作。业务系统,很少有非常耗时的计算,更多的是网络收发数据,读写磁盘和数据库这些 IO 操作。
理想的异步网络框架
- 要实现通过网络来传输数据,需要用到开发语言提供的网络通信类库。一个 TCP 连接建立后,用户代码会获得一个用于收发数据的通道。每个通道会在内存中开辟两片区域用于收发数据的缓存。
- 发送数据:直接往这个通道里面来写入数据就可以了。用户代码在发送时写入的数据会暂存在缓存中,然后操作系统会通过网卡,把发送缓存中的数据传输到对端的服务器上。发送数据的时候同步发送就可以了,没有必要异步。
- 接收数据:当有数据到来的时候,操作系统会先把数据写入接收缓存,然后给接收数据的线程发一个通知,线程收到通知后结束等待,开始读取数据。处理完这一批数据后,继续阻塞等待下一批数据到来,这样周而复始地处理收到的数据。
同步网络 IO 的模型。同步网络 IO 模型在处理少量连接的时候,是没有问题的。但是如果要同时处理非常多的连接,同步的网络 IO 模型就有点儿力不从心了。每个连接都需要阻塞一个线程来等待数据,大量的连接数就会需要相同数量的数据接收线程。当这些 TCP 连接都在进行数据收发的时候,会有大量的线程来抢占 CPU 时间,造成频繁的 CPU 上下文切换,导致 CPU 的负载升高,整个系统的性能就会比较慢。
理想的异步框架:只用少量的线程就能处理大量的连接,有数据到来的时候能第一时间处理就可以了。事先定义好收到数据后的处理逻辑,把这个处理逻辑作为一个回调方法,在连接建立前就通过框架提供的 API 设置好。当收到数据的时候,由框架自动来执行这个回调方法就好了。
使用Netty实现异步网络通信
逻辑功能
- 创建了一个 EventLoopGroup 对象,命名为 group(可以理解为一组线程。作用是来执行收发数据的业务逻辑)
- 使用 Netty 提供的 ServerBootstrap 来初始化一个 Socket Server,绑定到本地 9999 端口上。
- 在真正启动服务之前,给 serverBootstrap 传入了一个 MyHandler 对象(自己实现的一个类,需要继承 Netty 提供的一个抽象类:ChannelInboundHandlerAdapter, MyHandler 里面定义收到数据后的处理逻辑)这个设置 Handler 的过程就是预先来定义回调方法的过程。
- 最后就可以真正绑定本地端口,启动 Socket 服务了。
服务启动后,如果有客户端来请求连接,Netty 会自动接受并创建一个 Socket 连接。
收到来自客户端的数据后,Netty 就会在 EventLoopGroup 对象中,获取一个 IO 线程,并调用接收数据的回调方法,来执行接收数据的业务逻辑(MyHandler方法)。
真正需要业务代码来实现的就两个部分:一个是把服务初始化并启动起来,另一个是实现收发消息的业务逻辑 MyHandler。
Netty 维护一组线程来执行数据收发的业务逻辑。如果业务需要更灵活的实现,自己来维护收发数据的线程,可以选择更加底层的 Java NIO
使用NIO实现异步网络通信
提供了一个 Selector 对象,来解决一个线程在多个网络连接上的多路复用问题。
在 NIO 中,每个已经建立好的连接用一个 Channel 对象来表示。希望能实现,在一个线程里,接收来自多个 Channel 的数据。
一个线程对应多个 Channel,有可能会出现这两种情况:
- 线程在忙着处理收到的数据,这时候 Channel 中又收到了新数据;
- 线程闲着没事儿干,所有的 Channel 中都没收到数据,也不能确定哪个 Channel 会在什么时候收到数据。
实现:Selecor 通过一种类似于事件的机制来解决这个问题。
- 首先把连接也就是 Channel 绑定到 Selector
- 在接收数据的线程来调用 Selector.select() 方法来等待数据到来。(一个阻塞方法,这个线程会一直卡在这儿,直到这些 Channel 中的任意一个有数据到来,就会结束等待返回数据。)它的返回值是一个迭代器,可以从这个迭代器里面获取所有 Channel 收到的数据,然后来执行数据接收的业务逻辑。
- 可以选择直接在这个线程里面来执行接收数据的业务逻辑,也可以将任务分发给其他的线程来执行
序列化与反序列化:通过网络传输结构化的数据
在 TCP 的连接上,它传输数据的基本形式就是二进制流
要想使用网络框架的 API 来传输结构化的数据,必须得先实现结构化的数据与字节流之间的双向转换。这种将结构化数据转换成字节流的过程,称为序列化,反过来转换,就是反序列化。
序列化实现权衡因素:
- 序列化后的数据最好是易于人类阅读的;
- 实现的复杂度是否足够低;
- 序列化和反序列化的速度越快越好;
- 序列化后的信息密度越大越好,即同样的一个结构化数据,序列化之后占用的存储空间越小越好;
实现高性能的序列化和反序列化
很多的消息队列都选择自己实现高性能的专用序列化和反序列化。
可以固定字段的顺序,这样在序列化后的字节里面就不必包含字段名,只要字段值就可以了,不同类型的数据也可以做针对性的优化
专用的序列化方法显然更高效,序列化出来的字节更少,在网络传输过程中的速度也更快。但缺点是,需要为每种对象类型定义专门的序列化和反序列化方法,实现起来太复杂了,大部分情况下是不划算的。
传输协议:应用程序之间对话的语言
- 断句:给每句话前面加一个表示这句话长度的数字,收到数据的时候,按照长度来读取就可以了。
- 单工通信:任何一个时刻,数据只能单向传输,一问一答。(HTTP1协议)
- 双工通信:可以同时进行数据的双向收发,互相是不会受到任何影响的。发送请求的时候,给每个请求加一个序号,这个序号在本次会话内保证唯一,然后在响应中带上请求的序号,只要需要确保请求和响应能够正确对应上就可以了
内存管理:避免内存溢出和频繁的垃圾回收
问题:一个业务逻辑非常简单的微服务,日常情况下都能稳定运行,一到大促就卡死甚至进程挂掉?一个做数据汇总的应用,按照小时、天这样的粒度进行数据汇总都没问题,到年底需要汇总全年数据的时候,没等数据汇总出来,程序就死掉了。
原因是,程序在设计的时候,没有针对高并发高吞吐量的情况做好内存管理
自动内存管理机制的实现原理
- 申请内存
- 计算要创建对象所需要占用的内存大小;
- 在内存中找一块儿连续并且是空闲的内存空间,标记为已占用;
- 把申请的内存地址绑定到对象的引用上,这时候对象就可以使用了。
- 内存回收
- 要找出所有可以回收的对象,将对应的内存标记为空闲
- GC算法:
- 标记清除
- 标记阶段:从 GC Root 开始(程序入口的那个对象),标记所有可达的对象,因为程序中所有在用的对象一定都会被这个 GC Root 对象直接或者间接引用。
- 清除阶段:遍历所有对象,找出所有没有标记的对象。这些没有标记的对象都是可以被回收的,清除这些对象,释放对应的内存即可。
- 问题:在执行标记和清除过程中,必须把进程暂停,否则计算的结果就是不准确的,即为什么垃圾回收时,我们的程序会被卡死。
- 标记清除
- GC算法:
- 整理内存碎片。
- 将不连续的空闲内存移动到一起,以便空出足够的连续内存空间供后续使用。
- 要找出所有可以回收的对象,将对应的内存标记为空闲
为什么在高并发下程序会卡死
微服务在收到一个请求后,执行一段业务逻辑,然后返回响应。这个过程中,会创建一些对象,比如说请求对象、响应对象和处理中间业务逻辑中需要使用的一些对象等等。随着这个请求响应的处理流程结束,创建的这些对象也就都没有用了,它们将会在下一次垃圾回收过程中被释放。直到下一次垃圾回收之前,这些已经没有用的对象会一直占用内存。
高并发的情况下,程序会非常繁忙,短时间内就会创建大量的对象,这些对象将会迅速占满内存,这时候,由于没有内存可以使用了,垃圾回收被迫开始启动,并且,这次被迫执行的垃圾回收面临的是占满整个内存的海量对象,它执行的时间也会比较长,相应的,这个回收过程会导致进程长时间暂停。
进程长时间暂停,又会导致大量的请求积压等待处理,垃圾回收刚刚结束,更多的请求立刻涌进来,迅速占满内存,再次被迫执行垃圾回收,进入了一个恶性循环。如果垃圾回收的速度跟不上创建对象的速度,还可能会产生内存溢出的现象。
高并发下的内存管理技巧
只有使用过被丢弃的对象才是垃圾回收的目标,所以,在处理大量请求的同时,尽量少的产生这种一次性对象。
最有效的方法就是,优化代码中处理请求的业务逻辑,尽量少的创建一次性对象,特别是占用内存较大的对象。比如说,可以把收到请求的 Request 对象在业务流程中一直传递下去,而不是每执行一个步骤,就创建一个内容和 Request 对象差不多的新对象。
对于需要频繁使用,占用内存较大的一次性对象,可以考虑自行回收并重用这些对象。实现:可以为这些对象建立一个对象池。收到请求后,在对象池内申请一个对象,使用完后再放回到对象池中,这样就可以反复地重用这些对象,非常有效地避免频繁触发垃圾回收。
使用更大内存的服务器,也可以非常有效地缓解这个问题。
Kafka如何实现高性能IO?
使用批量消息提升服务端处理能力
Kafka 内部,消息都是以“批”为单位处理的。一批消息从发送端到接收端
- 发送端:Kafka 的客户端 SDK 在实现消息发送逻辑的时候,采用了异步批量发送的机制。调用 send() 方法发送一条消息之后,无论是同步发送还是异步发送,Kafka 都不会立即就把这条消息发送出去。它会先把这条消息,存放在内存中缓存起来,然后选择合适的时机把缓存中的所有消息组成一批,一次性发给 Broker。简单地说,就是攒一波一起发。
- Kafka 的服务端(Broker ):每批消息都会被当做一个“批消息”来处理。也就是说,在 Broker 整个处理流程中,无论是写入磁盘、从磁盘读出来、还是复制到其他副本这些流程中,批消息都不会被解开,一直是作为一条“批消息”来进行处理的。
- 消费时,消息同样是以批为单位进行传递的,Consumer 从 Broker 拉到一批消息后,在客户端把批消息解开,再一条一条交给用户代码处理。
使用顺序读写提升磁盘 IO 性能
操作系统每次从磁盘读写数据的时候,需要先寻址,先要找到数据在磁盘上的物理位置,然后再进行数据读写。如果是机械硬盘,这个寻址需要比较长的时间,因为它要移动磁头,这是个机械运动。
顺序读写相比随机读写省去了大部分的寻址时间,它只要寻址一次,就可以连续地读写下去,所以说,性能要比随机读写要好很多。
Kafka 充分利用了磁盘的这个特性。它的存储设计非常简单,对于每个分区,它把从 Producer 收到的消息,顺序地写入对应的 log 文件中,一个文件写满了,就开启一个新的文件这样顺序写下去。消费的时候,也是从某个全局的位置开始,也就是某一个 log 文件中的某个位置开始,顺序地把消息读出来。
利用 PageCache 加速消息读写
PageCache 就是操作系统在内存中给磁盘上的文件建立的缓存。调用系统的 API 读写文件的时候,并不会直接去读写磁盘上的文件,应用程序实际操作的都是 PageCache。
应用程序在
- 写入文件:操作系统会先把数据写入到内存中的 PageCache,然后再一批一批地写到磁盘上。
- 读取文件的时候,也是从 PageCache 中来读取数据
这时候会出现两种可能情况:
- PageCache 中有数据,那就直接读取,这样就节省了从磁盘上读取数据的时间;
- PageCache 中没有数据,操作系统会引发一个缺页中断,应用程序的读取线程会被阻塞,操作系统把数据从文件中复制到 PageCache 中,然后应用程序再从 PageCache 中继续把数据读出来,这时会真正读一次磁盘上的文件,这个读的过程就会比较慢。
用户的应用程序在使用完某块 PageCache 后,操作系统并不会立刻就清除这个 PageCache,而是尽可能地利用空闲的物理内存保存这些 PageCache,除非系统内存不够用,操作系统才会清理掉一部分 PageCache。清理的策略一般是 LRU 或它的变种算法,保留 PageCache 的逻辑是:优先保留最近一段时间最常使用的那些 PageCache。
Kafka 在读写消息文件的时候,充分利用了 PageCache 的特性。一般来说,消息刚刚写入到服务端就会被消费,按照 LRU 的“优先清除最近最少使用的页”这种策略,读取的时候,对于这种刚刚写入的 PageCache,命中的几率会非常高。
大部分情况下,消费读消息都会命中 PageCache,带来的好处有两个:一个是读取的速度会非常快,另外一个是,给写入消息让出磁盘的 IO 资源,间接也提升了写入的性能。
ZeroCopy:零拷贝技术
服务端,处理消费的大致逻辑是这样的:
- 首先,从文件中找到消息数据,读到内存中;
- 然后,把消息通过网络发给客户端。
这个过程中,数据实际上做了 2 次或者 3 次复制:
- 从文件复制数据到 PageCache 中,如果命中 PageCache,这一步可以省掉;
- 从 PageCache 复制到应用程序的内存空间中,也就是我们可以操作的对象所在的内存;
- 从应用程序的内存空间复制到 Socket 的缓冲区,这个过程就是我们调用网络应用框架的 API 发送数据的过程。
Kafka 使用零拷贝技术可以把这个复制次数减少一次,上面的 2、3 步骤两次复制合并成一次复制。直接从 PageCache 中把数据复制到 Socket 缓冲区中,这样不仅减少一次数据复制,更重要的是,由于不用把数据复制到用户内存空间,DMA 控制器可以直接完成数据复制,不需要 CPU 参与,速度更快。
#include <sys/socket.h>
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
前两个参数分别是目的端和源端的文件描述符,后面两个参数是源端的偏移量和复制数据的长度,返回值是实际复制数据的长度。
缓存策略:使用缓存来减少磁盘IO
磁盘是个持久化存储,即使服务器掉电也不会丢失数据,
磁盘致命问题:读写速度很慢
使用内存作为缓存来加速应用程序的访问速度,是几乎所有高性能系统都会采用的方法。
选择只读缓存还是读写缓存
读缓存还是读写缓存唯一的区别就是,在更新数据的时候,是否经过缓存。
在数据写到 PageCache 中后,它并不是同时就写到磁盘上了,这中间是有一个延迟的。操作系统可以保证,即使是应用程序意外退出了,操作系统也会把这部分数据同步到磁盘上。但是,如果服务器突然掉电了,这部分数据就丢失了。
读写缓存的这种设计,它天然就是不可靠的,是一种牺牲数据一致性换取性能的设计
为什么 Kafka 可以使用 PageCache 来提升它的性能呢?这是由消息队列的一些特点决定的。
保持缓存数据新鲜
尽量让缓存中的数据与磁盘上的数据保持同步。
- 可以使用分布式事务来解决,只是付出的性能、实现复杂度等代价比较大。
- 定时将磁盘上的数据同步到缓存中。(适用于对数据不敏感的场景)
- 每次同步时直接全量更新就可以了,因为是在异步的线程中更新数据,同步的速度即使慢一些也不是什么大问题。
- 如果缓存的数据太大,更新速度慢到无法接受,也可以选择增量更新,每次只更新从上次缓存同步至今这段时间内变化的数据,代价是实现起来会稍微有些复杂。
- 缺点是缓存更新不那么及时,优点是实现起来非常简单,鲁棒性非常好。
- 不去更新缓存中的数据,而是给缓存中的每条数据设置一个比较短的过期时间,数据过期以后即使它还存在缓存中,我们也认为它不再有效,需要从磁盘上再次加载这条数据,这样就变相地实现了数据更新。(适用于对数据不敏感的场景)
缓存置换策略
在内存有限的情况下,要优先缓存哪些数据,让缓存的命中率最高。
如果系统是可以预测未来访问哪些数据的系统,比如说,有的系统它会定期做数据同步,每次同步的数据范围都是一样的,像这样的系统,缓存策略很简单,就是你要访问什么数据,就缓存什么数据,甚至可以做到百分之百的命中。
缓存置换:一般会在数据首次被访问的时候,顺便把这条数据放到缓存中。随着访问的数据越来越多,总有把缓存占满的时刻,需要把缓存中的一些数据删除掉,以便存放新的数据。
删掉哪些数据?
- 命中率最高的置换策略,一定是根据你的业务逻辑,定制化的策略。
- 使用通用的置换算法。LRU 算法,最近最少使用算法。思想是,最近刚刚被访问的数据,它在将来被访问的可能性也很大,而很久都没被访问过的数据,未来再被访问的几率也不大。
综合考虑下的淘汰算法,不仅命中率更高,还能有效地避免“挖坟”问题:例如某个客户端正在从很旧的位置开始向后读取一批历史数据,内存中的缓存很快都会被替换成这些历史数据,相当于大部分缓存资源都被消耗掉了,这样会导致其他客户端的访问命中率下降。加入位置权重后,比较旧的页面会很快被淘汰掉,减少“挖坟”对系统的影响。
package com.evo;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
public class LRUCache<V> {
/**
* 容量
*/
private int capacity = 1024;
/**
* Node记录表
*/
private Map<String, ListNode<String, V>> table = new ConcurrentHashMap<>();
/**
* 双向链表头部
*/
private ListNode<String, V> head;
/**
* 双向链表尾部
*/
private ListNode<String, V> tail;
public LRUCache(int capacity) {
this();
this.capacity = capacity;
}
public LRUCache() {
head = new ListNode<>();
tail = new ListNode<>();
head.next = tail;
head.prev = null;
tail.prev = head;
tail.next = null;
}
public V get(String key) {
ListNode<String, V> node = table.get(key);
//如果Node不在表中,代表缓存中并没有
if (node == null) {
return null;
}
//如果存在,则需要移动Node节点到表头
//截断链表,node.prev -> node -> node.next ====> node.prev -> node.next
// node.prev <- node <- node.next ====> node.prev <- node.next
node.prev.next = node.next;
node.next.prev = node.prev;
//移动节点到表头
node.next = head.next;
head.next.prev = node;
node.prev = head;
head.next = node;
//存在缓存表
table.put(key, node);
return node.value;
}
public void put(String key, V value) {
ListNode<String, V> node = table.get(key);
//如果Node不在表中,代表缓存中并没有
if (node == null) {
if (table.size() == capacity) {
//超过容量了 ,首先移除尾部的节点
table.remove(tail.prev.key);
tail.prev = tail.next;
tail.next = null;
tail = tail.prev;
}
node = new ListNode<>();
node.key = key;
node.value = value;
table.put(key, node);
}
//如果存在,则需要移动Node节点到表头
node.next = head.next;
head.next.prev = node;
node.prev = head;
head.next = node;
}
/**
* 双向链表内部类
*/
public static class ListNode<K, V> {
private K key;
private V value;
ListNode<K, V> prev;
ListNode<K, V> next;
public ListNode(K key, V value) {
this.key = key;
this.value = value;
}
public ListNode() {
}
}
public static void main(String[] args) {
LRUCache<ListNode> cache = new LRUCache<>(4);
ListNode<String, Integer> node1 = new ListNode<>("key1", 1);
ListNode<String, Integer> node2 = new ListNode<>("key2", 2);
ListNode<String, Integer> node3 = new ListNode<>("key3", 3);
ListNode<String, Integer> node4 = new ListNode<>("key4", 4);
ListNode<String, Integer> node5 = new ListNode<>("key5", 5);
cache.put("key1", node1);
cache.put("key2", node2);
cache.put("key3", node3);
cache.put("key4", node4);
cache.get("key2");
cache.put("key5", node5);
cache.get("key2");
}
}
正确使用锁保护共享数据,协调异步线程?**
由于并发读写导致的数据错误。使用锁可以非常有效地解决这个问题。
锁的原理:任何时间都只能有一个线程持有锁,只有持有锁的线程才能访问被锁保护的资源。
避免滥用锁
如果能不用锁,就不用锁;如果你不确定是不是应该用锁,那也不要用锁
- 加锁和解锁过程都是需要 CPU 时间的,这是一个性能的损失。另外,使用锁就有可能导致线程等待锁,等待锁过程中线程是阻塞的状态,过多的锁等待会显著降低程序的性能。
- 如果对锁使用不当,很容易造成死锁,导致整个程序“卡死”,这是非常严重的问题。本来多线程的程序就非常难于调试,如果再加上锁,出现并发问题或者死锁问题,你的程序将更加难调试。
只有在并发环境中,共享资源不支持并发访问,或者说并发访问共享资源会导致系统错误的情况下,才需要使用锁。
锁的用法
- 在访问共享资源之前,先获取锁。
- 如果获取锁成功,就可以访问共享资源了。
- 最后,需要释放锁,以便其他线程继续访问共享资源。
避免死锁
死锁的原因
- 获取了锁之后没有释放
- 锁重入问题
- 在持有这把锁的情况下,再次去尝试获取这把锁
- 不一定。**会不会死锁取决于,你获取的这把锁它是不是可重入锁。**如果是可重入锁,那就没有问题,否则就会死锁。
- 在持有这把锁的情况下,再次去尝试获取这把锁
- 如果程序中存在多把锁,就有可能出现这些锁互相锁住的情况
使用
- 避免滥用锁
- 对于同一把锁,加锁和解锁必须要放在同一个方法中,这样一次加锁对应一次解锁,代码清晰简单,便于分析问题。
- 尽量避免在持有一把锁的情况下,去获取另外一把锁,就是要尽量避免同时持有多把锁。
- 如果需要持有多把锁,一定要注意加解锁的顺序,解锁的顺序要和加锁顺序相反。比如,获取三把锁的顺序是 A、B、C,释放锁的顺序必须是 C、B、A。
- 给程序中所有的锁排一个顺序,在所有需要加锁的地方,按照同样的顺序加解锁。比如我刚刚举的那个例子,如果两个线程都按照先获取 lockA 再获取 lockB 的顺序加锁,就不会产生死锁。
使用读写锁要兼顾性能和安全性
无论是只读访问,还是读写访问,都是需要加锁的。
- 读访问可以并发执行。
- 写的同时不能并发读,也不能并发写。
read() 方法是可以多个线程并行执行的,读数据的性能依然很好。
写数据的时候,获取写锁,当一个线程持有写锁的时候,其他线程既无法获取读锁,也不能获取写锁,达到保护共享数据的目的。
用硬件同步原语(CAS)替代锁
硬件同步原语
由计算机硬件提供的一组原子操作,比较常用的原语主要是 CAS 和 FAA 这两种。
cas
<< atomic >> function cas(p : pointer to int, old : int, new : int) returns bool { if *p ≠ old { return false } *p ← new return true }
输入参数一共有三个,分别是:
- p: 要修改的变量的指针。
- old: 旧值。
- new: 新值。
返回的是一个布尔值,标识是否赋值成功。
逻辑:先比较一下变量 p 当前的值是不是等于 old,如果等于就把变量 p 赋值为 new,并返回 true,否则就不改变变量 p,并返回 false。
FAA
<< atomic >> function faa(p : pointer to int, inc : int) returns int { int value <- *location *p <- value + inc return value }
语义是:先获取变量 p 当前的值 value,然后给变量 p 增加 inc,最后返回变量 p 之前的值 value。
某些情况下,原语可以用来替代锁,实现一些即安全又高效的并发操作。
数据压缩:时间换空间的游戏
什么情况适合使用数据压缩?
比如,进程之间通过网络传输数据
- 不压缩直接传输需要的时间是:传输未压缩数据的耗时
- 使用数据压缩需要的时间是:压缩耗时+传输压缩数据耗时+解压耗时
影响因素非常多:数据的压缩率、网络带宽、收发两端服务器的繁忙程度等等。
压缩和解压的操作都是计算密集型的操作,非常耗费 CPU 资源。
- 如果处理业务逻辑就需要耗费大量的 CPU 资源,就不太适合再进行压缩和解压。
- 如果系统的瓶颈是磁盘的 IO 性能,CPU 资源又很闲,非常适合在把数据写入磁盘前先进行压缩。
- 如果系统读写比严重不均衡,还要考虑,每读一次数据就要解压一次是不是划算。
压缩它的本质是资源的置换,是一个时间换空间,或者说是 CPU 资源换存储资源的游戏。
应该选择什么压缩算法?
有损压缩和无损压缩。
- 有损压缩主要是用来压缩音视频,它压缩之后是会丢失信息的。
- 无损压缩,数据经过压缩和解压过程之后,与压缩之前相比,是 100% 相同的。
目前常用的压缩算法包括:ZIP,GZIP,SNAPPY,LZ4 等等。考虑数据的压缩率和压缩耗时。一般来说,压缩率越高的算法,压缩耗时也越高。
- 如果是对性能要求高的系统,可以选择压缩速度快的算法,比如 LZ4;
- 如果需要更高的压缩比,可以考虑 GZIP 或者压缩率更高的 XZ 等算法。
压缩样本对压缩速度和压缩比的影响也是比较大的,同样大小的一段数字和一段新闻的文本,即使是使用相同的压缩算法,压缩率和压缩时间的差异也是比较大的。所以,有的时候在选择压缩算法的之前,用系统的样例业务数据做一个测试,可以帮助你找到最合适的压缩算法。
如何选择合适的压缩分段?
大部分的压缩算法,区别主要是,对数据进行编码的算法,压缩的流程和压缩包的结构大致一样的。而在压缩过程中,最需要了解的就是如何选择合适的压缩分段大小。
压缩时,给定的被压缩数据它必须有确定的长度,是有头有尾的,不能是一个无限的数据流,如果要对流数据进行压缩,那必须把流数据划分成多个帧,一帧一帧的分段压缩。
原因:压缩算法在开始压缩之前,一般都需要对被压缩数据从头到尾进行一次扫描(目的是确定如何对数据进行划分和编码,一般的原则是重复次数多、占用空间大的内容,使用尽量短的编码,这样压缩率会更高。)
被压缩的数据长度越大,重码率会更高,压缩比也就越高。
分段也不是越大越好
- 实际上分段大小超过一定长度之后,再增加长度对压缩率的贡献就不太大了。
- 过大的分段长度,在解压缩的时候,会有更多的解压浪费。比如,一个 1MB 大小的压缩文件,即使你只是需要读其中很短的几个字节,也不得不把整个文件全部解压缩,造成很大的解压浪费。
根据业务,选择合适的压缩分段,在压缩率、压缩速度和解压浪费之间找到一个合适的平衡。
- 压缩:确定如何对数据进行划分和压缩算法后进行压缩,压缩的过程就是用编码来替换原始数据的过程。压缩之后的压缩包就是由这个编码字典和用编码替换之后的数据组成的。
- 解压:先读取编码字典,然后按照字典把压缩编码还原成原始的数据就可以了。
Kafka 是如何处理消息压缩的?
- Kafka 可以配置是否开启压缩,也支持配置使用哪一种压缩算法。原因:不同的业务场景是否需要开启压缩,选择哪种压缩算法是不能一概而论的。
- 在开启压缩时,Kafka 选择一批消息一起压缩,每一个批消息就是一个压缩分段。使用者也可以通过参数来控制每批消息的大小。可以整批直接存储,然后整批发送给消费者。最后,批消息由消费者进行解压。在服务端不用解压,就不会耗费服务端宝贵的 CPU 资源,同时还能获得压缩后,占用传输带宽小,占用存储空间小的这些好处,这是一个非常聪明的设计。
- 在使用 Kafka 时,如果生产者和消费者的 CPU 资源不是特别吃紧,开启压缩后,可以节省网络带宽和服务端的存储空间,提升总体的吞吐量。
Kafka Consumer源码分析:消息消费的实现过程**
收发消息两个过程
kafka消费模型
- Kafka 的每个 Consumer(消费者)实例属于一个 ConsumerGroup(消费组);
- 在消费时,ConsumerGroup 中的每个 Consumer 独占一个或多个 Partition(分区);
- 对于每个 ConsumerGroup,在任意时刻,每个 Partition 至多有 1 个 Consumer 在消费;
- 每个 ConsumerGroup 都有一个 Coordinator(协调者)负责分配 Consumer 和 Partition 的对应关系,当 Partition 或是 Consumer 发生变更是,会触发 reblance(重新分配)过程,重新分配 Consumer 与 Partition 的对应关系;
- Consumer 维护与 Coordinator 之间的心跳,这样 Coordinator 就能感知到 Consumer 的状态,在 Consumer 故障的时候及时触发 rebalance。
Kafka 的 Consumer 入口类
// 设置必要的配置信息
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// 创建 Consumer 实例
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// 订阅 Topic
consumer.subscribe(Arrays.asList("foo", "bar"));
// 循环拉消息
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
流程:订阅 + 拉取消息
- 设置必要的配置信息,包括:起始连接的 Broker 地址,Consumer Group 的 ID,自动提交消费位置的配置和序列化配置;
- 创建 Consumer 实例;
- 订阅了 2 个 Topic:foo 和 bar;
- 循环拉取消息并打印在控制台上。
Kafka 在消费过程中,每个 Consumer 实例是绑定到一个分区上的,那 Consumer 是如何确定,绑定到哪一个分区上的呢?这个问题也是可以通过分析消费流程来找到答案的。
订阅过程实现
public void subscribe(Collection<String> topics, ConsumerRebalanceListener listener) {
acquireAndEnsureOpen();
try {
// 省略部分代码
// 重置订阅状态
this.subscriptions.subscribe(new HashSet<>(topics), listener);
// 更新元数据
metadata.setTopics(subscriptions.groupSubscription());
} finally {
release();
}
}
订阅的主流程主要更新了两个属性:
- 订阅状态 subscriptions,
- 更新元数据中的 topic 信息。订阅状态 subscriptions 主要维护了订阅的 topic 和 patition 的消费位置等状态信息。属性 metadata 中维护了 Kafka 集群元数据的一个子集,包括集群的 Broker 节点、Topic 和 Partition 在节点上分布,以及我们聚焦的第二个问题:Coordinator 给 Consumer 分配的 Partition 信息。
在订阅的实现过程中,Kafka 更新了订阅状态 subscriptions 和元数据 metadata 中的相关 topic 的一些属性,将元数据状态置为“需要立即更新”,但是并没有真正发送更新元数据的请求,整个过程没有和集群有任何网络数据交换
拉取消息过程实现
- 消费者拉消息:poll
- updateAssignmentMetadataIfNeeded(): 更新元数据:,实现了与 Cluster 通信,在 Coordinator 上注册 Consumer 并拉取和更新元数据。
- pollForFetches():拉取消息。
- 如果缓存里面有未读取的消息,直接返回这些消息;
- 构造拉取消息请求,并发送;
- 发送网络请求并拉取消息,等待直到有消息返回或者超时;
- 返回拉到的消息。
消息复制
面临问题
- 性能:
- 需要写入的节点数量越多,可用性和数据可靠性就越好,但是写入性能就越低
- 不管采用哪种复制方式,消费消息的时候,都只是选择多副本中一个节点去读数据而已,这和单节点消费并没有差别。
- 一致性:
- 不丢消息,严格顺序
- 主 - 从”的复制方式
- 高可用:
- 当某个主节点宕机的时候,尽快再选出一个主节点来接替宕机的主节点。
- 比较快速的实现:使用一个第三方的管理服务来管理这些节点,发现某个主节点宕机的时候,由管理服务来指定一个新的主节点
- 消息队列选择自选举:由还存活的这些节点通过投票,来选出一个新的主节点,这种投票的实现方式,优点是没有外部依赖,可以实现自我管理。缺点就是投票的实现都比较复杂,
kafka实现复制
- Kafka 中,复制的基本单位是分区。每个分区的几个副本之间,构成一个小的复制集群,Broker 是这些分区副本的容器,所以 Kafka 的 Broker 是不分主从的。
- 分区的多个副本中也是采用一主多从的方式。Kafka 在写入消息的时候,采用的也是异步复制的方式。消息在写入到主节点之后,并不会马上返回写入成功,而是等待足够多的节点都复制成功后再返回。
- ISR(In Sync Replicas),:“保持数据同步的副本”。ISR 的数量是可配的,注意: ISR 中是包含主节点的。
- Kafka 使用 ZooKeeper 来监控每个分区的多个节点,如果发现某个分区的主节点宕机了,Kafka 会利用 ZooKeeper 来选出一个新的主节点,这样解决了可用性的问题。ZooKeeper 是一个分布式协调服务,选举的时候,会从所有 ISR 节点中来选新的主节点,这样可以保证数据一致性。
- 默认情况下,如果所有的 ISR 节点都宕机了,分区就无法提供服务了。也可以选择配置成让分区继续提供服务,这样只要有一个节点还活着,就可以提供服务,代价是无法保证数据一致性,会丢消息。
Kafka的协调服务ZooKeeper:实现分布式系统的“瑞士军刀”
ZooKeeper 的作用
- 集群选举:ZooKeeper 分布式的协调服务框架,主要用来解决分布式集群中,应用系统需要面对的各种通用的一致性问题。ZooKeeper 本身可以部署为一个集群,集群的各个节点之间可以通过选举来产生一个 Leader,选举遵循半数以上的原则,所以一般集群需要部署奇数个节点。
- ZooKeeper 最核心的功能:提供了一个分布式的存储系统,数据的组织方式类似于 UNIX 文件系统的树形结构。分布式系统中一些需要整个集群所有节点都访问的元数据,比如集群节点信息、公共配置信息等,特别适合保存在 ZooKeeper 中。
- znode:在这个树形的存储结构中,每个节点被称为一个“ZNode”。ZooKeeper 提供了一种特殊的 ZNode 类型:临时节点。这种临时节点有一个特性:如果创建临时节点的客户端与 ZooKeeper 集群失去连接,这个临时节点就会自动消失。在 ZooKeeper 内部,它维护了 ZooKeeper 集群与所有客户端的心跳,通过判断心跳的状态,来确定是否需要删除客户端创建的临时节点。
- watcher:ZooKeeper 还提供了一种订阅 ZNode 状态变化的通知机制:Watcher,一旦 ZNode 或者它的子节点状态发生了变化,订阅的客户端会立即收到通知。:利用 ZooKeeper 临时节点和 Watcher 机制,我们很容易随时来获取业务集群中每个节点的存活状态,并且可以监控业务集群的节点变化情况,当有节点上下线时,都可以收到来自 ZooKeeper 的通知。
Kafka 在 ZooKeeper 中保存了哪些信息?
- Broker 信息:/brokers/ids/[0…N],每个临时节点对应着一个在线的 Broker,Broker 启动后会创建一个临时节点,代表 Broker 已经加入集群可以提供服务了,节点名称就是 BrokerID,节点内保存了包括 Broker 的地址、版本号、启动时间等等一些 Broker 的基本信息。如果 Broker 宕机或者与 ZooKeeper 集群失联了,这个临时节点也会随之消失。
-
主题和分区的信息。/brokers/topics/ 节点下面的每个子节点都是一个主题,节点的名称就是主题名称。每个主题节点下面都包含一个固定的 partitions 节点,pattitions 节点的子节点就是主题下的所有分区,节点名称就是分区编号
- 每个分区节点下面是一个名为 state 的临时节点,节点中保存着分区当前的 leader 和所有的 ISR 的 BrokerID。这个 state 临时节点是由这个分区当前的 Leader Broker 创建的。如果这个分区的 Leader Broker 宕机了,对应的这个 state 临时节点也会消失,直到新的 Leader 被选举出来,再次创建 state 临时节点。
Kafka 客户端如何找到对应的 Broker?
Kafka 客户端如何找到主题、队列对应的 Broker
先根据主题和队列,找到分区对应的 state 临时节点,state 节点中保存了这个分区 Leader 的 BrokerID。拿到这个 Leader 的 BrokerID 后,再去找到 BrokerID 对应的临时节点,就可以获取到 Broker 真正的访问地址了。
Kafka 的客户端并不会去直接连接 ZooKeeper,它只会和 Broker 进行远程通信,那ZooKeeper 上的元数据应该是通过 Broker 中转给每个客户端的。
Broker 处理所有 RPC 请求的入口类在 kafka.server.KafkaApis#handle 这个方法里面,找到对应处理更新元数据的方法 handleTopicMetadataRequest(RequestChannel.Request),
先根据请求中的主题列表,去本地的元数据缓存 MetadataCache 中过滤出相应主题的元数据,右半部分的那棵树的子集,然后再去本地元数据缓存中获取所有 Broker 的集合,最后把这两部分合在一起,作为响应返回给客户端。
Kafka 在每个 Broker 中都维护了一份和 ZooKeeper 中一样的元数据缓存,并不是每次客户端请求元数据就去读一次 ZooKeeper。由于 ZooKeeper 提供了 Watcher 这种监控机制,Kafka 可以感知到 ZooKeeper 中的元数据变化,从而及时更新 Broker 中的元数据缓存。
kafka的事务
Kafka 的事务和 Exactly Once 可以解决什么问题?
kafka事务:解决的问题是,确保在一个事务中发送的多条消息,要么都成功,要么都失败。注意,这里面的多条消息可以是发往多个主题和分区的消息。更多的情况下被用来配合 Kafka 的幂等机制来实现 Kafka 的 Exactly Once 语义。
exactly once:在流计算中,用 Kafka 作为数据源,并且将计算结果保存到 Kafka, 这种场景下,数据从 Kafka 的某个主题中消费,在计算集群中计算,再把计算结果保存在 Kafka 的其他主题中。这样的过程中,保证每条息都被恰好计算一次,确保计算结果正确。
**事务实现:**基于两阶段提交来实现
- 事务协调者:负责在服务端协调整个事务。是 Broker 进程的一部分,协调者和分区一样通过选举来保证自身的可用性。存在多个协调者,每个协调者负责管理和使用事务日志中的几个分区
- 用于记录事务日志的主题:记录的数据就是类似于“开启事务”“提交事务”这样的事务日志。
实现流程:
-
开启事务的时候,生产者会给协调者发一个请求来开启事务,协调者在事务日志中记录下事务 ID。
-
生产者在发送消息之前,还要给协调者发送请求,告知发送的消息属于哪个主题和分区,这个信息也会被协调者记录在事务日志中。接下来,生产者就可以像发送普通消息一样来发送事务消息, Kafka 在处理未提交的事务消息时,和普通消息是一样的,直接发给 Broker,保存在这些消息对应的分区中,Kafka 会在客户端的消费者中,暂时过滤未提交的事务消息。
-
消息发送完成后,生产者给协调者发送提交或回滚事务的请求,由协调者来开始两阶段提交,完成事务。
- 第一阶段:协调者把事务的状态设置为“预提交”,并写入事务日志。到这里,实际上事务已经成功了,无论接下来发生什么情况,事务最终都会被提交。
- 开始第二阶段:协调者在事务相关的所有分区中,都会写一条“事务结束”的特殊消息,当 Kafka 的消费者,也就是客户端,读到这个事务结束的特殊消息之后,它就可以把之前暂时过滤的那些未提交的事务消息,放行给业务代码进行消费了。最后,协调者记录最后一条事务日志,标识这个事务已经结束了。
Kafka 这个两阶段的流程,准备阶段,生产者发消息给协调者开启事务,然后消息发送到每个分区上。提交阶段,生产者发消息给协调者提交事务,协调者给每个分区发一条“事务结束”的消息,完成分布式事务提交。
MQTT协议:如何支持海量的在线IoT设备
IoT特点:便宜;无线连接,经常移动(网络连接不稳定)–加入心跳和会话机制;服务端需要支撑海量的 IoT 设备同时在线,需要支撑的客户端数量远不止几万几十万
MQTT集群支持海量在线的IoT设备
负载均衡:首先接入的地址最好是一个域名(不是必须的),这样域名的后面可以配置多个 IP 地址做负载均衡。也可以直接连接负载均衡器。负载均衡可以选择像 F5 这种专用的负载均衡硬件,也可以使用 Nginx 这样的软件,只要是四层或者支持 MQTT 协议的七层负载均衡设备,都可以选择。
proxy:负载均衡器的后面,需要部署一个 Proxy 集群,作用:
- 来承接海量 IoT 设备的连接
- 来维护与客户端的会话
- 作为代理,在客户端和 Broker 之间进行消息转发。
在 Proxy 集群的后面是 Broker 集群,负责保存和收发消息。
有的 MQTT Server 它的集群架构是这样的:
Proxy 和 Broker 的功能集成到了一个进程中。前置 Proxy 的方式很容易解决海量连接的问题,Proxy 是可以水平扩展的,只要用足够多数量的 Proxy 节点,就可以抗住海量客户端同时连接。每个 Proxy 和每个 Broker 只用一个连接通信就可以了,这样对于每个 Broker 来说,它的连接数量最多不会超过 Proxy 节点的数量。
Proxy 对于会话的处理方式,可以借鉴 Tomcat 处理会话的方式。
- 将会话保存在 Proxy 本地,每个 Proxy 节点都只维护连接到自己的这些客户端的会话。这种方式需要配合负载均衡来使用,负载均衡设备需要支持 sticky session,保证将相同会话的连接总是转发到同一个 Proxy 节点上。
- 将会话保存在一个外置的存储集群中,比如一个 Redis 集群或者 MySQL 集群。这样 Proxy 就可以设计成完全无状态的,对于负载均衡设备也没有特殊的要求。但这种方式要求外置存储集群具备存储千万级数据的能力,同时具有很好的性能。
对于如何支持海量的主题,比较可行的解决方案是,在 Proxy 集群的后端,部署多组 Broker 小集群,比如说,可以是多组 Kafka 小集群,每个小集群只负责存储一部分主题。这样对于每个 Broker 小集群,主题的数量就可以控制在可接受的范围内。由于消息是通过 Proxy 来进行转发的,我们可以在 Proxy 中采用一些像一致性哈希等分片算法,根据主题名称找到对应的 Broker 小集群。这样就解决了支持海量主题的问题。
并发下的幂等性
如果可以保证以下这些操作的原子性,哪些操作在并发调用的情况下具备幂等性?答案:D
- A. f(n, a):给账户 n 转入 a 元
- B. f(n, a):将账户 n 的余额更新为 a 元
- C. f(n, b, a):如果账户 n 当前的余额为 b 元,那就将账户的余额更新为 n 元
- D. f(n, v, a):如果账户 n 当前的流水号等于 v,那么给账户的余额加 a 元,并将流水号加一
一个操作是否幂等,还跟调用顺序有关系,在线性调用情况下,具备幂等性的操作,在并发调用时,就不一定具备幂等性了。
第二十九节。第三十节
实现简单的RPC框架
这里所说的 RPC 框架,是指类似于 Dubbo、gRPC 这种框架,应用程序可以“在客户端直接调用服务端方法,就像调用本地方法一样。
而一些基于 REST 的远程调用框架,虽然同样可以实现远程调用,但它对使用者并不透明,无论是服务端还是客户端,都需要和 HTTP 协议打交道,解析和封装 HTTP 请求和响应。这类框架并不能算是“RPC 框架”。
原理-RPC 框架是怎么调用远程服务的
例:spring和Dubbo配合的微服务体系,RPC框架是如何实现调用远程服务的。
一般来说,客户端和服务端分别是这样的:Dubbo 看起来就像把服务端进程中的实现类“映射”到了客户端进程中一样
@Component
public class HelloClient {
@Reference // dubbo 注解 @Reference 注解,获得一个实现了 HelloServicer 这个接口的对象
private HelloService helloService;
public String hello() {
return helloService.hello("World");
}
}
@Service // dubbo 注解
@Component
public class HelloServiceImpl implements HelloService {
@Override
public String hello(String name) {
return "Hello " + name;
}
}
在客户端,业务代码得到的 HelloService 这个接口的实例实际上是由 RPC 框架提供的一个代理类的实例。这个代理类有一个专属的名称,叫“桩(Stub)”。不同的 RPC 框架中,这个桩的生成方式并不一样,有些是在编译阶段生成的,有些是在运行时动态生成的,
HelloService 的桩,同样要实现 HelloServer 接口,客户端在调用 HelloService 的 hello 方法时,实际上调用的是桩的 hello 方法, hello 方法里会构造一个请求,这个请求就是一段数据结构,请求中包含两个重要的信息:
- 请求的服务名,客户端调用的是 HelloService 的 hello 方法;
- 请求的所有参数,参数 name, 它的值是“World”。
然后,它会把这个请求发送给服务端,等待服务的响应。
服务端处理请求:把请求中的服务名解析出来->根据服务名找服务端进程中,有没有这个服务名对应的服务提供者。
例:在收到请求后,可以通过请求中的服务名找到 HelloService 真正的实现类 HelloServiceImpl。找到实现类之后,RPC 框架会调用这个实现类的 hello 方法,使用的参数值就是客户端发送过来的参数值。服务端的 RPC 框架在获得返回结果之后,再将结果封装成响应,返回给客户端。客户端 RPC 框架的桩收到服务端的响应之后,从响应中解析出返回值,返回给客户端的调用方。这样就完成了一次远程调用。
客户端是如何找到服务端地址的呢?在 RPC 框架中,实现原理和消息队列的实现是完全一样的,通过一个 NamingService 来解决的。
在 RPC 框架中, NamingService 称为注册中心。
- 服务端的业务代码在向 RPC 框架中注册服务之后,RPC 框架就会把这个服务的名称和地址发布到注册中心上。
- 客户端的桩在调用服务端之前,会向注册中心请求服务端的地址,请求的参数就是服务名称 HelloService#hello,注册中心会返回提供这个服务的地址。
- 客户端再去请求服务端。
只要 RPC 框架保证在不同的编程语言中,使用相同的序列化协议,就可以实现跨语言的通信。
实现一个简单的 RPC 框架并不是很难,绝大部分技术,包括:高性能网络传输、序列化和反序列化、服务路由的发现方法等。
RPC总体结构
定义
RPC 框架对外提供的所有服务定义在一个接口 RpcAccessPoint 中
/**
* RPC 框架对外提供的服务接口
*/
public interface RpcAccessPoint extends Closeable{
/**
* 客户端使用:客户端获取远程服务的引用
* @param uri 远程服务地址
* @param serviceClass 服务的接口类的 Class
* @param <T> 服务接口的类型
* @return 远程服务引用
*/
<T> T getRemoteService(URI uri, Class<T> serviceClass);
/**
* 服务端使用:服务端注册服务的实现实例
* @param service 实现实例
* @param serviceClass 服务的接口类的 Class
* @param <T> 服务接口的类型
* @return 服务地址
*/
<T> URI addServiceProvider(T service, Class<T> serviceClass);
/**
* 服务端启动 RPC 框架,监听接口,开始提供远程服务。
* @return 服务实例,用于程序停止的时候安全关闭服务。
*/
Closeable startServer() throws Exception;
}
注册中心的接口 NameService:
/**
* 注册中心
*/
public interface NameService {
/**
* 注册服务
* @param serviceName 服务名称
* @param uri 服务地址
*/
void registerService(String serviceName, URI uri) throws IOException;
/**
* 查询服务地址
* @param serviceName 服务名称
* @return 服务地址
*/
URI lookupService(String serviceName) throws IOException;
}
使用
定义一个服务接口:
public interface HelloService {
String hello(String name);
}
客户端:
//调用注册中心方法查询服务地址
URI uri = nameService.lookupService(serviceName);
//获取远程服务本地实例--桩
HelloService helloService = rpcAccessPoint.getRemoteService(uri, HelloService.class);
//调用方法
String response = helloService.hello(name);
logger.info(" 收到响应: {}.", response);
服务端:
public class HelloServiceImpl implements HelloService {
@Override
public String hello(String name) {
String ret = "Hello, " + name;
return ret;
}
}
将这个实现注册到 RPC 框架上,并启动 RPC 服务:
//启动rpc框架的服务
rpcAccessPoint.startServer();
//调用rpc框架方法,注册 helloService 服务
URI uri = rpcAccessPoint.addServiceProvider(helloService, HelloService.class);
//调用注册中心方法注册服务地址
nameService.registerService(serviceName, uri);
通信与序列化-RPC 框架是怎么调用远程服务的
设计一个通用的高性能序列化实现?
可扩展的,通用方法
public class SerializeSupport {
//用于反序列化
public static <E> E parse(byte [] buffer) {
// ...
}
//用于序列化
public static <E> byte [] serialize(E entry) {
// ...
}
}
使用
// 序列化
MyClass myClassObject = new MyClass();
byte [] bytes = SerializeSupport.serialize(myClassObject);
// 反序列化
MyClass myClassObject1 = SerializeSupport.parse(bytes);
一般的 RPC 框架采用的都是通用的序列化实现,比如:
- gRPC 采用的是 Protobuf 序列化实现
- Dubbo 支持 hession2 等好几种序列化实现。
RPC 框架不像消息队列一样,采用性能更好的专用的序列化实现。
原因:
- 消息队列需要序列化数据的类型是固定的,只是它自己的内部通信的一些命令。
- RPC 框架需要序列化的数据是,用户调用远程方法的参数,这些参数可能是各种数据类型,所以必须使用通用的序列化实现,确保各种类型的数据都能被正确的序列化和反序列化。
给所有序列化的实现类定义一个 Serializer 接口,所有的序列化实现类都实现这个接口就可以了:
public interface Serializer<T> {
/**
* 计算对象序列化后的长度,主要用于申请存放序列化数据的字节数组
* @param entry 待序列化的对象
* @return 对象序列化后的长度
*/
int size(T entry);
/**
* 序列化对象。将给定的对象序列化成字节数组
* @param entry 待序列化的对象
* @param bytes 存放序列化数据的字节数组
* @param offset 数组的偏移量,从这个位置开始写入序列化数据
* @param length 对象序列化后的长度,也就是{@link Serializer#size(java.lang.Object)}方法的返回值。
*/
void serialize(T entry, byte[] bytes, int offset, int length);
/**
* 反序列化对象
* @param bytes 存放序列化数据的字节数组
* @param offset 数组的偏移量,从这个位置开始写入序列化数据
* @param length 对象序列化后的长度
* @return 反序列化之后生成的对象
*/
T parse(byte[] bytes, int offset, int length);
/**
* 用一个字节标识对象类型,每种类型的数据应该具有不同的类型值
*/
byte type();
/**
* 返回序列化对象类型的 Class 对象:
* 目的:在执行序列化的时候,通过被序列化的对象类型找到对应序列化实现类。
*/
Class<T> getSerializeClass();
}
利用 Serializer 接口,实现 SerializeSupport 这个支持任何对象类型序列化的通用静态类了。首先我们定义两个 Map,这两个 Map 中存放着所有实现 Serializer 接口的序列化实现类。
利用 Serializer 接口,实现 SerializeSupport 这个支持任何对象类型序列化的通用静态类了。首先我们定义两个 Map,这两个 Map 中存放着所有实现 Serializer 接口的序列化实现类。
//key:序列化实现类对应的序列化对象的类型,用途是在序列化时,通过被序列化的对象类型,找到对应的序列化实现类
private static Map<Class<?>/* 序列化对象类型 */, Serializer<?>/* 序列化实现 */> serializerMap = new HashMap<>();
//key 是序列化实现类的类型,用于在反序列化的时候,从序列化的数据中读出对象类型,然后找到对应的序列化实现类。
private static Map<Byte/* 序列化实现类型 */, Class<?>/* 序列化对象类型 */> typeMap = new HashMap<>();
实现序列化和反序列化实现思路:通过一个类型在这两个 Map 中进行查找,查找的结果就是对应的序列化实现类的实例,也就是 Serializer 接口的实现,然后调用对应的序列化或者反序列化方法就可以了。
所有的 Serializer 的实现类是怎么加载到 SerializeSupport 的那两个 Map 中利用了 Java 的一个 SPI 类加载机制。
使用序列化的模块只要依赖 SerializeSupport 这个静态类,调用它的序列化和反序列化方法就可以了,不需要依赖任何序列化实现类。对于序列化实现的提供者来说,也只需要依赖并实现 Serializer 这个接口就可以了。
eg:
//统一使用 UTF8 编码。否则,如果遇到执行序列化和反序列化的两台服务器默认编码不一样,就会出现乱码。我们在开发过程用遇到的很多中文乱码问题,绝大部分都是这个原因。
public class StringSerializer implements Serializer<String> {
@Override
public int size(String entry) {
return entry.getBytes(StandardCharsets.UTF_8).length;
}
@Override
public void serialize(String entry, byte[] bytes, int offset, int length) {
byte [] strBytes = entry.getBytes(StandardCharsets.UTF_8);
System.arraycopy(strBytes, 0, bytes, offset, strBytes.length);
}
@Override
public String parse(byte[] bytes, int offset, int length) {
return new String(bytes, offset, length, StandardCharsets.UTF_8);
}
@Override
public byte type() {
return Types.TYPE_STRING;
}
@Override
public Class<String> getSerializeClass() {
return String.class;
}
}
这个序列化的实现,对外提供服务的就只有一个 SerializeSupport 静态类,并且可以通过扩展支持序列化任何类型的数据。
使用 Netty 来实现异步网络通信
把通信的部分也封装成接口。在这个 RPC 框架中,对于通信模块的需求是这样的:只需要客户端给服务端发送请求,然后服务返回响应就可以了。所以,通信接口只需要提供一个发送请求方法就可以了:
public interface Transport {
/**
* 发送请求命令
* @param request 请求命令
* @return 返回值是一个 Future,Future通过这个 CompletableFuture 对象可以获得响应结果
* 直接调用它的 get 方法来获取响应数据,相当于同步调用;
* 也可以使用以 then 开头的一系列异步方法,指定当响应返回的时候,需要执行的操作,就等同于异步调用。
* 等于,这样一个方法既可以同步调用,也可以异步调用。
*/
CompletableFuture<Command> send(Command request);
}
Command 类:包含header和payload字节数组,
public class Command {
protected Header header;
//命令中要传输的数据,要求这个数据已经是被序列化之后生成的字节数组
private byte [] payload;
//...
}
public class Header {
//用于唯一标识一个请求命令,在使用双工方式异步收发数据的时候,requestId用于请求和响应的配对。
private int requestId;
//用于标识这条命令的版本号
private int version;
//用于标识这条命令的类型,主要目的是为了能让接收命令一方来识别收到的是什么命令,以便路由到对应的处理类中去。
private int type;
// ...
}
public class ResponseHeader extends Header {
private int code;
private String error;
// ...
}
在设计通信协议时,让协议具备持续的升级能力,并且保持向下兼容是非常重要的。为了确保使用这个传输协议的这些程序还能正常工作,或者是向下兼容,协议中必须提供一个版本号,标识收到的这条数据使用的是哪个版本的协议。
发送方在发送命令的时候需要带上这个命令的版本号,接收方在收到命令之后必须先检查命令的版本号,如果接收方可以支持这个版本的命令就正常处理,否则就拒绝接收这个命令,返回响应告知对方:我不认识这个命令。这样才是一个完备的,可持续的升级的通信协议。
注意:这个版本号是命令的版本号,或者说是传输协议的版本号,它不等同于程序的版本号。
send 方法的实现,本质上就是一个异步方法,在把请求数据发出去之后就返回了,并不会阻塞当前这个线程去等待响应返回来。来看一下它的实现:
@Override
public CompletableFuture<Command> send(Command request) {
// 构建返回值
CompletableFuture<Command> completableFuture = new CompletableFuture<>();
try {
// 将在途请求放到 inFlightRequests 中
inFlightRequests.put(new ResponseFuture(request.getHeader().getRequestId(), completableFuture));
// 发送命令
channel.writeAndFlush(request).addListener((ChannelFutureListener) channelFuture -> {
// 处理发送失败的情况
if (!channelFuture.isSuccess()) {
completableFuture.completeExceptionally(channelFuture.cause());
channel.close();
}
});
} catch (Throwable t) {
// 处理发送异常
inFlightRequests.remove(request.getHeader().getRequestId());
completableFuture.completeExceptionally(t);
}
return completableFuture;
}
- 把请求中的 requestId 和返回的 completableFuture 一起,构建了一个 ResponseFuture 对象,然后把这个对象放到了 inFlightRequests 这个变量中。inFlightRequests 中存放了所有在途的请求,也就是已经发出了请求但还没有收到响应的这些 responseFuture 对象。
- 调用 netty 发送数据的方法,把 request 命令发给对方。注意:已经发出去的请求,有可能会因为网络连接断开或者对方进程崩溃等各种异常情况,永远都收不到响应。那为了确保这些 ResponseFuture 不会在内存中越积越多,必须要捕获所有的异常情况,结束对应的 ResponseFuture。所以,两个地方都做了异常处理,分别应对发送失败和发送异常两种情况。
- 不能保证所有 ResponseFuture 都能正常或者异常结束,比如说,编写对端程序的程序员写的代码有问题,收到了请求没给返回响应,为了应对这种情况,超时的机制来保证所有情况下 ResponseFuture 都能结束,无论什么情况,只要超过了超时时间还没有收到响应,就认为这个 ResponseFuture 失败了,结束并删除它。这部分代码在 InFlightRequests 这个类中。
最佳实践-背压机制:如果是同步发送请求,客户端需要等待服务端返回响应,服务端处理这个请求需要花多长时间,客户端就要等多长时间。这实际上是一个天然的背压机制(Back pressure),服务端处理速度会天然地限制客户端请求的速度。
但是在异步请求中,客户端异步发送请求并不会等待服务端,缺少了这个天然的背压机制,如果服务端的处理速度跟不上客户端的请求速度,客户端的发送速度也不会因此慢下来,就会出现在请求越来越多,这些请求堆积在服务端的内存中,内存放不下就会一直请求失败。服务端处理不过来的时候,客户端还一直不停地发请求显然是没有意义的。
为了避免这种情况,需要增加一个背压机制,在服务端处理不过来的时候限制一下客户端的请求速度。
定义了一个信号量:
private final Semaphore semaphore = new Semaphore(10);
这个信号量有 10 个许可,每次往 inFlightRequest 中加入一个 ResponseFuture 的时候,需要先从信号量中获得一个许可,如果这时候没有许可了,就会阻塞当前这个线程,也就是发送请求的这个线程,直到有人归还了许可,才能继续发送请求。每结束一个在途请求,就归还一个许可,这样就可以保证在途请求的数量最多不超过 10 个请求,积压在服务端正在处理或者待处理的请求也不会超过 10 个。
客户端-RPC 框架
如何来动态地生成桩
RPC 框架中的桩采用了代理模式:给某一个对象提供一个代理对象,并由代理对象控制对原对象的引用,被代理的那个对象称为委托对象。
在 RPC 框架中
- 代理对象是由 RPC 框架的客户端来提供的“桩”
- 委托对象就是在服务端,真正实现业务逻辑的服务类的实例。
利用代理模式,在调用流程中动态地注入一些非侵入式业务逻辑(在现有的调用链中,增加一些业务逻辑,而不用去修改调用链上下游的代码)。
在 RPC 框架的客户端中来实现代理类-“桩”。
public interface StubFactory {
//创建一个桩的实例
//Transport 对象:是用来给服务端发请求的时候使用的
//Class 对象:它用来告诉桩工厂:我需要你给我创建的这个桩,应该是什么类型的
//createStub 的返回值就是由工厂创建出来的桩。
<T> T createStub(Transport transport, Class<T> serviceClass);
}
这个桩是一个由 RPC 框架生成的类,这个类它要实现给定的接口,里面的逻辑就是把方法名和参数封装成请求,发送给服务端,然后再把服务端返回的调用结果返回给调用方。
RPC 框架怎么才能根据要实现的接口来生成一个类呢?在这一块儿,不同的 RPC 框架的实现是不一样的,比如,
- gRPC 在编译 IDL 的时候就把桩生成好了,这个时候编译出来桩,它是目标语言的源代码文件。比如说,目标语言是 Java,编译完成后它们会生成一些 Java 的源代码文件,其中以 Grpc.java 结尾的文件就是生成的桩的源代码。这些生成的源代码文件再经过 Java 编译器编译以后,就成了桩。
- Dubbo 是在运行时动态生成的桩,它利用了很多 Java 语言底层的特性,Java 源代码编译完成之后,生成的是一些 class 文件,JVM 在运行的时候,读取这些 Class 文件来创建对应类的实例。这个 Class 文件虽然非常复杂,但本质上,它里面记录的内容,就是编写的源代码中的内容,包括类的定义,方法定义和业务逻辑等等,并且它也是有固定的格式的。如果说,我们按照这个格式,来生成一个 class 文件,只要这个文件的格式是符合 Java 规范的,JVM 就可以识别并加载它。这样就不需要经过源代码、编译这些过程,直接动态来创建一个桩。
在这个 RPC 的例子中,采用一种更通用的方式来动态生成桩:先生成桩的源代码,然后动态地编译这个生成的源代码,然后再加载到 JVM 中。
限定:服务接口只能有一个方法,并且这个方法只能有一个参数,参数和返回值的类型都是 String 类型。
需要动态生成的这个桩,它每个方法的逻辑都是一样的,都是把类名、方法名和方法的参数封装成请求,然后发给服务端,收到服务端响应之后再把结果作为返回值,返回给调用方。定义一个 AbstractStub 的抽象类,在这个类中实现大部分通用的逻辑,让所有动态生成的桩都继承这个抽象类,这样动态生成桩的代码会更少一些。
实现这个 StubFactory 接口动态生成桩。静态变量STUB_SOURCE_TEMPLAT:桩的源代码模板,需要做的就是,填充模板中变量,生成桩的源码,然后动态的编译、加载这个桩就可以了。
public class DynamicStubFactory implements StubFactory{
private final static String STUB_SOURCE_TEMPLATE =
//把接口的类名、方法名和序列化后的参数封装成一个 RpcRequest 对象
//调用父类 AbstractStub 中的 invokeRemote 方法,发送给服务端。
//invokeRemote 方法的返回值就是序列化的调用结果
"package com.github.liyue2008.rpc.client.stubs;\n" +
"import com.github.liyue2008.rpc.serialize.SerializeSupport;\n" +
"\n" +
"public class %s extends AbstractStub implements %s {\n" +
" @Override\n" +
" public String %s(String arg) {\n" +
" return SerializeSupport.parse(\n" +
" invokeRemote(\n" +
" new RpcRequest(\n" +
" \"%s\",\n" +
" \"%s\",\n" +
" SerializeSupport.serialize(arg)\n" +
" )\n" +
" )\n" +
" );\n" +
" }\n" +
"}";
@Override
@SuppressWarnings("unchecked")
//从 serviceClass 参数中,可以取到服务接口定义的所有信息
//包括接口名、它有哪些方法、每个方法的参数和返回值类型等等
//通过这些信息,可以来填充模板,生成桩的源代码。
public <T> T createStub(Transport transport, Class<T> serviceClass) {
try {
// 填充模板
String stubSimpleName = serviceClass.getSimpleName() + "Stub";
String classFullName = serviceClass.getName();
String stubFullName = "com.github.liyue2008.rpc.client.stubs." + stubSimpleName;
String methodName = serviceClass.getMethods()[0].getName();
String source = String.format(STUB_SOURCE_TEMPLATE, stubSimpleName, classFullName, methodName, classFullName, methodName);
// 编译源代码
JavaStringCompiler compiler = new JavaStringCompiler();
Map<String, byte[]> results = compiler.compile(stubSimpleName + ".java", source);
// 加载编译好的类
Class<?> clazz = compiler.loadClass(stubFullName, results);
// 把 Transport 赋值给桩
ServiceStub stubInstance = (ServiceStub) clazz.newInstance();
stubInstance.setTransport(transport);
// 返回这个桩
return (T) stubInstance;
} catch (Throwable t) {
throw new RuntimeException(t);
}
}
}
桩的类名就定义为:“接口名 + Stub”。填充好模板生成的源代码存放在 source 变量中,然后经过动态编译、动态加载之后,我们就可以拿到这个桩的类 clazz,利用反射创建一个桩的实例 stubInstance。把用于网络传输的对象 transport 赋值给桩,这样桩才能与服务端进行通信。到这里,我们就实现了动态创建一个桩。
使用依赖倒置原则解耦调用者和实现
很多地方都采用了同样一种解耦的方法:通过定义一个接口来解耦调用方和实现称为“依赖倒置原则(Dependence Inversion Principle)”,
核心思想:调用方不应依赖于具体实现,而是为实现定义一个接口,让调用方和实现都依赖于这个接口。这种方法也称为“面向接口编程”。
要解耦调用方和实现类,还需要解决一个问题:谁来创建实现类的实例?SPI(Service Provider Interface)。在 SPI 中,每个接口在目录 META-INF/services/ 下都有一个配置文件,文件名就是以这个接口的类名,文件的内容就是它的实现类的类名。以 StubFactory 接口为例,我们看一下它的配置文件:
$cat rpc-netty/src/main/resources/META-INF/services/com.github.liyue2008.rpc.client.StubFactory
com.github.liyue2008.rpc.client.DynamicStubFactory
只要把这个配置文件、接口和实现类都放到 CLASSPATH 中,就可以通过 SPI 的方式来进行加载了。加载的参数就是这个接口的 class 对象,返回值就是这个接口的所有实现类的实例,这样就在“不依赖实现类”的前提下,获得了一个实现类的实例。具体的实现代码在 ServiceSupport 这个类中。
服务端-RPC 框架
对于这个 RPC 框架来说,服务端可以分为两个部分:注册中心和 RPC 服务。
- 注册中心的作用是帮助客户端来寻址,找到对应 RPC 服务的物理地址
- RPC 服务用于接收客户端桩的请求,调用业务服务的方法,并返回结果
注册中心如何实现
一个完整的注册中心也是分为客户端和服务端两部分的
- 客户端给调用方提供 API,并实现与服务端的通信
- 服务端提供真正的业务功能,记录每个 RPC 服务发来的注册信息,并保存到它的元数据中。当有客户端来查询服务地址的时候,它会从元数据中获取服务地址,返回给客户端。
这里只实现了一个单机版的注册中心,它只有客户端没有服务端,所有的客户端依靠读写同一个元数据文件来实现元数据共享。
首先,在 RPC 服务的接入点,接口 RpcAccessPoint 中增加一个获取注册中心实例的方法:
public interface RpcAccessPoint extends Closeable{
/**
* 获取注册中心的引用
* @param nameServiceUri 注册中心 URI
* @return 注册中心引用
*/
NameService getNameService(URI nameServiceUri);
// ...
}
给 NameService 接口增加两个方法:
public interface NameService {
/**
* 返回所有支持的协议
*/
Collection<String> supportedSchemes();
/**
* 给定注册中心服务端的 URI,去建立与注册中心服务端的连接。
* @param nameServiceUri 注册中心地址
*/
void connect(URI nameServiceUri);
// ...
}
getNameService 的实现:通过 SPI 机制加载所有的 NameService 的实现类,然后根据给定的 URI 中的协议,去匹配支持这个协议的实现类,然后返回这个实现的引用就可以了。实现了一个可扩展的注册中心接口,系统可以根据 URI 中的协议,动态地来选择不同的注册中心实现。增加一种注册中心的实现,也不需要修改任何代码,只要按照 SPI 的规范,把协议的实现加入到运行时 CLASSPATH 中就可以了。
注意:本地文件它是一个共享资源,它会被 RPC 框架所有的客户端和服务端并发读写。所以必须要加锁!
由于这个文件可能被多个进程读写,这里面必须使用由操作系统提供的文件锁。这个锁的使用和其他的锁并没有什么区别,同样是在访问共享文件之前先获取锁,访问共享资源结束后必须释放锁。
RPC服务怎么实现
rpc服务端功能
- 服务端的业务代码把服务的实现类注册到 RPC 框架中 ;
- 接收客户端桩发出的请求,调用服务的实现类并返回结果;
把服务的实现类注册到 RPC 框架中,只要使用一个合适的数据结构,记录下所有注册的实例就可以了,后面在处理客户端请求的时候,会用到这个数据结构来查找服务实例。
RPC 框架的服务端如何来处理客户端发送的 RPC 请求。首先来看服务端中,使用 Netty 接收所有请求数据的处理类 RequestInvocation 的 channelRead0 方法。
//处理逻辑:根据请求命令的 Handler 中的请求类型 type,去 requestHandlerRegistry 中查找对应的请求处理器 RequestHandler,然后调用请求处理器去处理请求,最后把结果发送给客户端。
@Override
protected void channelRead0(ChannelHandlerContext channelHandlerContext, Command request) throws Exception {
RequestHandler handler = requestHandlerRegistry.get(request.getHeader().getType());
if(null != handler) {
Command response = handler.handle(request);
if(null != response) {
channelHandlerContext.writeAndFlush(response).addListener((ChannelFutureListener) channelFuture -> {
if (!channelFuture.isSuccess()) {
logger.warn("Write response failed!", channelFuture.cause());
channelHandlerContext.channel().close();
}
});
} else {
logger.warn("Response is null!");
}
} else {
throw new Exception(String.format("No handler for request with type: %d!", request.getHeader().getType()));
}
}
这种通过“请求中的类型”,把请求分发到对应的处理类或者处理方法的设计,使用了一个命令注册机制,让这个路由分发的过程省略了大量的 if-else 或者是 switch 代码。
好处:可以很方便地扩展命令处理器,而不用修改路由分发的方法,并且代码看起来更加优雅。
这个 RPC 框架中只需要处理一种类型的请求:RPC 请求,只实现了一个命令处理器(核心):RpcRequestHandler。
处理客户端请求, handle 方法的实现。
@Override
public Command handle(Command requestCommand) {
Header header = requestCommand.getHeader();
// 从 payload 中反序列化 RpcRequest
RpcRequest rpcRequest = SerializeSupport.parse(requestCommand.getPayload());
// 查找所有已注册的服务提供方,寻找 rpcRequest 中需要的服务
Object serviceProvider = serviceProviders.get(rpcRequest.getInterfaceName());
// 找到服务提供者,利用 Java 反射机制调用服务的对应方法
String arg = SerializeSupport.parse(rpcRequest.getSerializedArguments());
Method method = serviceProvider.getClass().getMethod(rpcRequest.getMethodName(), String.class);
String result = (String ) method.invoke(serviceProvider, arg);
// 把结果封装成响应命令并返回
return new Command(new ResponseHeader(type(), header.getVersion(), header.getRequestId()), SerializeSupport.serialize(result));
// ...
}
- 把 requestCommand 的 payload 属性反序列化成为 RpcRequest;
- 根据 rpcRequest 中的服务名,去成员变量 serviceProviders 中查找已注册服务实现类的实例;
- 找到服务提供者之后,利用 Java 反射机制调用服务的对应方法;
- 把结果封装成响应命令并返回,在 RequestInvocation 中,它会把这个响应命令发送给客户端。
再来看成员变量 serviceProviders,它的定义是:Map serviceProviders。它实际上就是一个 Map,Key 就是服务名,Value 就是服务提供方,也就是服务实现类的实例。
@Singleton
public class RpcRequestHandler implements RequestHandler, ServiceProviderRegistry {
@Override
public synchronized <T> void addServiceProvider(Class<? extends T> serviceClass, T serviceProvider) {
serviceProviders.put(serviceClass.getCanonicalName(), serviceProvider);
logger.info("Add service: {}, provider: {}.",
serviceClass.getCanonicalName(),
serviceProvider.getClass().getCanonicalName());
}
// ...
}
这个类不仅实现了处理客户端请求的 RequestHandler 接口,同时还实现了注册 RPC 服务 ServiceProviderRegistry 接口,也就是说,RPC 框架服务端需要实现的两个功能——注册 RPC 服务和处理客户端 RPC 请求文章来源:https://www.toymoban.com/news/detail-652904.html
注意:RpcRequestHandler 上增加了一个注解 @Singleton,限定这个类它是一个单例模式,这样确保在进程中任何一个地方,无论通过 ServiceSupport 获取 RequestHandler 或者 ServiceProviderRegistry 这两个接口的实现类,拿到的都是 RpcRequestHandler 这个类的唯一的一个实例。这个 @Singleton 的注解和获取单例的实现在 ServiceSupport 中。文章来源地址https://www.toymoban.com/news/detail-652904.html
到了这里,关于消息队列学习笔记的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!