蚂蚁蜜蜂分类数据集下载链接:https://download.pytorch.org/tutorial/hymenoptera_data.zip
要实现如图操作:
-
将ants分为ants_image和ants_label
-
将bees分成bees_image和bees_label

-
创建ants_label和bees_label,并且以图片名作为txt文件的名称,将标签写入到txt文件中


-
将标签写入到txt文件中
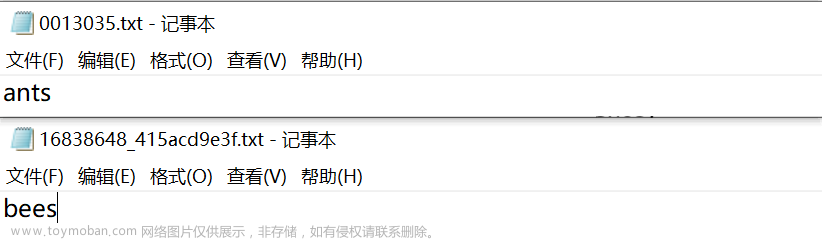
1、创建python文件,与数据集dataset同一路径下
2、对divide_data.py进行编辑文章来源:https://www.toymoban.com/news/detail-654068.html
import os
root_dir = "dataset/train"
# 原训练集的标签
label1 = "ants"
label2 = "bees"
# 训练文件夹下的原始文件夹ants和bees
original_dir1 = os.path.join(root_dir, "ants")
original_dir2 = os.path.join(root_dir, "bees")
# 将原始文件夹名称分别改为ants_image和bees_image
target_dir1 = os.path.join(root_dir, "ants_image")
target_dir2 = os.path.join(root_dir, "bees_image")
# 获取标签并创建的标签文件夹ants_label和bees_label
target_label_dir1 = os.path.join(root_dir, "ants_label")
target_label_dir2 = os.path.join(root_dir, "bees_label")
"""
判断是否存在文件夹:
1、如果存在ants和bees,就将它们改为ants_image和bees_image
2、判断是否存在ants_label和bees_label,如果不存在就创建文件夹
"""
if os.path.exists(target_dir1):
print(f'{target_dir1}已存在')
else:
if os.path.exists(original_dir1):
os.rename(original_dir1, target_dir1)
print(f'{original_dir1}已修改为{target_dir1}')
if os.path.exists(target_dir2):
print(f'{target_dir2}已存在')
else:
if os.path.exists(original_dir2):
os.rename(original_dir2, target_dir2)
print(f'{original_dir1}已修改为{target_dir1}')
if os.path.exists(target_label_dir1):
print(f'{target_label_dir1}已存在')
else:
os.mkdir(target_label_dir1)
print(f'已成功创建{target_label_dir1}')
if os.path.exists(target_label_dir2):
print(f'{target_label_dir2}已存在')
else:
os.mkdir(target_label_dir2)
print(f'已成功创建{target_label_dir2}')
"""
将图片的label保存在以图片名命名的txt文件中:
1、获取ants_image和bees_image中的图片名
2、以每张图片名来命名txt文件,将其保存在ants_label和bees_label中
"""
img_path1 = os.listdir(target_dir1)
img_path2 = os.listdir(target_dir2)
def write_txt(img_path, target_label_dir, label):
for name in img_path:
file_name = name.split('.jpg')[0]
with open(os.path.join(target_label_dir, "{}.txt").format(file_name), 'w') as f:
f.write(label)
print(f'已成功写入{target_label_dir}')
write_txt(img_path1, target_label_dir1, label1)
write_txt(img_path2, target_label_dir2, label2)
3、运行py文件python divide_data.py 文章来源地址https://www.toymoban.com/news/detail-654068.html
文章来源地址https://www.toymoban.com/news/detail-654068.html
到了这里,关于将单个训练数据集文件拆分为:image文件和label文件(pytorch学习+蚂蚁蜜蜂数据集)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!