目录
1.scrapy基本用途:
2.结构:
3.scrapy文件结构(示例:game)
4.scrapy安装
二、 简单实例
1.创建项目(打开命令窗口)
2.打开项目
一、Scrapy框架
1.scrapy基本用途:
Scrapy是一个快速、高效率的网络爬虫框架,用于抓取web站点并从页面中提取结构化的数据。 Scrapy被广泛用于数据挖掘、监测和自动化测试。
2.结构:
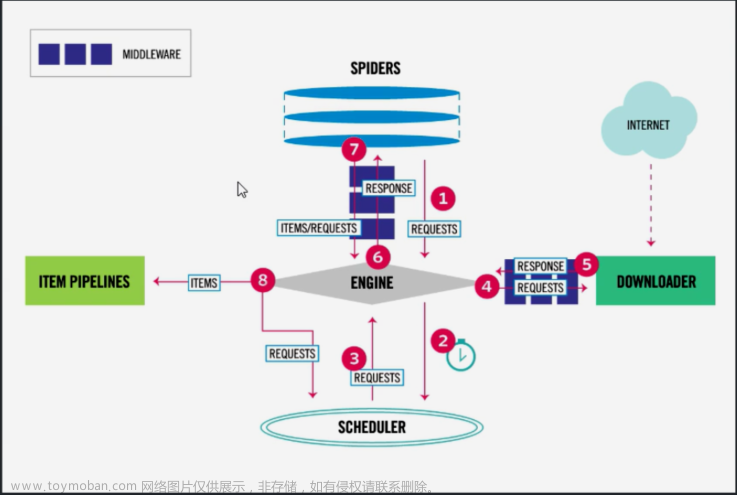
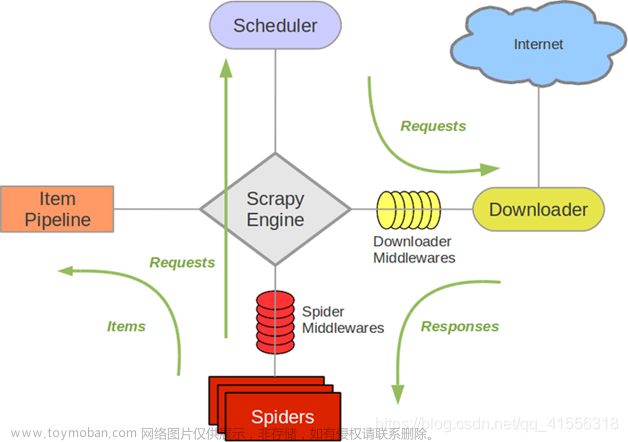
1. Engine(引擎):用来处理整个系统的数据流和时间,是整个框架的核心,可以理解为中央处理器,负责数据的流转和逻辑的处理。
2. Scheduler(调度器):接收Engine发过来的request并将其加入队列中,也可发回Engine,供给Downloader执行,主要维护request的调度逻辑
3. Item:是抽象的数据结构。定义了爬取结果的数据结构,爬取的结果会被赋值成Item对象,每个Item都是一个类,类里面定义了爬取结果的数据字段,可以理解为用来规定数据的存储格式。
4. Spiders(爬虫):负责解析Responses并生成Item和新的请求,然后发给Engine进行处理。
5. Downloader(下载器):负责下载Engine发送的所有请求,将获取的Response返回给Engine,再发给Spiders处理。
6. Item Pipelinses(管道):负责Spiders从页面中抽取的Item,做数据清洗、验证、存储等工作
7. Downloader Middlewares(下载中间件):负责Downloader和Engine之间的请求和响应的处理过程。
8. Spider Middlewares(爬虫中间件):负责实现Spiders和Engine之间的Item、请求和响应的处理过程。
3.scrapy文件结构(示例:game)
game 项目名字
game 项目的名字
spiders 存储用户创建的spider文件
init
steam 用户创建的文件,定义爬取的url以及对数据的处理
init
items 定义爬取的数据结构
middleware 中间件
pipelines 管道 用来处理下载的数据
settings 全局的配置文件
4.scrapy安装
pip install scrapy
# 在命令行或者pycharm的终端中输入都行安装验证:命令窗口输入 scrapy 即可
安装参考:教程
注:如果还是报错,那么可能是缺失 Visual C++ 20xx Redistributable(如何安装,自行百度,版本根据环境需求自行选择);也有可能电脑里安装了一些游戏,顺带安装了这个库,直接一步到位,安装成功了。
二、 简单实例
1.创建项目(打开命令窗口)
scrapy startproject spider# 项目名称,自行命名# 记住系统提示的地址,待会在pycharm中需要到该地址去打开项目
New Scrapy project 'spider', using template directory 'D:\Python3.11.2\Lib\site-packages\scrapy\templates\project', created in:
C:\Users\dell\spider
You can start your first spider with:
cd spider
scrapy genspider example example.com
cd spider
scrapy genspider quotes quotes.toscrape.com
# quotes是spiders文件下spider文件的名称,自行输入
# quotes.toscrape.com 是即将爬取网页的域名C:\Users\dell>cd spider
C:\Users\dell\spider>scrapy genspider quotes quotes.toscrape.com
Created spider 'quotes' using template 'basic' in module:
spider.spiders.quotes创建成功,打开pycharm
2.打开项目
可以将项目中的文件结构对照上面的文件结构。
打开spiders下的quotes.py文章来源:https://www.toymoban.com/news/detail-656533.html
class QuotesSpider(scrapy.Spider):
name = "quotes"
allowed_domains = ["quotes.toscrape.com"]
start_urls = ["https://quotes.toscrape.com"]
def parse(self, response, **kwargs):
quotes = response.xpath('//div[@class="row"]//div[@class="col-md-8"]//div[@class="quote"]')
for quote in quotes:
text = quote.xpath('./span[@class="text"]/text()').extract_first()
author = quote.xpath('./span//small/text()').extract_first()
tags = quote.xpath('./div[@class="tags"]/a/text()').getall()
tag = ','.join(tags) # 将Xpath提取到的列表转换为字符串。
print("Text:", text, "Author:", author, "Tags:", tag)
print() # 作分隔
next = response.xpath('//nav/[@class="next"]//a/@href').extract_first()
# 下一页按钮
url = response.urljoin(next)
yield scrapy.Request(url=url, callback=self.parse)for循环中,xpath需要使用相对地址,否则会出现循环输出某一句内容,或者拿不到数据,显示为None。 文章来源地址https://www.toymoban.com/news/detail-656533.html
到了这里,关于爬虫——Scrapy框架 (初步学习+简单案例)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!




![[爬虫]3.4.1 Scrapy框架的基本使用](https://imgs.yssmx.com/Uploads/2024/02/598070-1.jpg)



