1、kafka简介
Kafka是一个流行的分布式消息系统,它的核心是一个由多个节点组成的分布式集群。在Kafka中,数据被分割成多个小块,并通过一些复杂的算法在节点之间传递。这些小块被称为Kafka Topic。
2、topic知识
一个Topic是一组具有相同主题的消息。可以将Topic看作是一个数据仓库,在这个仓库中存储着具有相同主题的数据。比如,一个Topic可以存储所有关于“股票”的数据,另一个Topic可以存储所有关于“天气”的数据。
Kafka Topic的设计非常简单,但是它的功能却非常强大。Kafka Topics可以实现数据的发布、订阅和消费。在发布数据时,可以将数据放到一个Topic中,其他节点可以订阅这个Topic,并且获取其中的数据。在订阅数据时,可以将一个Topic的地址放到消费者的地址中,这样消费者就可以获取到该Topic中的数据。
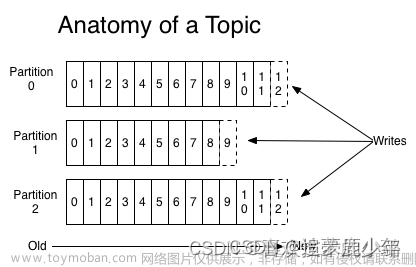
Kafka Topis的数据结构非常特殊,它是一个由多个分区组成的集合。每个分区都是一个独立的数据流,并且可以使用不同的策略来处理数据的分配和复制。这种数据结构可以提高数据的可靠性和安全性,并且可以支持大规模的数据传输。
Kafka Topic的分区结构非常重要,它可以将数据分成多个部分,并且可以使用不同的策略来处理数据的分配和复制。每个分区都有一个唯一的标识符,叫做分区ID。可以使用不同的分区ID来创建多个分区,每个分区可以存储不同的数据。
3、简单使用
在使用Kafka Topics时,需要注意一些事项。首先,要创建一个Topic,并且指定该Topic的主题和相关参数。其次,要创建一些消费者,并且将它们添加到该Topic的订阅列表中。最后,当数据被发布到Topic中时,消费者会自动订阅这个Topic,并且获取其中的数据。
首先,您需要在项目中添加 Kafka 依赖项:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.8.0</version>
</dependency>
然后,您需要编写一个生产者,以将消息发布到指定的主题中:
在创建Topic时,可以指定该Topic的分区数和每个分区的大小。分区数表示要将数据分成多少个部分,每个部分可以使用不同的策略来处理数据的分配和复制。每个分区的大小表示每个部分可以存储多少数据。
package com.yinfeng.test.demo.kafka;
import lombok.SneakyThrows;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
/**
* @author admin
* @date 2023/7/2 19:02
* @description
*/
public class KafkaProducerDemo {
@SneakyThrows
public static void main(String[] args) {
Properties props = new Properties();
// Kafka 集群地址
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
// 发送3条消息
for (int i = 0; i < 3; i++) {
ProducerRecord<String, String> record1 = new ProducerRecord<>("test", "key"+i, "hello"+i);
producer.send(record1, (metadata, exception) -> {
System.out.println("消息发送成功 topic="+metadata.topic()+", msg=>" + record1.value());
});
}
// kafka异步发送,延时等待执行完成
Thread.sleep(5000);
}
}

当数据被发布到Topic中时,可以将数据放到一个Topic中,其他节点可以订阅这个Topic,并且获取其中的数据。订阅一个Topic的过程可以用以下代码表示:
在消费Topic中的数据时,需要指定要消费的主题名称和消费者的地址。消费者的地址包括一个主机名和一个端口号,以及一个唯一的标识符,叫做消费者ID。消费者ID可以使用环境变量来设置,也可以在消费者的地址中直接指定。
package com.yinfeng.test.demo.kafka;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
/**
* @author admin
* @date 2023/7/2 19:02
* @description
*/
public class KafkaConsumerDemo {
public static void main(String[] args) {
Properties props = new Properties();
// Kafka 集群地址
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "my_group");
props.put("auto.offset.reset", "earliest");
props.put("enable.auto.commit", "true");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props, new StringDeserializer(), new StringDeserializer());
consumer.subscribe(Collections.singleton("test"));
// 循环拉取消息
while (true){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
System.out.println("Received message: " + record.value());
}
}
}
}

在上面的代码中,我们首先创建了一个Kafka集群,然后创建了一个Topic,并且指定了该Topic的分区ID。接着,我们创建了一个Kafka集群,并且指定了该Topic的分区ID。接着,我们创建了一个消费者,并且将该消费者添加到该Topic的订阅列表中。最后,我们使用该消费者来消费该Topic中的数据。
在消费数据时,我们使用了Kafka提供的ConsumerRecords类来获取数据。我们首先使用该类的poll方法来获取一个消费者的数据,然后使用该类的其他方法来对数据进行处理。
在设置消费者的偏移量时,我们使用了Kafka提供的OffsetRequest类来向Kafka集群中提交消费者的偏移量。我们首先创建了一个OffsetRequest对象,然后使用该类的setOffset方法来将该对象设置为要求的偏移量。最后,我们调用该类的commitSync方法来提交该偏移量。不过由于我们设置自动提交,所以这步可以不用操作。
4、注意事项
在使用Kafka Topics时,还需要注意一些其他的事项。
例如,在创建Topic时,可以指定该Topic的备份策略,以确保数据的可靠性和安全性。备份策略包括多种不同的方法,如备份到本地文件、备份到数据库、备份到其他Kafka集群等。
另外,在使用Kafka Topics时,还可以使用Kafka提供的一些API和工具来对Topic进行操作和管理。例如,可以使用Kafka提供的AdminClient来管理Kafka集群中的所有Topic,可以使用Kafka提供的ConsumerGroupClient来管理Kafka集群中的所有ConsumerGroup,可以使用Kafka提供的KafkaConsumer来消费Kafka集群中的数据等。文章来源:https://www.toymoban.com/news/detail-656313.html
总之,Kafka Topics是Kafka中非常重要的一个概念,它可以实现数据的发布、订阅和消费。在使用Kafka Topics时,需要注意一些事项,以确保数据的可靠性和安全性。文章来源地址https://www.toymoban.com/news/detail-656313.html
到了这里,关于(五)kafka从入门到精通之topic介绍的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!