为什么数据存储结构重要
在存储系统中,其实不管数据是什么样的,归根结底其实都还是取决于数据的底层存储结构,而主要常见的就是数据库索引结构,B+树、Redis中跳表、以及LSM、搜索引擎中的倒排索引。本质都是如何利用不用的数据结构,在性能和存储空间之间权衡。数据写的速度和读取数据。
MySQL中索引如何用B+树实现的
常用数据结构分析
哈希表: 哈希表以O(1)的查询效率著名,但是其本身是用空间换时间。并且不支持范围查询。
平衡二叉查找树: 查询和写入都是O(logN) 进行中序遍历的话,可以得到一个有序的数据序列,但是不支持快速查找。
跳表: 跳表,其实是通过多层的链表结构实现,可以快速查询、删除、插入 都是O(LogN)
而B+树和跳表十分相视。
B+树

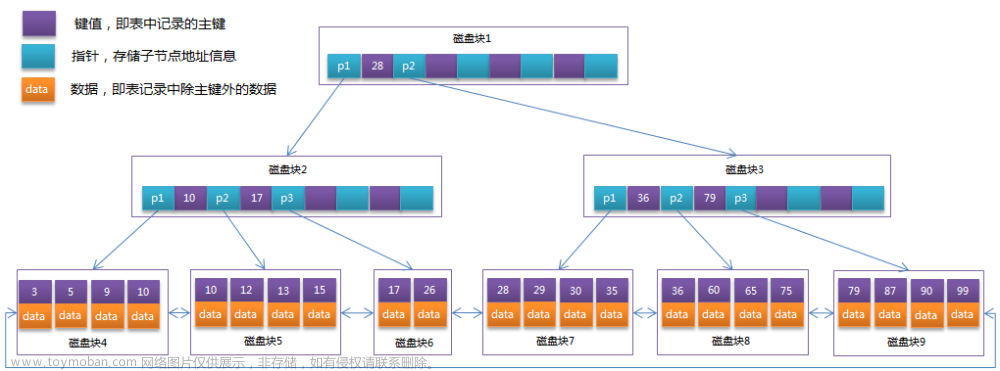
我们从从一个二叉查找树进行改造,将非叶子节点不存储数据,由叶子节点存储数据。并且叶子节点通过指针可以前后引用。这样,当我们查找数据的时候,找到15。然后可以通过遍历.next 就可以进行范围查询。这就是为什么叶子节点需要双向链表进行引用。
如果将全部的数据都存储到内存中,那么内存是放不下的,所以一个方式就是,只将根节点存储在内存中,其他节点存储在磁盘上。
而二叉查找数因为数据如果较多,树的高度就会更高,查询的IO次数更多。
所以一般使用固定阶段,3层来保证数据查询的IO次数。操作系统读取数据是按照Page 64KB进行读取。所以我们尽量让每个节点存储的数据等于一页的大小。
合并和分裂
因为在使用数据库的时候,会删除和增加数据,所以当超过一定的节点数据时,会进行分裂和合并操作。 文章来源:https://www.toymoban.com/news/detail-653160.html
文章来源:https://www.toymoban.com/news/detail-653160.html
小结
本篇主要简单介绍下B+数在MySQL索引是如何实现的,B树和B+数据的区别,一共在两个地方文章来源地址https://www.toymoban.com/news/detail-653160.html
- B+数节点不存储数据,只存储索引数据,B树存储的是数据。
- B树叶子结点不需要通过链表链接。
到了这里,关于【分布式存储】数据存储和检索~B+树的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!