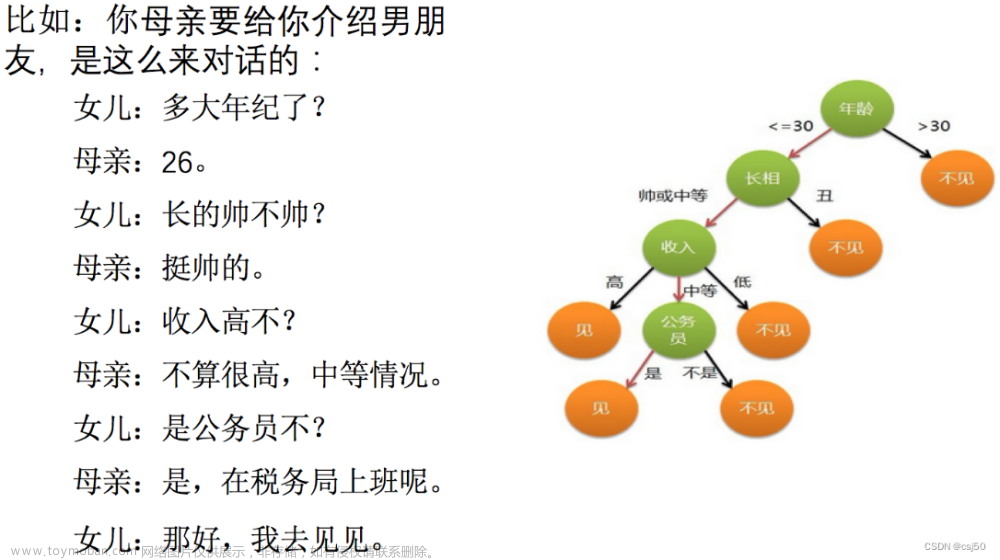
作用是如何选择出最好的K值
一、什么是交叉验证(cross validation)
1、定义
交叉验证:将拿到的训练数据,分为训练和验证集。以下图为例:将数据分成5份,其中一份作为验证集。然后经过5次(组)的测试,每次都更换不同的验证集。即得到5组模型的结果,取平均值作为最终结果。又称5折交叉验证
把训练集本身再分
2、分析
我们之前知道数据分为训练集和测试集,但是为了让从训练得到模型结果更加准确。做以下处理:
(1)训练集:训练集+验证集
(2)测试集:测试集
二、超参数搜索-网格搜索(Grid Search)
1、什么是超参数
通常情况下,有很多参数是需要手动指定的(如k-近邻算法中的K值),这种叫超参数。但是手动过程繁杂,所以需要对模型预设几种超参数组合。每组超参数都采用交叉验证来进行评估。最后选出最优参数组合建立模型
k的取值
[1, 3, 5, 7, 9, 11]
遍历,for循环一个一个试
网格搜索其实就是在帮我们自动做这些事情,不需要自己写for循环了
三、模型选择与调优API
1、sklearn.model_selection.GridSearchCV(estimator, param_grid=None, cv=None)
对估计器的指定参数值进行详尽搜索,GridSearchCV:grid网格,search搜索,CV交叉验证
参数:
estimator:估计器对象
param_grid:估计器参数,将我们准备好的,比如k的取值,以字典的形式传进来(dict){“n_neighbors”:[1,3,5]}
cv:指定几折交叉验证,最常用的是10折
2、fit()方法
输入训练数据,得出模型
3、score()方法
模型训练好之后,求准确率
4、查看哪个结果是比较好的
最佳参数:best_params_
最佳结果:best_score_
最佳估计器:best_estimator_
交叉验证结果:cv_results_
四、鸢尾花案例增加K值调优
1、添加代码
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
def KNN_iris():
"""
用KNN算法对鸢尾花进行分类
"""
# 1、获取数据
iris = load_iris()
print("iris.data:\n", iris.data)
print("iris.target:\n", iris.target)
# 2、划分数据集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=6)
# 3、特征工程:标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
# 用训练集的平均值和标准差对测试集的数据来标准化
# 这里测试集和训练集要有一样的平均值和标准差,而fit的工作就是计算平均值和标准差,所以train的那一步用fit计算过了,到了test这就不需要再算一遍自己的了,直接用train的就可以
x_test = transfer.transform(x_test)
# 4、KNN算法预估器
estimator = KNeighborsClassifier(n_neighbors=3)
estimator.fit(x_train, y_train)
# 5、模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)
# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
return None
def KNN_iris_gscv():
"""
用KNN算法对鸢尾花进行分类,添加网格搜索和交叉验证
"""
# 1、获取数据
iris = load_iris()
print("iris.data:\n", iris.data)
print("iris.target:\n", iris.target)
# 2、划分数据集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=6)
# 3、特征工程:标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
# 用训练集的平均值和标准差对测试集的数据来标准化
# 这里测试集和训练集要有一样的平均值和标准差,而fit的工作就是计算平均值和标准差,所以train的那一步用fit计算过了,到了test这就不需要再算一遍自己的了,直接用train的就可以
x_test = transfer.transform(x_test)
# 4、KNN算法预估器
estimator = KNeighborsClassifier()
# 加入网格搜索和交叉验证
# 参数准备
param_dict = {"n_neighbors": [1, 3, 5, 7, 9, 11]}
estimator = GridSearchCV(estimator, param_grid=param_dict, cv=10)
estimator.fit(x_train, y_train)
# 5、模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)
# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
#最佳参数:best_params_
print("最佳参数:\n", estimator.best_params_)
#最佳结果:best_score_
print("最佳结果:\n", estimator.best_score_)
#最佳估计器:best_estimator_
print("最佳估计器:\n", estimator.best_estimator_)
#交叉验证结果:cv_results_
print("交叉验证结果:\n", estimator.cv_results_)
return None
if __name__ == "__main__":
# 代码1:用KNN算法对鸢尾花进行分类
#KNN_iris()
# 代码2:用KNN算法对鸢尾花进行分类,添加网格搜索和交叉验证
KNN_iris_gscv()2、运行结果文章来源:https://www.toymoban.com/news/detail-656523.html
iris.data:
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
[5. 3.6 1.4 0.2]
[5.4 3.9 1.7 0.4]
[4.6 3.4 1.4 0.3]
[5. 3.4 1.5 0.2]
[4.4 2.9 1.4 0.2]
[4.9 3.1 1.5 0.1]
[5.4 3.7 1.5 0.2]
[4.8 3.4 1.6 0.2]
[4.8 3. 1.4 0.1]
[4.3 3. 1.1 0.1]
[5.8 4. 1.2 0.2]
[5.7 4.4 1.5 0.4]
[5.4 3.9 1.3 0.4]
[5.1 3.5 1.4 0.3]
[5.7 3.8 1.7 0.3]
[5.1 3.8 1.5 0.3]
[5.4 3.4 1.7 0.2]
[5.1 3.7 1.5 0.4]
[4.6 3.6 1. 0.2]
[5.1 3.3 1.7 0.5]
[4.8 3.4 1.9 0.2]
[5. 3. 1.6 0.2]
[5. 3.4 1.6 0.4]
[5.2 3.5 1.5 0.2]
[5.2 3.4 1.4 0.2]
[4.7 3.2 1.6 0.2]
[4.8 3.1 1.6 0.2]
[5.4 3.4 1.5 0.4]
[5.2 4.1 1.5 0.1]
[5.5 4.2 1.4 0.2]
[4.9 3.1 1.5 0.2]
[5. 3.2 1.2 0.2]
[5.5 3.5 1.3 0.2]
[4.9 3.6 1.4 0.1]
[4.4 3. 1.3 0.2]
[5.1 3.4 1.5 0.2]
[5. 3.5 1.3 0.3]
[4.5 2.3 1.3 0.3]
[4.4 3.2 1.3 0.2]
[5. 3.5 1.6 0.6]
[5.1 3.8 1.9 0.4]
[4.8 3. 1.4 0.3]
[5.1 3.8 1.6 0.2]
[4.6 3.2 1.4 0.2]
[5.3 3.7 1.5 0.2]
[5. 3.3 1.4 0.2]
[7. 3.2 4.7 1.4]
[6.4 3.2 4.5 1.5]
[6.9 3.1 4.9 1.5]
[5.5 2.3 4. 1.3]
[6.5 2.8 4.6 1.5]
[5.7 2.8 4.5 1.3]
[6.3 3.3 4.7 1.6]
[4.9 2.4 3.3 1. ]
[6.6 2.9 4.6 1.3]
[5.2 2.7 3.9 1.4]
[5. 2. 3.5 1. ]
[5.9 3. 4.2 1.5]
[6. 2.2 4. 1. ]
[6.1 2.9 4.7 1.4]
[5.6 2.9 3.6 1.3]
[6.7 3.1 4.4 1.4]
[5.6 3. 4.5 1.5]
[5.8 2.7 4.1 1. ]
[6.2 2.2 4.5 1.5]
[5.6 2.5 3.9 1.1]
[5.9 3.2 4.8 1.8]
[6.1 2.8 4. 1.3]
[6.3 2.5 4.9 1.5]
[6.1 2.8 4.7 1.2]
[6.4 2.9 4.3 1.3]
[6.6 3. 4.4 1.4]
[6.8 2.8 4.8 1.4]
[6.7 3. 5. 1.7]
[6. 2.9 4.5 1.5]
[5.7 2.6 3.5 1. ]
[5.5 2.4 3.8 1.1]
[5.5 2.4 3.7 1. ]
[5.8 2.7 3.9 1.2]
[6. 2.7 5.1 1.6]
[5.4 3. 4.5 1.5]
[6. 3.4 4.5 1.6]
[6.7 3.1 4.7 1.5]
[6.3 2.3 4.4 1.3]
[5.6 3. 4.1 1.3]
[5.5 2.5 4. 1.3]
[5.5 2.6 4.4 1.2]
[6.1 3. 4.6 1.4]
[5.8 2.6 4. 1.2]
[5. 2.3 3.3 1. ]
[5.6 2.7 4.2 1.3]
[5.7 3. 4.2 1.2]
[5.7 2.9 4.2 1.3]
[6.2 2.9 4.3 1.3]
[5.1 2.5 3. 1.1]
[5.7 2.8 4.1 1.3]
[6.3 3.3 6. 2.5]
[5.8 2.7 5.1 1.9]
[7.1 3. 5.9 2.1]
[6.3 2.9 5.6 1.8]
[6.5 3. 5.8 2.2]
[7.6 3. 6.6 2.1]
[4.9 2.5 4.5 1.7]
[7.3 2.9 6.3 1.8]
[6.7 2.5 5.8 1.8]
[7.2 3.6 6.1 2.5]
[6.5 3.2 5.1 2. ]
[6.4 2.7 5.3 1.9]
[6.8 3. 5.5 2.1]
[5.7 2.5 5. 2. ]
[5.8 2.8 5.1 2.4]
[6.4 3.2 5.3 2.3]
[6.5 3. 5.5 1.8]
[7.7 3.8 6.7 2.2]
[7.7 2.6 6.9 2.3]
[6. 2.2 5. 1.5]
[6.9 3.2 5.7 2.3]
[5.6 2.8 4.9 2. ]
[7.7 2.8 6.7 2. ]
[6.3 2.7 4.9 1.8]
[6.7 3.3 5.7 2.1]
[7.2 3.2 6. 1.8]
[6.2 2.8 4.8 1.8]
[6.1 3. 4.9 1.8]
[6.4 2.8 5.6 2.1]
[7.2 3. 5.8 1.6]
[7.4 2.8 6.1 1.9]
[7.9 3.8 6.4 2. ]
[6.4 2.8 5.6 2.2]
[6.3 2.8 5.1 1.5]
[6.1 2.6 5.6 1.4]
[7.7 3. 6.1 2.3]
[6.3 3.4 5.6 2.4]
[6.4 3.1 5.5 1.8]
[6. 3. 4.8 1.8]
[6.9 3.1 5.4 2.1]
[6.7 3.1 5.6 2.4]
[6.9 3.1 5.1 2.3]
[5.8 2.7 5.1 1.9]
[6.8 3.2 5.9 2.3]
[6.7 3.3 5.7 2.5]
[6.7 3. 5.2 2.3]
[6.3 2.5 5. 1.9]
[6.5 3. 5.2 2. ]
[6.2 3.4 5.4 2.3]
[5.9 3. 5.1 1.8]]
iris.target:
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
y_predict:
[0 2 0 0 2 1 2 0 2 1 2 1 2 2 1 1 2 1 1 0 0 2 0 0 1 1 1 2 0 1 0 1 0 0 1 2 1
2]
直接比对真实值和预测值:
[ True True True True True True True True True True True True
True True True False True True True True True True True True
True True True True True True True True True True False True
True True]
准确率为:
0.9473684210526315
最佳参数:
{'n_neighbors': 11}
最佳结果:
0.9734848484848484
最佳估计器:
KNeighborsClassifier(n_neighbors=11)
交叉验证结果:
{'mean_fit_time': array([0.00094719, 0.00108812, 0.00107462, 0.00109863, 0.00115507,
0.00117781]), 'std_fit_time': array([1.09564469e-04, 7.04557722e-05, 4.35584663e-04, 2.08750681e-04,
2.51903306e-04, 1.49746094e-04]), 'mean_score_time': array([0.00189986, 0.00213163, 0.00194747, 0.00228534, 0.00236366,
0.00241489]), 'std_score_time': array([0.00014605, 0.0002255 , 0.00033167, 0.00028329, 0.00035582,
0.00026656]), 'param_n_neighbors': masked_array(data=[1, 3, 5, 7, 9, 11],
mask=[False, False, False, False, False, False],
fill_value='?',
dtype=object), 'params': [{'n_neighbors': 1}, {'n_neighbors': 3}, {'n_neighbors': 5}, {'n_neighbors': 7}, {'n_neighbors': 9}, {'n_neighbors': 11}], 'split0_test_score': array([1., 1., 1., 1., 1., 1.]), 'split1_test_score': array([0.91666667, 0.91666667, 1. , 0.91666667, 0.91666667,
0.91666667]), 'split2_test_score': array([1., 1., 1., 1., 1., 1.]), 'split3_test_score': array([1. , 1. , 1. , 1. , 0.90909091,
1. ]), 'split4_test_score': array([1., 1., 1., 1., 1., 1.]), 'split5_test_score': array([0.90909091, 0.90909091, 1. , 1. , 1. ,
1. ]), 'split6_test_score': array([1., 1., 1., 1., 1., 1.]), 'split7_test_score': array([0.90909091, 0.90909091, 0.90909091, 0.90909091, 1. ,
1. ]), 'split8_test_score': array([1., 1., 1., 1., 1., 1.]), 'split9_test_score': array([0.90909091, 0.81818182, 0.81818182, 0.81818182, 0.81818182,
0.81818182]), 'mean_test_score': array([0.96439394, 0.95530303, 0.97272727, 0.96439394, 0.96439394,
0.97348485]), 'std_test_score': array([0.04365767, 0.0604591 , 0.05821022, 0.05965639, 0.05965639,
0.05742104]), 'rank_test_score': array([5, 6, 2, 3, 3, 1], dtype=int32)}2、准确率和最佳结果
准确率是测试集里的效果
最佳结果是在训练集划分成训练集和验证集,验证集里的结果
文章来源地址https://www.toymoban.com/news/detail-656523.html
到了这里,关于机器学习基础之《分类算法(3)—模型选择与调优》的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!