分布式
定义
分布式是指将一个系统或应用程序分散到多个计算机或服务器上进行处理和管理的技术。它是指多个系统协同合作完成一个特定任务的系统。例如,可以将一个大业务拆分成多个子业务,每个子业务都是一套独立的系统,子业务之间相互协作最终完成整体的大业务。这样可以提高系统的可扩展性、可靠性和性能。
例:
搜索引擎需要处理海量的数据,包括网页内容、用户查询和搜索结果。为了提高性能和可靠性,搜索引擎通常采用分布式架构。例如,网页内容可以存储在多个服务器上,每个服务器负责一部分数据。当用户提交查询时,查询会被发送到多个服务器上进行处理,并将结果汇总返回给用户。这样可以提高搜索速度,并且即使某个服务器出现故障,也不会影响整个系统的运行。
优点
1.可用性(容错性):分布式计算系统中的一个重要的优点是可靠性。一台服务器的系统崩溃并不影响到其余的服务器,仍可以正常对外提供服务。
2.可扩展性:可以通过线性的增加机器资源,来应对不断增长的外部需求。
3.资源共享:共享数据是必不可少的应用,如银行,预订系统。
4.灵活性:由于该系统是非常灵活的,它很容易安装,实施和调试新的服务。
5.更快的速度:多地部署,将用户请求按地理路由到最近机房处理。拥有多台计算机的计算能力,使得它比其他系统有更快的处理速度。
6.开放系统:由于它是开放的系统,本地或者远程都可以访问到该服务。
7.更高的性能:相较于集中式计算机网络集群可以提供更高的性能(及更好的性价比)。
不足
1.复杂性:分布式系统最大的问题是复杂性。数据可能丢失、陈旧、出错,如何让系统容纳这些问题,对外保证数据的正确性,需要相当复杂的设计。
2.数据一致性:考虑到大量的机器故障:宕机、重启、关机,数据可能丢失、陈旧、出错,如何让系统容纳这些问题,对外保证数据的正确性,需要相当复杂的设计。
3.网络和通信故障:网络的不可靠,消息可能丢失、早到、迟到、Hang住,这给机器间的协调带来了极大的复杂度。像TCP等网络基础协议,能解决部分问题,但更多的需要系统层面自己处理。更不用说,开放式网络上可能存在的消息伪造。
4.管理复杂度:机器数量到达一定数量级时,如何对他们进行有效监控、收集日志、负载均衡,都是很大挑战。
5.延迟:网络通信延迟要比机器内通信高出几个数量级,而组件越多、网络跳数越多,延迟便会更高,这些最终都会作用于系统对外服务质量上。
集群
集群是指一组相互独立的计算机,它们通过高速网络互联,构成了一个组回,并以单一系统的模式加以管理。集群配置是用于提高可用性和可缩放性。简单地说,集群就是指一组(若干个)相互独立的计算机,利用高速通信网络组成的一个较大的计算机服务系统,每个集群节点(即集群中的每台计算机)都是运行各自服务的独立服务器。
例:
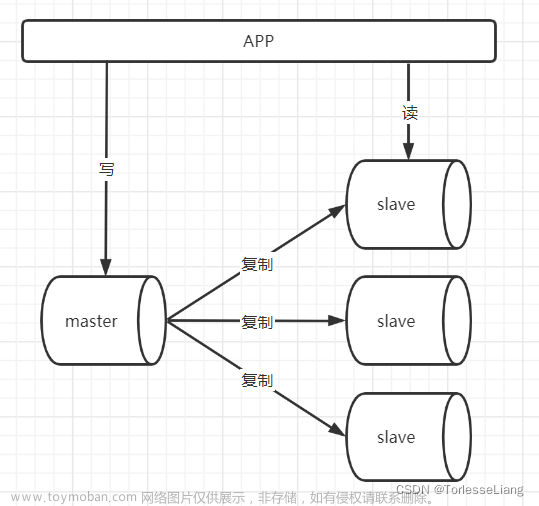
数据库集群是一种常见的集群应用。数据库集群通常由多个数据库服务器组成,每个服务器都存储着相同的数据。当用户提交查询时,查询会被发送到多个服务器上进行处理,并将结果汇总返回给用户。这样可以提高查询速度,并且即使某个服务器出现故障,也不会影响整个系统的运行。
高性能计算集群也是常用的集群。高性能计算集群通常用于科学计算、工程模拟和其他需要大量计算能力的应用。它由多个计算节点组成,每个节点都具有高性能的处理器和内存。当用户提交计算任务时,任务会被分配到多个节点上进行并行处理,以提高计算速度。
网页服务器集群是一种负载均衡集群,它将传入的请求分配到多个运行相同程序或具有相同内容的节点之间。这样可以防止任何单个节点接收到过多的任务。这种分配通常用于Web托管环境1。例如,当用户访问一个网站时,请求会被发送到集群中的一个节点上进行处理,并将结果返回给用户。这样可以提高网页加载速度,并且即使某个节点出现故障,也不会影响整个系统的运行。
优点
1.强扩展能力:其他扩展技术,通常仅能支几十个CPU的扩展,扩展能力有限,而采用集群技术的集群系统则可以扩展到包括成百上千个CPU的多台服务器,扩展能力具有明显优势。集群服务还可不断进行调整,以满足不断增长的应用需求。当集群的整体负荷超过集群的实际能力时,还可以添加额外的节点。
2.实现方式容易:服务器集群技术相对其他扩展技术来说更加容易实现,主要是通过软件进行的。在硬件上可以把多台性能较低、价格便宜的服务器,通过集群服务集中连接在一起即可实现整个服务器系统成倍,甚至几十几百倍地增长。无论是从软硬件构成成本上来看,还是从技术实现成本上来看,都较其他扩展方式更低。
3.高可用性:使用集群服务拥有整个集群系统资源的所有权,如磁盘驱动器和IP地址将自动地从有故障的服务器上转移到可用的服务器上。当集群中的系统或应用程序出现故障时,集群软件将在可用的服务器上重启失效的应用程序,或将失效节点上的工作分配到剩余的节点上。在切换过程中,用户只是觉得服务暂时停顿了一下。
4.易管理性:可使用集群管理器来管理集群系统的所有服务器资源和应用程序,就像它们都运行在同一个服务器上一样。可以通过拖放集群对象,在集群里的不同服务器间移动应用程序,也可以通过同样的方式移动数据,还可以通过这种方式来手工地平衡服务器负荷、卸载服务器,从而方便地进行维护。同时,还可以从网络的任意地方的节点和资源处,监视集群的状态。当失效的服务器连回来时,将自动返回工作状态,集群技术将自动在集群中平衡负荷,而不需要人工干预。
不足
切换时间:
集群中的应用只在一台服务器上运行,如果这个应用出现故障,则其它某台服务器会重新启动这个应用,并接管位于共享磁盘柜上的数据区以使应用重新正常运转。
整个应用接管过程大体需要三个步骤:侦测并确认故障、后备服务器重新启动该应用、接管共享数据区。因此,在切换过程中需要花费一定时间。原则上根据应用大小不同切换时间也会不同;越大的应用切换时间越长。
异同
简单来说,集群是一个系统,而分布式是一种工作方式。
集群是一种物理形态,它指的是多台计算机组成的一个整体,这些计算机可以协同工作,共同完成一个任务。而分布式是一种工作方式,它指的是将一个任务分解成多个子任务,由多台计算机分别完成这些子任务。集群和分布式都旨在提高系统的可靠性、可扩展性和性能,但它们实现这些目标的方式不同。集群通过将多台计算机组成一个单一系统来实现这些目标,而分布式则通过将一个系统或应用程序分散到多个计算机或服务器上进行处理和管理来实现这些目标。文章来源:https://www.toymoban.com/news/detail-654750.html
因此,集群和分布式有着本质的区别。集群侧重于提高单位时间内执行的任务数来提升效率,而分布式则侧重于缩短单个任务的执行时间来提升效率。文章来源地址https://www.toymoban.com/news/detail-654750.html
到了这里,关于分布式与集群的定义及异同的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!




![Linux分布式应用 Zabbix监控配置[添加主机 自定义监控内容 邮件报警 自动发现/注册 代理服务器 高可用集群]](https://imgs.yssmx.com/Uploads/2024/02/549874-1.png)