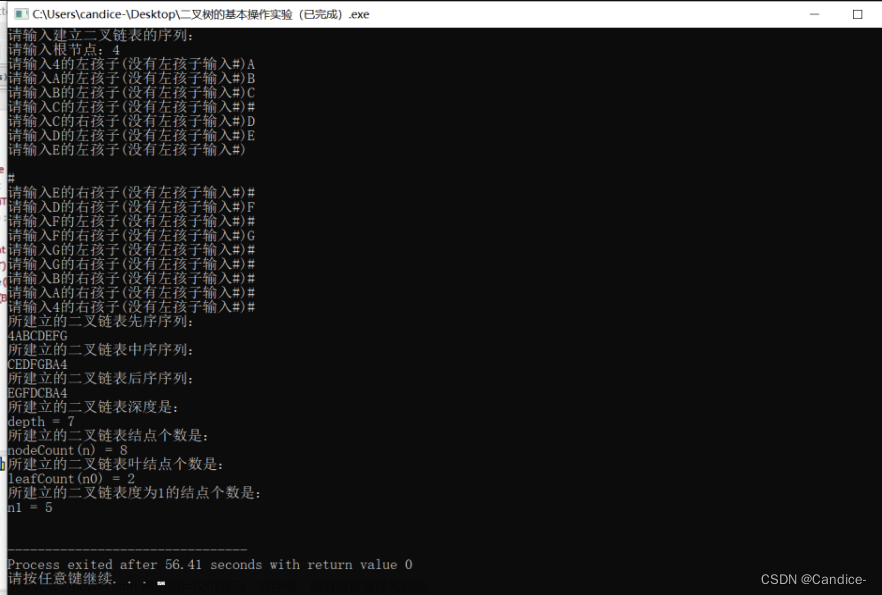
通过postgresql的Ltree字段类型实现目录结构的基本操作
将这种具有目录结构的excel表存储到数据库中,可以采用树型结构存储
DROP TABLE IF EXISTS "public"."directory_tree";
CREATE TABLE "public"."directory_tree" (
"id" varchar(100) COLLATE "pg_catalog"."default",
"path" "public"."ltree",
"name" varchar(100) COLLATE "pg_catalog"."default" NOT NULL,
"description" text COLLATE "pg_catalog"."default",
"updated_at" timestamp(6) DEFAULT now(),
"created_at" timestamp(6) DEFAULT now()
)
;
-- ----------------------------
-- Records of directory_tree
-- ----------------------------
INSERT INTO "public"."directory_tree" VALUES ('04e19944aa1d3d8bc13971b4488a4e0d', '04e19944aa1d3d8bc13971b4488a4e0d', 'root', 'root', '2023-08-09 02:11:35.145821', '2023-08-09 02:11:35.145821');
上面是建一张表,并且插入一条根节点。这里我们的id是mybatisPuls提供的UUID,并且我们的path字段采用祖id+爷id+父id+子id的结构。这是处理excel表格的工具类
package com.cdcas.utils;
import org.apache.poi.openxml4j.exceptions.InvalidFormatException;
import org.apache.poi.ss.usermodel.*;
import org.apache.poi.ss.util.CellRangeAddress;
import org.springframework.stereotype.Component;
import org.springframework.web.multipart.MultipartFile;
import java.io.File;
import java.io.IOException;
import java.util.*;
/**
* @author jiao xn
* @date 2023/4/20 22:44
* @description
*/
@Component
public class ExcelUtil {
/**
* 根据文件地址,读取指定 Excel 文件的内容,并以对象数组的方式返回
*
* @param excelFilePath Excel 文件地址
* @param sheetIndex 指定 Sheet 的索引值,从 0 开始
* @param startLine 开始读取的行:从0开始
* @param tailLine 去除最后读取的行
* @return Excel 文件内容,对象数组
*/
public List<Map<String, String>> readExcelFile(String excelFilePath, Integer sheetIndex, Integer startLine
, Integer tailLine) {
Workbook workbook = this.generateWorkbook(excelFilePath);
return this.readExcelSheetToObject(workbook, sheetIndex, startLine, tailLine);
}
/**
* 从 MultipartFile 中读取 Excel 文件的内容,并以对象数组的方式返回
*
* @param multipartFile MultipartFile 对象,一般是从前端接收
* @param sheetIndex 指定 Sheet 的索引值,从 0 开始
* @param startLine 开始读取的行:从0开始
* @param tailLine 去除最后读取的行
* @return Excel 文件内容,对象数组
*/
public List<Map<String, String>> readExcelFile(MultipartFile multipartFile, Integer sheetIndex, Integer startLine
, Integer tailLine) {
Workbook workbook = this.generateWorkbook(multipartFile);
return this.readExcelSheetToObject(workbook, sheetIndex, startLine, tailLine);
}
/**
* 生成 Workbook 对象
*
* @param excelFilePath Excel 文件路径
* @return Workbook 对象,允许为空
*/
private Workbook generateWorkbook(String excelFilePath) {
Workbook workbook;
try {
File excelFile = new File(excelFilePath);
workbook = WorkbookFactory.create(excelFile);
} catch (IOException | InvalidFormatException e) {
e.printStackTrace();
throw new RuntimeException(e);
}
return workbook;
}
/**
* 生成 Workbook 对象
*
* @param multipartFile MultipartFile 对象
* @return Workbook 对象
*/
private Workbook generateWorkbook(MultipartFile multipartFile) {
Workbook workbook;
try {
workbook = WorkbookFactory.create(multipartFile.getInputStream());
} catch (IOException | InvalidFormatException e) {
e.printStackTrace();
throw new RuntimeException(e);
}
return workbook;
}
/**
* 读取指定 Sheet 中的数据
*
* @param workbook Workbook 对象
* @param sheetIndex 指定 Sheet 的索引值,从 0 开始
* @param startLine 开始读取的行:从0开始
* @param tailLine 去除最后读取的行
* @return 指定 Sheet 的内容
*/
private List<Map<String, String>> readExcelSheetToObject(Workbook workbook,
Integer sheetIndex, Integer startLine, Integer tailLine) {
List<Map<String, String>> result = new ArrayList<>();
Sheet sheet = workbook.getSheetAt(sheetIndex);
// 获取第一行内容,作为标题内容
Row titileRow = sheet.getRow(0);
Map<String, String> titleContent = new LinkedHashMap<>();
for (int i = 0; i < titileRow.getLastCellNum(); i++) {
Cell cell = titileRow.getCell(i);
titleContent.put(cell.getStringCellValue(), cell.getStringCellValue());
}
result.add(titleContent);
// 获取正文内容
Row row;
for (Integer i = startLine; i < sheet.getLastRowNum() - tailLine + 1; i++) {
row = sheet.getRow(i);
Map<String, String> rowContent = new HashMap<>();
for (Cell cell : row) {
String returnStr;
boolean isMergedCell = this.isMergedCell(sheet, i, cell.getColumnIndex());
if (isMergedCell) {
returnStr = this.getMergedRegionValue(sheet, row.getRowNum(), cell.getColumnIndex());
} else {
returnStr = cell.getRichStringCellValue().getString();
}
rowContent.put(titileRow.getCell(cell.getColumnIndex()).getStringCellValue(), returnStr);
}
result.add(rowContent);
}
return result;
}
/**
* 判断指定的单元格是否是合并单元格
*
* @param sheet Excel 指定的 Sheet 表
* @param row 行下标
* @param column 列下标
* @return 是否为合并的单元格
*/
private boolean isMergedCell(Sheet sheet, int row, int column) {
int sheetMergeCount = sheet.getNumMergedRegions();
for (int i = 0; i < sheetMergeCount; i++) {
CellRangeAddress range = sheet.getMergedRegion(i);
int firstColumn = range.getFirstColumn();
int lastColumn = range.getLastColumn();
int firstRow = range.getFirstRow();
int lastRow = range.getLastRow();
if(row >= firstRow && row <= lastRow && (column >= firstColumn && column <= lastColumn)){
return true;
}
}
return false;
}
/**
* 获取合并单元格的值
*
* @param sheet 指定的值
* @param row 行号
* @param column 列好
* @return 合并单元格的值
*/
private String getMergedRegionValue(Sheet sheet, int row, int column){
int sheetMergeCount = sheet.getNumMergedRegions();
for(int i = 0 ; i < sheetMergeCount ; i++){
CellRangeAddress ca = sheet.getMergedRegion(i);
int firstColumn = ca.getFirstColumn();
int lastColumn = ca.getLastColumn();
int firstRow = ca.getFirstRow();
int lastRow = ca.getLastRow();
if(row >= firstRow && row <= lastRow && (column >= firstColumn && column <= lastColumn)) {
Row fRow = sheet.getRow(firstRow);
Cell fCell = fRow.getCell(firstColumn);
return this.getCellValue(fCell) ;
}
}
return null ;
}
/**
* 获取单元格的值
*
* @param cell Cell 对象
* @return 单元格的值
*/
private String getCellValue(Cell cell){
if(cell == null) {
return "";
}
if(cell.getCellTypeEnum() == CellType.STRING){
return cell.getStringCellValue();
} else if(cell.getCellTypeEnum() == CellType.BOOLEAN){
return String.valueOf(cell.getBooleanCellValue());
} else if(cell.getCellTypeEnum() == CellType.FORMULA){
return cell.getCellFormula() ;
} else if(cell.getCellTypeEnum() == CellType.NUMERIC){
return String.valueOf(cell.getNumericCellValue());
}
return "";
}
}
下面是将生成的List<Map<String, String>> excel数据插入到excel表中的工具类
package com.cdcas;
import com.cdcas.mapper.DirectoryTreeMapper;
import com.cdcas.pojo.DirectoryTree;
import com.cdcas.utils.ExcelDataUtil;
import com.cdcas.utils.ExcelUtil;
import org.junit.jupiter.api.Test;
import org.junit.platform.commons.util.StringUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.util.CollectionUtils;
import java.io.FileInputStream;
import java.util.HashSet;
import java.util.List;
import java.util.Map;
/**
* @version 1.0
* @Author zhaozhixin
* @Date 2023/8/7 15:01
* @注释
*/ //983
@SpringBootTest
public class Test2 {
/**
* 替换和插入
*
* @param parentPath
* @param directoryTree
*/
private String Insert(String parentPath, DirectoryTree directoryTree, String name) {
directoryTree.setName(name);
directoryTree.setDescription(parentPath);
directoryTreeMapper.insert(directoryTree);
directoryTree.setPath(parentPath + "." + directoryTree.getId());
directoryTreeMapper.updateDirectoryTree(directoryTree);
return directoryTree.getId();
}
/**
* 通过名称查询父路径
*
* @param name
* @return
*/
private String getParentPathByName(String name) {
DirectoryTree parent = directoryTreeMapper.getOneByName(name);
return parent.getPath();
}
@Test
public void get() {
String path = directoryTreeMapper.getPath(1);
System.out.println(path);
}
@Autowired
private ExcelUtil excelUtil;
@Autowired
private ExcelDataUtil excelDataUtil;
@Autowired
private DirectoryTreeMapper directoryTreeMapper;
@Test
public void insert() throws Exception {
//读取一个excel
List<Map<String, String>> maps = excelUtil.readExcelFile("C:\\Users\\20745\\Desktop\\git库\\gitee\\pg-demo-itree\\src\\main\\resources\\国土规划目录树.xlsx", 0, 1, 0);
maps.remove(0);
System.out.println(maps);
for (Map<String, String> map : maps) {
String A1 = map.get("A1");
String A2 = map.get("A2");
String A3 = map.get("A3");
String A4 = map.get("A4");
String A5 = map.get("A5");
String A6 = map.get("A6");
String A7 = map.get("A7");
String A8 = map.get("A8");
String A9 = map.get("A9");
StringBuilder parentPath = new StringBuilder();//用来拼接父节点id
parentPath.append("04e19944aa1d3d8bc13971b4488a4e0d");//这是根节点id
if (A1 != null && !"".equals(A1)) {
//二级节点 根节点为root
DirectoryTree directoryTree = new DirectoryTree();
String name = A1;
String id = isExtis(name, directoryTree, parentPath.toString());
if (id==null){
}else {
parentPath.append(".").append(id);
}
}
if (A2 != null && !"".equals(A2)) {
//拿到所有同名的行
DirectoryTree directoryTree = new DirectoryTree();
String name = A2;
String id = isExtis(name, directoryTree, parentPath.toString());
if (id==null){
}else {
parentPath.append(".").append(id);
}
}
if (A3 != null && !"".equals(A3)) {
DirectoryTree directoryTree = new DirectoryTree();
String name = A3;
String id = isExtis(name, directoryTree, parentPath.toString());
if (id==null){
}else {
parentPath.append(".").append(id);
}
}
if (A4 != null && !"".equals(A4)) {
DirectoryTree directoryTree = new DirectoryTree();
String name = A4;
String id = isExtis(name, directoryTree, parentPath.toString());
if (id==null){
}else {
parentPath.append(".").append(id);
}
}
if (A5 != null && !"".equals(A5)) {
DirectoryTree directoryTree = new DirectoryTree();
String name = A5;
String id = isExtis(name, directoryTree, parentPath.toString());
if (id==null){
}else {
parentPath.append(".").append(id);
}
}
if (A6 != null && !"".equals(A6)) {
DirectoryTree directoryTree = new DirectoryTree();
String name = A6;
String id = isExtis(name, directoryTree, parentPath.toString());
if (id==null){
}else {
parentPath.append(".").append(id);
}
}
if (A7 != null && !"".equals(A7)) {
DirectoryTree directoryTree = new DirectoryTree();
String name = A7;
String id = isExtis(name, directoryTree, parentPath.toString());
if (id==null){
}else {
parentPath.append(".").append(id);
}
}
if (A8 != null && !"".equals(A8)) {
DirectoryTree directoryTree = new DirectoryTree();
String name = A8;
String id = isExtis(name, directoryTree, parentPath.toString());
if (id==null){
}else {
parentPath.append(".").append(id);
}
}
if (A9 != null && !"".equals(A9)) {
DirectoryTree directoryTree = new DirectoryTree();
String name = A9;
String id = isExtis(name, directoryTree, parentPath.toString());
if (id==null){
}else {
parentPath.append(".").append(id);
}
}
}
}
/**
* 判断一个同名的是否存在在其它数 返回当前节点id
* @param name
* @param directoryTree
* @param parentPath
*/
private String isExtis(String name,DirectoryTree directoryTree,String parentPath){
//最终标识 开始表明不存在
boolean isExtis = false;
//获取到所有的和name同名的行
List<DirectoryTree> oneByNames = directoryTreeMapper.getListByName(name);
//如果没有同名的直接插入
if (CollectionUtils.isEmpty(oneByNames)){
directoryTree.setName(name);
directoryTree.setDescription(parentPath);
directoryTreeMapper.insert(directoryTree);
directoryTree.setPath(parentPath+"."+directoryTree.getId());
directoryTreeMapper.updateDirectoryTree(directoryTree);
return directoryTree.getId();
}
//如果有同名的,需要判断父路径是否相同
String path = "";
int lastIndexOf = 0;
for (DirectoryTree oneByName : oneByNames) {
if (oneByName!=null) {
path = oneByName.getPath();
lastIndexOf = path.lastIndexOf(".");
}
//重复的数据应该也要被插入进去 查出的父路径传入的父路径进行对比
if (path.substring(0,lastIndexOf).equals(parentPath)){
isExtis = true;
}
}
//最后如果同名的数据但是父路径不相同,就需要插入进去
if (!isExtis){
directoryTree.setName(name);
directoryTree.setDescription(parentPath);
directoryTreeMapper.insert(directoryTree);
directoryTree.setPath(parentPath+"."+directoryTree.getId());
directoryTreeMapper.updateDirectoryTree(directoryTree);
return directoryTree.getId();
}
return oneByNames.get(oneByNames.size()-1).getId();
}
//查看重复条数和 总条数
@Test
public void look() throws Exception {
FileInputStream fileInputStream = new FileInputStream("C:\\Users\\20745\\Desktop\\git库\\gitee\\pg-demo-itree\\src\\main\\resources\\国土规划目录树.xlsx");
List<Map<String, String>> maps = excelDataUtil.readExcel(fileInputStream);
int count = 0;
HashSet<String> set = new HashSet();
for (Map<String, String> map : maps) {
if (StringUtils.isNotBlank(map.get("A1"))) {
set.add(map.get("A1"));
count++;
}
if (StringUtils.isNotBlank(map.get("A2"))) {
set.add(map.get("A2"));
count++;
}
if (StringUtils.isNotBlank(map.get("A3"))) {
set.add(map.get("A3"));
count++;
}
if (StringUtils.isNotBlank(map.get("A4"))) {
set.add(map.get("A4"));
count++;
}
if (StringUtils.isNotBlank(map.get("A5"))) {
set.add(map.get("A5"));
count++;
}
if (StringUtils.isNotBlank(map.get("A6"))) {
set.add(map.get("A6"));
count++;
}
if (StringUtils.isNotBlank(map.get("A7"))) {
set.add(map.get("A7"));
count++;
}
if (StringUtils.isNotBlank(map.get("A8"))) {
set.add(map.get("A8"));
count++;
}
if (StringUtils.isNotBlank(map.get("A9"))) {
set.add(map.get("A9"));
count++;
}
}
System.out.println(count);
System.out.println(set.size());
}
}
最后插入的数据大概是这样
注意这里的path!!!!!是id拼起来的具有目录层次的!! 文章来源:https://www.toymoban.com/news/detail-656097.html
文章来源:https://www.toymoban.com/news/detail-656097.html
这些关于目录树的基本操作,楼主写了一个小demo放在gitee上面了。本人不会算法,里面写的很菜见谅哈哈。喜欢的点个赞谢谢<.>! gitee地址:pg-demo-itree: 基于postgresql的Itree功能实现目录树的操作 (gitee.com)文章来源地址https://www.toymoban.com/news/detail-656097.html
到了这里,关于通过postgresql的Ltree字段类型实现目录结构的基本操作的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!