推荐:使用 NSDT场景编辑器助你快速搭建可二次编辑的3D应用场景
简短的笔记本说明
笔记本由 8 个任务组成,如下图所示。它包括建模的大多数基本步骤 - 获取数据清理、拟合、超参数调优、验证和可视化。作为捷径,我拿起笔记本并使用Soorgeon工具自动将笔记本模块化到Ploomber管道中。这会将所有依赖项提取到一个 requirements.txt 文件中,将标头分解为独立任务,并从这些模块化任务中创建管道。使用 Ploomber 的主要好处是,它允许我更快地进行实验,因为它缓存了以前运行的结果,此外,它还可以轻松地将并行作业提交到 SLURM 以微调模型。
在本地运行管道?
首先运行以下命令在本地克隆示例(如果您没有 ploomber,请先安装 Ploomber):
ploomber examples -n templates/timeseries -o ts cd ts
在本地拥有管道后,可以执行健全性检查并运行:
ploomber status
这应该显示管道的所有步骤及其状态(尚未运行),这是一个参考输出:

如果只对时序部分感兴趣,也可以在本地生成管道。接下来,我们将看到如何开始在 Slurm 集群上执行以及如何进行并行运行。
在Slurm上的编排
为简单起见,我们将向您展示如何使用 Docker 启动 SLURM 集群,但如果您有权访问现有集群,则可以使用该集群。我们创建了一个名为Soopervisor的工具,它允许我们将管道部署到SLURM和其他平台,如Kubernetes,Airflow和AWS Batch。我们将在这里遵循 Slurm 指南。
您必须有一个正在运行的 docker 代理才能启动集群,请在此处阅读有关开始使用 Docker 的更多信息。
步骤 1
创建一个 docker-compose.yml。
wget https://raw.githubusercontent.com/ploomber/projects/master/templates/timeseries/docker-compose.yml
完成后,启动群集:
docker-compose up -d
现在,我们可以通过以下命令连接到群集:
docker-compose exec slurmjupyter /bin/bash
步骤 2
现在我们在集群内部,我们需要引导它并确保我们拥有想要运行的管道。
获取引导脚本并运行它,这是引导集群的脚本:
wget https://raw.githubusercontent.com/ploomber/projects/master/templates/timeseries/start.shchmod 755 start.sh ./start.sh
获取时序管道模板:
ploomber examples -n templates/timeseries -o ts cd ts
安装要求并通过 soopervisor 添加:
ploomber install soopervisor add cluster –backend slurm
这将创建一个集群目录,其中包含 soopervisor 用于提交 Slurm 任务 (template.sh) 的模板。
我们执行 export 命令来转换管道并将作业提交到集群。完成后,我们可以在“output”文件夹中看到所有输出:
soopervisor export cluster ls -l ./output
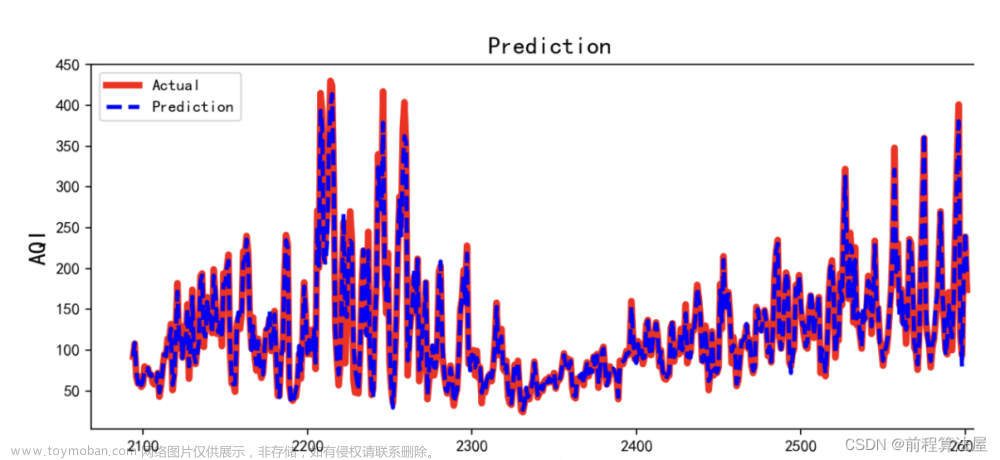
我们可以在这里看到模型生成的一些预测:


请注意,如果再次运行它,则只会运行已更改的任务(有一个缓存来管理它)。完成后,不要忘记关闭群集:
docker-compose stop
总结
此博客演示了如何将时序作为模块化管道运行,该管道可以扩展到分布式群集训练。我们从一个笔记本开始,移动到一个管道中,然后在 SLURM 集群上执行它。一旦我们度过了个人在笔记本上工作的阶段(例如团队或生产任务),确保您可以扩展、协作和可靠地执行您的工作非常重要。由于数据科学是一个迭代过程,Ploomber 为您提供了一个简单的机制来标准化您的工作并在开发和生产环境之间快速移动。文章来源:https://www.toymoban.com/news/detail-655803.html
原文链接:使用 Ploomber、Arima、Python 和 Slurm 进行时间序列预测 (mvrlink.com)文章来源地址https://www.toymoban.com/news/detail-655803.html
到了这里,关于使用 Ploomber、Arima、Python 和 Slurm 进行时间序列预测的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!