ReadPaperhttps://readpaper.com/pdf-annotate/note?pdfId=4748421678288076801¬eId=1920373270663763712 
Abstract
在本报告中,我们提出了一种快速准确的目标检测方法,称为DAMO-YOLO,它比最先进的YOLO系列实现了更高的性能。DAMO-YOLO 通过一些新技术从 YOLO 扩展,包括神经架构搜索 (NAS)、高效的重新参数化广义 FPN (RepGFPN)、具有 AlignedOTA 标签分配的轻量级头和蒸馏增强。特别是,我们使用 MAE-NAS,一种由最大熵原理指导的方法,在低延迟和高性能约束下搜索我们的检测主干,生成具有空间金字塔池和焦点模块的类似 ResNet / CSP 的结构。在颈部和头部的设计中,我们遵循“大颈部、小头部”的规则。导入具有加速后融合的广义FPN构建检测器颈部,并通过高效的层聚合网络(ELAN)和重新参数化升级其CSPNet。然后我们研究检测器头部大小会如何影响检测性能,发现只有一个任务投影层的重颈部会产生更好的结果。此外,提出了AlignedOTA来解决标签分配中的错位问题。并引入蒸馏模式以将性能提高到更高的级别。基于这些新技术,我们构建了一套不同尺度的模型,以满足不同场景的需求。对于一般行业要求,我们提出了 DAMO-YOLO-T/S/M/L。它们可以在COCO上实现43.6/47.7/50.2/51.9 mAP,在T4 GPU上延迟分别为2.78/3.83/5.62/7.95 ms。此外,对于计算能力有限的边缘设备,我们还提出了DAMO-YOLO-Ns/Nm/Nl轻量级模型。它们可以在COCO上实现32.3/38.2/40.5 mAP,在X86-CPU上延迟为4.08/5.05/6.69 ms。我们提出的通用和轻量级模型在各自的应用场景上都优于其他 YOLO 系列模型。该代码可在 https://github.com/tinyvision/damo-yolo 获得。

1. Introduction
最近,研究人员在巨大的进展中开发了对象检测方法[1,9,11,23,24,27,33]。虽然该行业追求具有实时约束的高性能目标检测方法,但研究人员专注于设计具有高效网络架构 [4,16,17,29,30] 和高级训练阶段的一级检测器 [1,22–24,26]。特别是YOLOv5/6/7[18,32,34]、YOLOX[9]和PP-YOLOE[38]在COCO上取得了显著的AP-Latency权衡,使得YOLO系列目标检测方法在工业中得到了广泛的应用。
尽管目标检测取得了很大进展,但仍有一些新技术可以进一步提高性能。首先,网络结构在目标检测中起着至关重要的作用。暗网在 YOLO 历史 [1, 9, 24- 26, 32] 的早期阶段占有主要地位。最近,一些作品调查了其他有效的网络用于它们的检测器,即 YOLOv6 [18] 和 YOLOv7。但是,这些网络仍然是手动设计的。由于神经架构搜索 (NAS) 的发展,NAS 技术 [4, 16, 30] 可以找到许多对检测友好的网络结构,这与以前的手动设计的网络相比具有很强的优越性。因此,我们利用 NAS 技术并将 MAE-NAS [30]1 导入我们的 DAMOYOLO。MAE-NAS 是一种启发式和无训练神经架构搜索方法,没有 supervised 依赖,可用于在不同尺度上存档主干。它可以生成具有空间金字塔池化和焦点模块的类似 ResNet / CSP 的结构。
其次,检测器在高级语义和低级空间特征之间学习足够的融合信息至关重要,这使得检测器颈部成为整个框架的重要组成部分。在其他著作[10,17,31,36]中也讨论了颈部的重要性。特征金字塔网络(FPN)[10]已被证明可以有效地融合多尺度特征。广义FPN (GFPN)[17]通过一种新的女王融合改进了FPN。在DAMO-YOLO,我们设计了一个重新参数化的广义FPN (RepGFPN)。它基于 GFPN,但涉及加速后融合、高效层聚合网络 (ELAN) 和重新参数化。
为了在延迟和性能之间取得平衡,我们进行了一系列实验来验证检测器颈部和头部的重要性,发现“大颈部、小头部”会导致更好的性能。因此,我们在以前的 YOLO 系列工作中丢弃了检测器头 [1, 9, 24-26, 32, 38],但只留下任务投影层。保存的计算被移动到颈部部分。除了任务投影模块外,头部没有其他训练层,因此我们将检测器头命名为 ZeroHead。结合我们的 RepGFPN,ZeroHead 实现了最先进的性能,我们相信这将为其他研究人员提供一些见解。
此外,与静态标签分配[43]相比,OTA[8]和TOOD[7]等动态标签分配得到了广泛的宣称,取得了显著的改进。然而,这些工作仍未解决错位问题。我们提出了一种名为 AlignOTA 的更好解决方案来平衡分类和回归的重要性,这可以部分解决这个问题。
最后,知识蒸馏 (KD) 已被证明在通过更大的模型监督来增强小型模型方面是有效的。该技术完全符合实时目标检测的设计。然而,在 YOLO 系列上应用 KD 有时并不能取得显着的改进,因为超参数很难优化,并且特征携带太多噪声。在我们的 DAMO-YOLO 中,我们首先在所有大小的模型上再次进行蒸馏,尤其是在小型模型上。
如图1所示,通过上述改进,我们提出了一系列通用和轻量级的模型,大大超过了现有技术。总之,贡献有三方面:
1.本文提出了一种新的检测器DAMOYOLO,它扩展了YOLO,但有了更多的新技术,包括MAE-NAS主干、RepGFPN颈部、ZeroHead、AlignedOTA和蒸馏增强。
2. DAMO-YOLO 在通用类别和轻量级类别的公共 COCO 数据集上优于最先进的检测器(例如 YOLO 系列)。
3.DAMO-YOLO (tiny/small/medium)提出了一套不同尺度的模型来支持不同的部署。代码和预训练模型在 https://github.com/tinyvision/damooyolo 上发布,支持 ONNX 和 TensorRT。

图 2. MAE-NAS 的不同构建块。(a) MobBlock是MobileNetV3块的变体,是DAMO-YOLO中轻量级模型的基本块。(b) ResBlock 源自 ResNet。DMO-YOLO-S 和 DMO-YOLO-T 建立在它之上。(c) CSPBlock来源于CSPNet,由于其在深度网络中的优越性能,它被用作DAMO-YOLO-M和DAMO-YOLO-L模型中的基本块。

表3。颈部深度和宽度的消融研究。“深度”表示融合块瓶颈上的重复时间。“Width”表示特征图的通道维度。
2. DAMO-YOLO
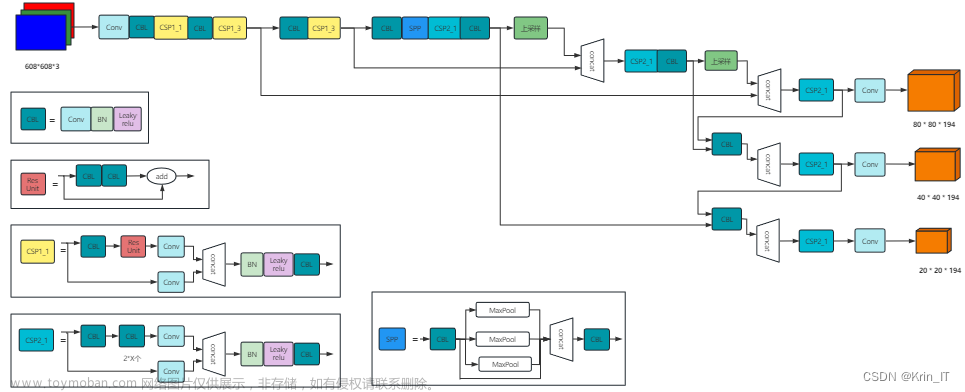
在本节中,我们将详细介绍DAMOYOLO的每个模块,包括神经架构搜索(NAS)主干、高效的重新参数化广义FPN (RepGFPN)颈部、ZeroHead、AlignedOTA标签分配和蒸馏增强。DAMO-YOLO的整个框架如图3所示。

图3。DAMO-YOLO网络架构概述。1) MAE-NAS作为骨干提取多尺度特征图;2)高效RepGFPN作为颈部,对高级语义和底层空间特征进行细化和融合;3)提出了ZeroHead,它只为每个损失包含一个任务投影层。
2.1. MAE-NAS Backbone
以前,在实时场景中,设计师依靠Flops-MAP曲线作为评估模型性能的简单方法。然而,模型的失败和延迟之间的关系不一定是一致的。为了提高模型在工业部署中的实际性能,DAMO-YOLO在设计过程中优先考虑延迟-MAP曲线。
基于这一设计原则,我们使用MAE-NAS[30]在不同的延迟预算下获得最佳网络。MAE-NAS 构建了一个基于信息论的替代代理,以在没有训练的情况下对初始化网络进行排名。因此,搜索过程只需要几个小时,远低于训练成本。MAE-NAS提供了几个基本搜索块,如Mob-block、Res-block和CSP-block,如图2所示。Mobblock是MobileNetV3[14]块的变体,Res-block来源于ResNet[12],CSP-block来源于CSPNet[35]。完整的支持块列表可以在 MAE-NAS 存储库 2 中找到。
我们发现,在不同尺度的模型中应用不同类型的块可以更好地权衡实时推理。表1列出了CSPDarknet和我们的MAE-NAS骨干在不同尺度下的性能比较。在此表中,“MAE-Res”表示我们在MAENAS主干中应用Res-block,“MAE-CSP”表示我们在其中应用CSPblock。此外,“S”(Small)和“M”(Medium)代表不同尺度的主干。如表1所示,
MAE-NAS技术获得的MAE-CSP在速度和精度方面都优于手动设计的CSP-Darknet,证明了MAE-NAS技术的优越性。此外,从表1可以观察到,在较小的模型上使用Res-block可以在性能和速度之间取得比CSP-block更好的权衡,而使用CSP-block可以在更大更深的网络上显著优于Resblock。因此,我们在最终设置中的“T”(Tiny)和“S”模型中使用“MAE-Res”,在“M”和“L”模型中使用“MAE-CSP”。在处理计算能力或 GPU 有限的场景时,拥有满足计算速度和速度严格要求的模型至关重要。为了解决这个问题,我们设计了一系列使用 Mob-Block 的轻量级模型。Mob-block来源于MobleNetV3[14],可以显著减少模型计算,对CPU设备友好。
2.2.高效RepGFPN
特征金字塔网络旨在聚合从主干中提取的不同分辨率的特征,这已被证明是目标检测的关键有效部分[10,31,36]。传统的FPN[10]引入了一种自顶向下的路径来融合多尺度特征。考虑到单向信息流的局限性,PAFPN[36]增加了一个额外的自底向上路径聚合网络,但计算成本更高。BiFPN [31] 删除了只有一个输入边的节点,并在同一级别上从原始输入中添加 skiplink。在[17]中,提出了广义FPN (GFPN)作为颈部,实现了SOTA性能,因为它可以充分交换高级语义信息和低级空间信息。在 GFPN 中,多尺度特征在前一层和当前层的两级特征融合。更重要的是,log2(n) skip-layer 连接提供了更有效的信息传输,可以扩展到更深的网络。当我们在现代 YOLO 系列模型中直接用 GFPN 替换修改后的 PANet 时,我们实现了更高的精度。然而,GFPN-的延迟基于模型远高于基于修改panet的模型。通过分析GFPN的结构,其原因可以归结为以下几个方面:1)不同尺度的特征图共享相同的信道维数;2)女王融合操作不能满足实时检测模型的要求;3)基于卷积的跨尺度特征融合效率不高。
基于 GFPN,我们提出了一种新颖的 Efficient-RepGFPN 来满足实时目标检测的设计,主要包括以下见解:1)由于不同尺度特征图的 FLOP 差异很大,在有限的计算成本约束下很难控制每个尺度特征图共享的相同维度通道。因此,在我们的颈部的特征融合中,我们采用了不同通道尺寸不同尺度特征图的设置。比较了相同和不同通道的性能以及颈部深度和宽度权衡的精度优势,表3显示了结果。我们可以看到,通过灵活控制不同尺度的通道数,我们可以达到比在所有尺度上共享相同的通道更高的精度。当深度等于 3 且宽度等于 (96, 192, 384) 时,可以获得最佳性能。2) GFPN通过女王融合增强了特征交互,但它也带来了大量额外的上采样和下采样算子。比较了这些上采样和下采样算子的优点,结果如表4所示。我们可以看到,额外的上采样算子导致延迟增加0.6ms,而精度提高仅为0.3mAP,远远小于额外的下采样算子的好处。因此,在实时检测的约束下,我们删除了女王融合的额外上采样操作。3)在特征融合块中,我们首先将原始的基于3x3的卷积特征融合替换为CSPNet,得到4.2 mAP增益。之后,我们通过结合高效层聚合网络(ELAN)[34]的重新参数化机制和连接来升级CSPNet。在不带来额外的巨大计算负担的情况下,我们实现了更高的精度。比较结果如表5所示。


2.3. ZeroHead and AlignOTA
在目标检测的最新进展中,解耦头被广泛使用[9,18,38]。使用解耦的头部,这些模型实现了更高的 AP,而延迟显着增加。为了权衡延迟和性能,我们进行了一系列实验来平衡颈部和头部的重要性,结果如表6所示。在实验中,我们发现“大颈部、小头部”会带来更好的性能。因此,我们在以前的作品 [9, 18, 38] 中丢弃了解耦的头部,但只留下任务投影层,即用于分类的线性层和用于回归的线性层。我们将头部命名为 ZeroHead,因为我们的头部没有其他训练层。ZeroHead 可以最大程度地节省大量 RepGFPN 颈部的计算。值得注意的是,ZeroHead本质上可以被认为是耦合头,这与其他作品中的解耦头有很大的不同[9,18,32,38]。在头部后的损失中,在GFocal[20]之后,我们使用质量焦点损失(QFL)进行分类监督,并使用分布焦点损失(DFL)和GIOU损失进行回归监督。QFL 鼓励学习分类和定位质量的联合表示。DFL 通过将位置建模为一般分布来提供更多信息和更精确的边界框估计。提出的DAMO-YOLO的训练损失公式为:

除了头部和损失,标签分配是检测器训练期间的至关重要的组件,负责将分类和回归目标分配给预定义的锚点。最近,OTA[8]和TOOD[7]等动态标签分配得到了广泛的宣称,与静态标签分配[43]相比,取得了显著的改进。动态标签分配方法根据预测和基本事实之间的分配成本分配标签,例如OTA[8]。虽然分类和回归在损失中的对齐已被广泛研究 [7, 20],但在目前的工作中很少提及标签分配中的分类和回归之间的对齐。分类和回归的错位是静态分配方法中的一个常见问题[43]。虽然动态分配缓解了这个问题,但由于分类和回归损失的不平衡,如CrossEntropy和IoU Loss[40]仍然存在。为了解决这个问题,我们将焦点损失 [22] 引入分类成本,并使用预测框和地面实况框的 IoU 作为软标签,公式如下:


通过这个公式,我们能够为每个目标选择分类和回归对齐样本。除了对齐的分配成本,在 OTA [8] 之后,我们从全局角度形成对齐分配成本的解决方案。我们将标签分配命名为 AlignOTA。标签分配方法的比较如表7所示。我们可以看到AlignOTA优于所有其他标签分配方法。
2.4. Distillation Enhancement(蒸馏增强)
知识蒸馏(KD)[13]是进一步提高口袋尺寸模型的性能的有效方法。然而,在 YOLO 系列上应用 KD 有时并不能取得显着的改进,因为超参数很难优化,并且特征携带太多噪声。在 DAMO-YOLO 中,我们首先在所有大小的模型上再次进行蒸馏,尤其是在小尺寸上。我们采用基于特征的蒸馏来传递黑暗知识,可以提取中间特征图[15]中的识别和定位信息。我们进行快速验证实验,为我们的DAMO-YOLO选择合适的蒸馏方法。结果如表 8 所示。我们得出结论,CWD 更适合我们的模型,而 MGD 比模仿复杂超参数更差,使其不够通用。
我们提出的蒸馏策略分为两个阶段:1)我们的老师在第一阶段(284 个 epoch)提取学生,在强大的马赛克域上。面对具有挑战性的增强数据分布,学生可以在教师指导下平滑地提取信息。2) 学生在第二阶段没有马赛克域上微调自己(16 个 epoch)。我们在这个阶段不采用蒸馏的原因是,在如此短的时间内,当老师想要将学生拉在一个奇怪的领域(即没有马赛克领域)时,老师的经验会损害学生的表现。长期蒸馏会削弱损伤,但成本很高。因此,我们选择权衡来使学生独立。
在 DAMO-YOLO 中,蒸馏配备了两个高级增强:1)对齐模块。一方面,它是一个线性投影层,使学生特征适应与教师相同的分辨率 (C, H, W )。另一方面,与自适应相比,强迫学生直接逼近教师特征和学生特征会带来很小的收益,为了削弱真实值差异带来的效果。在减去平均值后,每个通道的标准偏差将作为 KL 损失中的温度系数发挥作用。



4. Comparison with the SOTA文章来源:https://www.toymoban.com/news/detail-655892.html
DMO-YOLO 发布了一系列通用模型和轻量级模型,同时满足一般场景和资源有限的边缘场景。为了评估 DAMO-YOLO 通用模型相对于其他最先进模型的性能,我们使用 TensorRT-FP16 推理引擎对 T4-GPU 进行了比较分析。结果如表9所示,表明DAMO-YOLO的一般模型在精度和速度方面都优于竞争对手。此外,我们提出的蒸馏技术显着提高了准确性。为了评估轻量级模型的性能,我们使用 Openvino 作为推理引擎对 Intel-8163 CPU 进行了比较分析。如表2所示,DAMO-YOLO的轻量级模型取得了实质性的领先优势,在速度和准确性方面都大大超过了竞争对手。文章来源地址https://www.toymoban.com/news/detail-655892.html
到了这里,关于DAMO-YOLO:实时目标检测设计的报告的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!