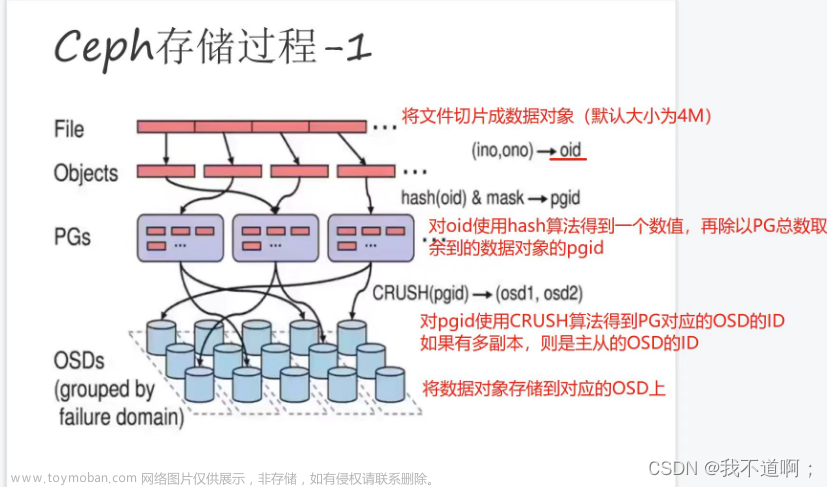
ceph的存储是无主结构,数据分布依赖client来计算,有两个条主要路径。
1、数据到PG
2、PG 到OSD
有两个假设: 第一,pg的数量稳定,可以认为保持不变; 第二, OSD的数量可以增减,OSD的存储空间权重不等;
由于 PG的数量保持不变,由数据来找PGID的环节可以简单处理,对数据的key来取hash值再对pg的总数取模即可唯一确认pgid,pgid=hash(data_key)/pg_num。
难点在于从PG到OSD,如果直接用 hash(pgid)/osd_num的模式,则OSD有增减的时候数据就有无规律的迁移,并且也无法体现OSD的不同权重。
Crush算法就是来解决这个问题的,Crush目的是随机跳出一个OSD,并且要满足权重越大的OSD,挑中的概率越大。
每个OSD有不同的容量,比如是4T还是12T的容量,可以根据每个OSD的容量定义它的权重,以T为单位, 比如4T权重设为4,12T则设为12。
如何将PG映射到不同权重的OSD上面?这里可以直接采用CRUSH里面的Straw抽签算法。

核心步骤:
1)计算HASH
draw = CRUSH_HASH( PG_ID, OSD_ID, r ),其中把r当做一个常数,将PG_ID, OSD_ID一起作为输入,得到一个HASH值。
2)增加OSD权重
osd_straw =( draw &0xffff ) * osd_weight
draw &0xffff 得到一个0-65535的数字,再与OSD的权重相乘,以这个作为每个OSD的签长, 权重越大的,数值越大。
3)遍历选取最高的权重
high_draw
Crush所计算出的随机数,是通过HASH得出来,可以保障相同的输入会得出同样的输出结果。
这里只是计算得出了一个OSD,在Ceph集群中是会存在多个副本,如何解决一个PG映射到多个OSD的问题?
将常量r加1, 再去计算一遍,如果和之前的OSD编号不一样, 那么就选取它;如果一样的话,那么再把r+2,再重新计算,直到选出三个不一样的OSD编号。
如果样本容量足够大, 随机数对选中的结果影响逐渐变小, 起决定性的是OSD的权重,OSD的权重越大, 被挑选的概率也就越大。
样本容量足够大,到底是多大? 到底多大才能按照尽可能按照权重来分布,当然是尽量小的样本才好。
样本容量主要由PG和OSD的数量多少来决定,其中最关键的还是OSD数量,如果OSD很少(比如5块盘)也能尽量按照权重分布才好。
PG的数量主要是根据数据预估和OSD的数量来定,有个理论参考数,PG数量 =(OSD数量* 100)/副本数,但是PG数量少影响后面的扩容,太多又占用过多资源,需要有一个平衡。
基于上述考虑,写了一个很简单的程序来验证下数据分布平衡性。
假定OSD数量为5并且权重随机,PG的数量为5000。
结果1:
1.随机生成5个OSDID和对应权重
OSDID=I0N@6nt5pOhjY$g;权重=32.0
OSDID=.nIjl%3zs3aoE7K;权重=16.0
OSDID=S5O9bSS4NMo%qDN;权重=1.0
OSDID=t$lZF91ofuvOKcn;权重=24.0
OSDID=!E2Ia8XE^Jzb5Dz;权重=12.0
2.在pg数量为5000的时候,PG的分布结果:
OSDID=!E2Ia8XE^Jzb5Dz;权重=12.0;拥有的PG数量=625
OSDID=I0N@6nt5pOhjY$g;权重=32.0;拥有的PG数量=2682
OSDID=t$lZF91ofuvOKcn;权重=24.0;拥有的PG数量=1554
OSDID=.nIjl%3zs3aoE7K;权重=16.0;拥有的PG数量=139
结果2:
1.随机生成5个OSDID和对应权重
OSDID=C%EN$UM!e8nZy.R;权重=1.0
OSDID=1iTDBnZeeQ6^Uos;权重=32.0
OSDID=%EMc6a4V5cWi%7D;权重=2.0
OSDID=M7WKDUjLrQaV42D;权重=64.0
OSDID=7OVTO@l$XLE$OV$;权重=8.0
2.在pg数量为5000的时候,PG的分布结果:
OSDID=1iTDBnZeeQ6^Uos;权重=32.0;拥有的PG数量=1201
OSDID=7OVTO@l$XLE$OV$;权重=8.0;拥有的PG数量=18
OSDID=M7WKDUjLrQaV42D;权重=64.0;拥有的PG数量=3781
结果3:
1.随机生成5个OSDID和对应权重
OSDID=TSvabIIG#9IssWW;权重=12.0
OSDID=XglajmN2q3f5qRI;权重=0.8
OSDID=ZEeeX^Wp9tHaxuA;权重=0.5
OSDID=PSiiRAwddyc^ThW;权重=32.0
OSDID=nPI^YbDr0ttVzGa;权重=8.0
2.在pg数量为5000的时候,PG的分布结果:
OSDID=nPI^YbDr0ttVzGa;权重=8.0;拥有的PG数量=319
OSDID=PSiiRAwddyc^ThW;权重=32.0;拥有的PG数量=3816文章来源:https://www.toymoban.com/news/detail-654376.html
OSDID=TSvabIIG#9IssWW;权重=12.0;拥有的PG数量=865文章来源地址https://www.toymoban.com/news/detail-654376.html
package com.test.zhangzk.crush;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Random;
public class TestCephCrush {
static String str = "abcdefghijklmnopqrstuvwxyzABCDEDFGHIJKLMNOPQRSTUVWXYZ0123456789.@!#$%^&*";
static Float[] factories =new Float[] {0.25f,0.5F,0.8f,1f,2f,4f,8f,12f,16f,20f,24f,32f,64f};
static int pgidCount = 5000;
static int osdCount = 5;
public static void main(String[] args) {
List<String> pgidList = getRandomPgIdList(pgidCount);
List<OSDBean> osdList = getRandomOSDIdList(osdCount);
HashMap<String,Integer> keyCount = new HashMap<String,Integer>();
for(int i=0;i<pgidCount;i++) {
float maxStraw = 0.0f;
float osdFactor = 0.0f;
String osdId = "";
for( int j=0;j<osdCount;j++) {
String key = pgidList.get(i) + osdList.get(j);
int hashCode = key.hashCode() & 0xffff;
float straw = hashCode * osdList.get(j).getFactor();
if( maxStraw < straw) {
maxStraw = straw;
osdFactor = osdList.get(j).getFactor();
osdId = osdList.get(j).getId();
}
}
String key = "OSDID="+osdId + ";权重=" + osdFactor;
Integer v = keyCount.get(key);
if( v == null ) {
keyCount.put(key, 1);
}else {
keyCount.put(key, v+1);
}
}
System.out.println("2.在pg数量为" + pgidCount +"的时候,PG的分布结果:");
for(String k:keyCount.keySet()){
System.out.println(k + ";拥有的PG数量=" +keyCount.get(k));
}
}
private static List<String> getRandomPgIdList(int pgidCount){
// TODO Auto-generated method stub
List<String> pgidList = new ArrayList<String>();
java.util.Random r = new Random(System.currentTimeMillis());
for( int i=0;i<pgidCount;i++) {
StringBuilder sb = new StringBuilder();
for( int j=0;j<10;j++) {
sb.append(str.charAt(r.nextInt(str.length()-1)));
}
pgidList.add(sb.toString());
}
return pgidList;
}
private static List<OSDBean> getRandomOSDIdList(int osdCount){
System.out.println("1.随机生成"+ osdCount + "个OSDID和对应权重");
// TODO Auto-generated method stub
List<OSDBean> osdList = new ArrayList<OSDBean>();
java.util.Random r = new Random(System.currentTimeMillis());
for( int i=0;i<osdCount;i++) {
StringBuilder sb = new StringBuilder();
for( int j=0;j<15;j++) {
sb.append(str.charAt(r.nextInt(str.length()-1)));
}
OSDBean osd = new OSDBean();
osd.setId(sb.toString());
osd.setFactor(factories[r.nextInt(factories.length)]);
System.out.println( "OSDID=" + sb.toString()+ ";权重="+ osd.getFactor() );
osdList.add(osd);
}
return osdList;
}
}
class OSDBean {
private String id;
private float factor;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public float getFactor() {
return factor;
}
public void setFactor(float factor) {
this.factor = factor;
}
}
到了这里,关于ceph数据分布的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!