part1 什么是语义分割?
语义分割使图像分类任务的一种,实际上是对图片中每个像素进行分类,将相同类别的像素聚在一起从而呈现出分割的效果。
主要应用于无人驾驶(以像素粒度感知周围环境)与医疗影像领域(以像素粒度定位病灶区域)

当物体存在遮挡时,语义分割会将整体分割,而实例分割则会对相互遮挡的物体进行区分。全景分割一般应用在无人驾驶的图像分割中。
part2 语义分割思路方法
早期思路:基于先验,按照颜色进行分割(先验知识不完全准确)
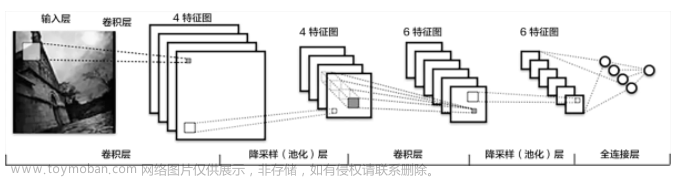
现在思路:基于卷积神经网络

滑动窗口:用不同尺寸大小的滑动窗口在图像上滑动,以某像素为中心的窗口区域看作一张图片,输入卷积神经网络,每一次滑动进行一次分类 (效率太低)
改进方法:与之前一样的卷积,但是直接将整张图片进行卷积,再通过滑动窗输入网络进行分类

新的问题:进行分类的最后一层全连接层,要求有固定的输入大小。
之前是先分割原图,卷积得到尺寸相同的小图像特征图,再输入全连接层得到类别。
现在是先将原图输入卷积层得到特征图,直接输入全连接层得到全图上的类别。而不同的原图对应的卷积后的特征图尺寸是不同的。
解决办法:全连接层的卷积化

举个例子:卷积后的特征图为256*14*14,分类任务有3个类别,全连接层即有3个神经元,每个神经元对特征图256个通道,14*14大小都有固定的权重。那么就可以把全连接层中的每个神经元看作做一个卷积核(图片第二行这里特征图大小与卷积核大小是一致的,最后1*1*3表示这张图在三个类别中的概率)。所以对更大的尺寸不一的原图,输入全连接层就相当于对特征图做了三层卷积。得到F*F*3,就是F*F个位置上的类别,再通过滑动窗分割出F*F个位置的类别
全连接层具体内容参考这篇博主讲的很好:http://t.csdn.cn/V2hMX
这就是下面说的全卷积网络的两大改进之一
part3 经典语义分割模型
(1)全卷积网络(Fully Convolution Network 2015)
改进一:全连接层卷积化
将分类网络转化为语义分割网络,同时兼容任意大小的输入

改进二:预测图的上采样
保证输出预测图大小与原图大小一致

① 双线性插值(无可学习参数,word里面的放大缩小)

② 转置卷积 (有可学习的参数)
双线性插值的卷积核是定义好的,而转置卷积的卷积核是可学习的


全卷积网络的过程:

下采样进行图像分类,再升采样得到与原图大小一致的预测图,与实际的分割图进行逐像素的交叉熵损失函数求损失并求和,作为语义分割的损失,进行反向传播迭代优化网络的可学习参数,如卷积核权重,转置卷积权重,使得损失函数最小化
新的问题:卷积神经网络逐层下采样使得特征图越来越小,使得分割图越来越小。分割精度越来越低,丢失空间信息。(高层特征经过多次采样,细节丢失严重)
解决思路:结合低层次与高层次特征图(低层次的细节与高层次的语义信息)

低层与高层结合经典的网络是UNet

(2)上下文信息与PSPNet(2016)
上下文往往可以帮我们做出更准群的判断,比如床上的枕头,在床上放置能够判断出是枕头。而滑动窗口丢失了上下文信息
存在问题:需要有足够大的感受野帮助我们获取上下文信息,但传统分类网络其感受野受到主干网络的结构限制
解决思路:增加感受野更大的网络分支,将上下文信息导入局部的预测中。

(3)DeepLab

①空洞卷积解决下采样问题
由于下采样会丢失空间信息,希望能够保留特征图的长宽 → 减少下采样的次数 → 于是去掉卷积层和池化层中步长大于1的层 → 于是特征图就会变大,但是为了保证卷积核在原图中的感受野相同 → 于是要增加对应的卷积核,维持相同的感受野 → 增加了大量参数
空洞卷积: 在不增加参数的情况下增大感受野
下采样加标准卷积等价于空洞卷积


只有原图1/4是因为进行了下采样,调整膨胀倍率即可调整感受野大小

②条件随机场 Conditional Random Filed ,CRF
条件随机场是对原始网络的结果进行后处理,得到更加精细化的结果



③空间金字塔池化 Atrous Spatial Pyramid Pooling ,ASPP
PSPNet中使用不同尺度的池化获取不同尺度上的上下文信息
DeepLab v2&v3 使用不同尺度的空洞卷积达到类似的效果
更大的膨胀率的空洞卷积,对应更大的感受野,也就能获取更多的上下文信息

DeepLab v3+
模型方法总结部分:

part4 语义分割模型评估
 文章来源:https://www.toymoban.com/news/detail-656815.html
文章来源:https://www.toymoban.com/news/detail-656815.html
 文章来源地址https://www.toymoban.com/news/detail-656815.html
文章来源地址https://www.toymoban.com/news/detail-656815.html
到了这里,关于语义分割学习篇的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!