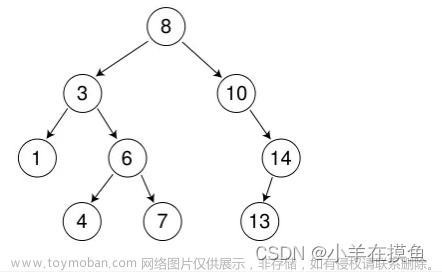
本章代码:二叉搜索树
🌲1.二叉搜索树概念
二叉搜索树又叫二叉排序树,它具有以下性质:
- 若左子树不为空,则左子树上所有结点的值都小于根结点的值
- 若右子树不为空,则右子树上所有结点的值都大于根结点的值
- 它的左右子树也分别为二叉搜索树

这个结构的时间复杂度为一般人会以为是O(logN),因为它每次都是往下一层,所以最多为二叉树的度,有n个结点的满二叉树的深度为log2(n+1)。但是实际上它的最坏情况可能是一颗斜树,这就等同于按顺序查找,时间复杂度为O(N)。所以我们按照最坏的情况来计算,二叉搜索的时间复杂度为O(N)

🌳2. 二叉搜索树操作
🌿2.1 结构定义
template<class K>
struct BSTreeNode
{
K _key; //数据
BSTreeNode<K>* _left; //左孩子
BSTreeNode<K>* _right; //右孩子
BSTreeNode(const K& key) //初始化
:_key(key)
, _left(nullptr)
, _right(nullptr)
{}
};
template<class K>
class BSTree
{
typedef BSTreeNode<K> Node;
public:
BSTree()
:_root(nullptr)
{}
private:
Node* _root; //结点
🌿2.2 插入操作
插入流程较简单,即:
- 若结点为空,则新增节点,将值赋给
root - 若不为空,则按照左子树小于根结点,右子树大于根结点来进行插入新节点

//非递归
bool Insert(const K& key)
{
if (_root == nullptr)
{
_root = new Node(key);
return true;
}
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{
if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else
{
return false;
}
}
cur = new Node(key);
if (parent->_key < key)
{
parent->_right = cur;
}
else
{
parent->_left = cur;
}
return true;
}
//递归
bool InsertR(const K& key)
{
return _InsertR(_root, key);
}
private:
bool _InsertR(Node*& root, const K& key)
{
if (root == nullptr)
{
root = new Node(key);
return true;
}
if (root->_key < key)
{
return _InsertR(root->_right, key);
}
else if (root->_key > key)
{
return _InsertR(root->_left, key);
}
else
{
return false;
}
}
这里说明一下递归操作:
-
因为递归操作是需要传结点的,而我们的结点是私有的,外面访问不到,所以我们设一个子函数,来传结点
-
在非递归版本,我们需要记录父节点,因为我们要将树给连接上
而递归版本,我们每次传的时候,都是
root指向的左/节点
🌿2.3 查找操作
同样是按照二叉搜索树的性质来进行查找

//非递归
bool Find(const K& key)
{
Node* cur = _root;
while (cur)
{
if (cur->_key < key)
{
cur = cur->_right;
}
else if (cur->_key > key)
{
cur = cur->_left;
}
else
{
return true;
}
}
return false;
}
//递归
bool FindR(const K& key)
{
return _FindR(_root, key);
}
private:
bool _FindR(Node* root, const K& key)
{
if (root == nullptr)
return false;
if (root->_key < key)
{
return _FindR(root->_right, key);
}
else if (root->_key > key)
{
return _FindR(root->_left, key);
}
else
{
return true;
}
return false;
}
🌿2.4 删除操作
删除操作是比较复杂的,这个节点找到之后进行删除,要保证这棵树还是一个二叉搜索树。
我们分为2种情况:
-
该节点只有左孩子/右孩子(无孩子),也就是至多一个孩子
我们找到该节点之后,判断哪边空,然后再让父节点指向它的另一边,然后删掉这个节点即可

-
有2个孩子
有2个孩子的话,直接删除的话,那这颗树的顺序就打乱了,根据它的性质,我们可以交换它的左子树里面的最大元素或者右子树里面的最小元素,这样就还能保证这棵树还是搜索树

//非递归
bool Erase(const K& key)
{
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{
if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else
{
if (cur->_left == nullptr) //左边为空
{
if (cur == _root)
{
_root = cur->_right;
}
else
{
if (parent->_right == cur)
{
parent->_right = cur->_right;
}
else
{
parent->_left = cur->_right;
}
}
}
else if (cur->_right == nullptr) //右边为空
{
if (cur == _root)
{
_root = cur->_left;
}
else
{
if (parent->_right == cur)
{
parent->_right = cur->_left;
}
else
{
parent->_left = cur->_left;
}
}
}
else //左右都不为空
{
Node* ptmp = cur;
//左子树最大元素为例
Node* tmp = cur->_left;
while (tmp->_right)
{
ptmp = tmp;
tmp = tmp->_right;
}
//交换元素
std::swap(cur->_key, tmp->_key);
if (ptmp->_left == tmp)
{
ptmp->_left = tmp->_left;
}
else
{
ptmp->_right = tmp->_left;
}
cur = tmp;
}
delete cur;
return true;
}
}
return false;
}
//递归
bool EraseR(const K& key)
{
return _EraseR(_root, key);
}
private:
bool _EraseR(Node*& root, const K& key)
{
if (root == nullptr)
return false;
if (root->_key < key)
{
return _EraseR(root->_right, key);
}
else if (root->_key > key)
{
return _EraseR(root->_left, key);
}
else
{
Node* del = root;
if (root->_left == nullptr)
{
root = root->_right;
}
else if (root->_right == nullptr)
{
root = root->_left;
}
else
{
Node* tmp = root->_left;
while (tmp->_left)
{
tmp = tmp->_right;
}
std::swap(tmp->_key, root->_key);
return _EraseR(root->_left, key);
}
delete del;
return true;
}
}
🌿2.5 遍历
这里采用的是中序遍历
void InOrder()
{
_InOrder(_root);
cout << endl;
}
private:
void _InOrder(Node* root)
{
if (root == NULL)
return;
_InOrder(root->_left);
cout << root->_key << " ";
_InOrder(root->_right);
}
🌴3. 二叉搜索树应用场景
🍀3.1 K模型
K模型即只有key作为数据元素,这可用于数据匹配,例如拼写检查。
我们上面实现的就是属于k模型
🍀3.2 KV模型
KV模型,每个key码都对应一个value值,我们生活中的字典、统计人员出入等,可采用这种模型
这里只做简单的逻辑演示,以下两种演示的代码都放在开头的代码仓库了,有兴趣可以查看
字典逻辑:

次数统计:
 文章来源:https://www.toymoban.com/news/detail-655162.html
文章来源:https://www.toymoban.com/news/detail-655162.html
那本期的分享就到这里咯,我们下期在家,如果还有下期的话文章来源地址https://www.toymoban.com/news/detail-655162.html
到了这里,关于数据结构——二叉搜索树的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!