分布式锁,顾名思义,分布式锁就是分布式场景下的锁,比如多台不同机器上的进程,去竞争同一项资源,就是分布式锁。
分布式锁特性
互斥性:锁的目的是获取资源的使用权,所以只让一个竞争者持有锁,这一点要尽可能保证;
安全性:避免锁因为异常永远不被释放。当一个竞争者在持有锁期间内,由于意外崩溃而导致未能主动解锁,其持有的锁也能够被兜底释放,并保证后续其它竞争者也能加锁;
对称性:同一个锁,加锁和解锁必须是同一个竞争者。不能把其他竞争者持有的锁给释放了。
可靠性:需要有一定程度的异常处理能力、容灾能力。
分布式锁的实现
1.直接用Redis的setnx命令
首先,当然是搭建一个最简单的实现方式, 直接用Redis的setnx命令, 这个命令的语法是: setnx key value如果key不存在,则会将key设置为value,并返回1;如果key存在,不会有任务影响,返回0。
基于这个特性,我们就可以用setnx实现加锁的目的:通过setnx加锁,加锁之后其他服务无法加锁,用完之后,再通过delete解锁
就是这个获取锁的过程就是setnx的过程 如果有锁了 那就会返回0 如果没锁 就会把key设置为value然后释放锁就会delete

2.支持过期时间
最简化版本有一个问题:如果获取锁的服务挂掉了,那么锁就一直得不到释放,就像石沉大海,查无音信。所以,我们需要一个超时来兜底。
Redis中有expire命令,用来设置一个key的超时时间。 但是setnx和expire不具备 原子性,如果setnx获取锁之后,服务挂掉(还没来的及设置时间),依旧是泥牛入海。
很自然,我们会想到,set和expire, 有没有原子操作?
当然有,Redis早就考虑到了这种场景,推出了如下执行语句: set key value nx ex seconds nx表示具备setnx特定,ex表示增加了过期时间,最后一个参数就是过期时间的值。
他把set和expire合成了一个原子操作
这个过期和释放锁是并列的 就是主动释放锁和过期都会delete
3.加上Owner
我们来试想一下如下场景:服务A获取了锁,由于业务流程比较长,或者网络延迟、GC卡顿等原因,导致锁过期,而业务还会继续进行。这时候,业务B已经拿到了锁,准备去执行,这个时候服务A恢复过来并做完了业务,就会释放锁,而B却还在继续执行。
在真实的分布式场景中,可能存在几十个竞争者,那么上述情况发生概率就很高,导致同一份资源频繁被不同竞争者同时访问,分布式锁也就失去了意义。
基于这个场景,我们可以发现,问题关键在于,竞争者可以释放其他人的锁。(也就是说 只能这个锁持有者自己释放了锁才行 就是这个delete过程 只能自己来删除 而不能其他线程删除)那么在异常情况下,就会出现问题,所以我们可以进一步给出解决方案: 分布式锁需要满足谁申请谁释放原则,不能释放别人的锁,也就是说,分布式锁,是要有归属的。
我们获取锁之前不是会有一个delete释放锁的过程吗? 我们让其他线程没法执行这个delete操作 只有我锁持有者可以delete
具体步骤 释放前先检测是否是持有者要delete 然后返回检查结果 然后再根据结果进行操作
4.引入LUA
释放前先检测是否是持有者要delete 然后返回检查结果 然后再根据结果进行操作
这三步不是原子的
我们来看 检测和返回结果之间的间隙
这个同时锁过期了
检测 这锁过期释放了锁 且有其他客户端获取到了锁 然后返回结果 删除锁
这个时候 已经判断完了它是自己的锁 他就会删除这个锁
这就造成了锁的误删
然后LUA给这仨操作合成原子操作了
(其实owner )
分布式锁的可靠性靠什么保证
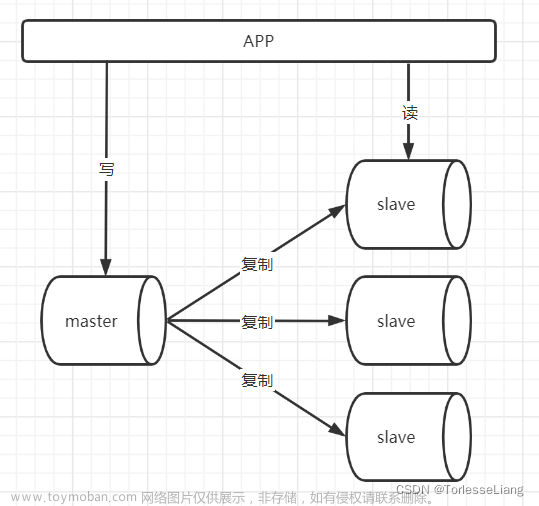
主从容灾
emmm 就是主库寄了 用从库顶一顶先
但是主从切换,需要人工参与,会提高人力成本。不过Redis已经有成熟的解决方案,也就是哨兵模式,可以灵活自动切换,不再需要人工介入。

一堆箭头乱七八糟的 描述一下 每个哨兵会监视其他两个哨兵的 同时还会监视主库和两个从库
通过增加从节点的方式,虽然一定程度解决了单点的容灾问题,但并不是尽善尽美的,由于同步有时延,Slave可能会损失掉部分数据,分布式锁可能失效,这就会发生短暂的多机获取到执行权限。
更妥善的方法
多机部署
如果对一致性的要求高一些, 可以尝试多机部署,比如Redis的RedLock, 大概的思路就是多个机器,通常是奇数个,达到一半以上同意加锁才算加锁成功,这样,可靠性会向ETCD靠近。
现在假设有5个Redis主节点,基本保证它们不会同时宕掉,获取锁和释放锁的过程中,客户端会执行以下操作:
1.向5个Redis申请加锁;
2.只要超过一半,也就是3个Redis返回成功,那么就是获取到了锁。如果超过一半失败, 需要向每个Redis发送解锁命令;
3.由于向5个Redis发送请求,会有一定时耗,所以锁剩余持有时间,需要减去请求时间。这个可以作为判断依据,如果剩余时间已经为0,那么也是获取锁失败:
4.使用完成之后,向5个Redis发送解锁请求。
这种模式的好处在于,如果挂了2台Redis,整个集群还是可用的,给了运维更多时间来修复。
(这种方法太重了 业务很少会用的到)
分布式系统三大困境
简称NPC
这种模式的好处在于,如果挂了2台Redis,整个集群还是可用的,给了运维更多时间来修复。
另外,多说一句,单点Redis的所有手段,这种多机模式都可以使用,比如为每个节点配置哨兵模式,由于加锁是
-半以上同意就成功,那么如果单个节点进行了主从切换,单个节点数据的丢失,就不会让锁失效了。这样增强了
可靠性。
N:Network Delay (网络延迟)当分布式锁获得返回包的时间过长,此时可能虽然加锁成功,但是已经时过境迁,锁可能很快过期。RedLock算 了做了些考量,也就是前面所说的锁剩余持有时间,需要减去请求时间,如此一来,就可以一定程度解决网络延迟的问题。
P: Process Pause (进程暂停)比如发生GC,获取锁之后GC了,处于GC执行中,然后锁超时。其他锁获取,这种情况几乎无解。这时候GC回来了,那么两个进程就获取到了同一个分布式锁。
也许你会说,在GC回来之后,可以再去查一次啊?
这里有两个问题,首先你怎么知道GC回来了?这个可以在做业务之前,通过时间,进行一个粗略判断,但也是很吃场景经验的;第二,如果你判断的时候是ok的,但是判断完GC了呢?这点RedLock是无法解决的。
文章来源:https://www.toymoban.com/news/detail-653233.html
C: Clock Drift (时钟漂移)
如果竞争者A,获得了RedLock,在5台分布式机器上都加上锁。为了方便分析,我们直接假设5台机器都发生了时钟漂移,锁瞬间过期了。这时候竞争者B拿到了锁,此时A和B拿到了相同的执行权限。
根据上述的分析.可以看出,RedLock也不能扛住NPC的挑战,因此,单单从分布式锁本身出发,完全可靠是不可能的。要实现一个相对可靠的分布式锁机制,还是需要和业务的配合,业务本身要幂等可重入,这样的设计可以省却很多麻烦。
文章来源地址https://www.toymoban.com/news/detail-653233.html
到了这里,关于Redis-分布式锁!的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!