索引
什么是索引
索引包含数据表所有记录的引用指针;你可以对某一列或者多列创建索引和指定不同的类型(唯一索引、主键索引、普通索引等不同类型;他们底层实现也是不同的)
作用:表、索引、数据如同书本、目录、内容;能提高数据库性能、快速帮我们定位要看的位置
注意:索引会提高查询效率;但是增删改开销会变大;因为都需要再改变多一个索引;但是增删改通过是频率没那么高的
索引也不一定就能大大提高速度的;如果针对性别这种重复非常多的列加索引;意义就没那么大了
索引怎么用
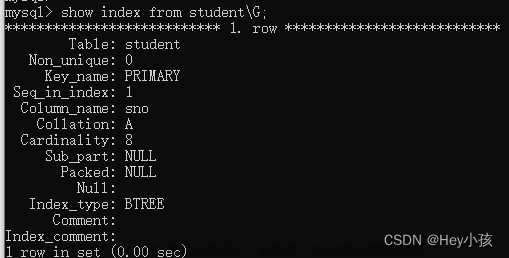
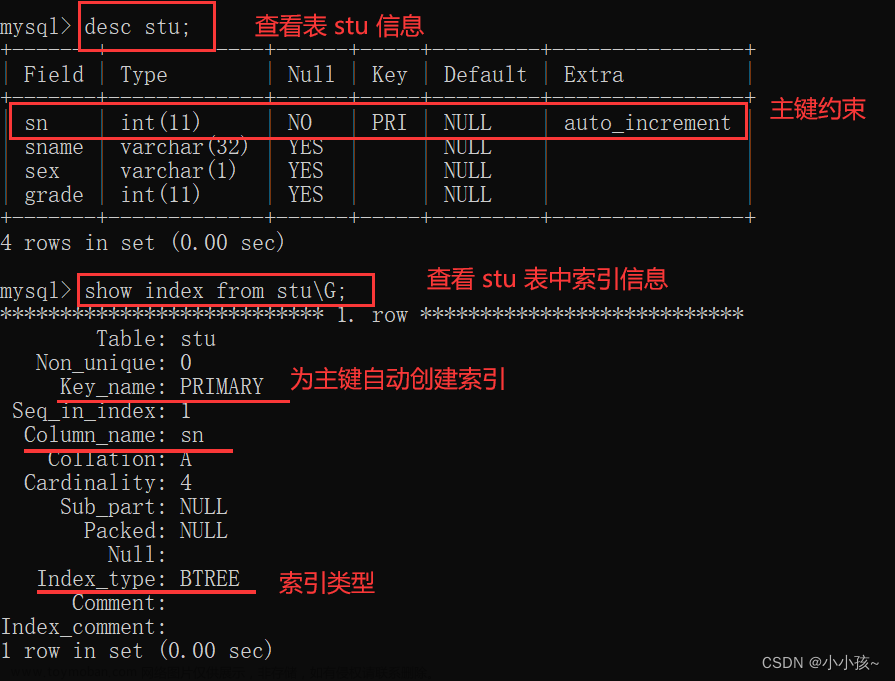
查看索引:show index from 表名;
创建索引:
1:建表时手动创建
CREATE TABLE_name (
column1 datatype,
column2 datatype,
......,
INDEX index_name (column_name1, column_name2, ...)
);
2:建表后自动创建
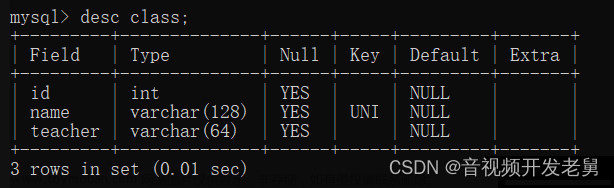
创建主键约束(PRIMARY KEY)、唯一约束(UNIQUE)、外键约束(FOREIGN KEY)时,会自动创建对应列的索引。
3:建表后怎手动创建
create index 索引名 on 表名(字段名);
ALTER TABLE table_name ADD INDEX index_name (column1 [ASC|DESC], column2 [ASC|DESC], ...);
//INDEX是创建普通索引;主键索引:PRIMARY;唯一:UNIQUE、全文:FULLTEXT
注意:创建和删除这两个操作最好是在建表的约定清楚;因为后面再来创建和删除这估计很危险;要吃很多资源
使用索引:我们只需要创建完了进行;数据库会自动通过搜索引擎评估哪种方案性价比最好;评估是否走索引;如果要走的话怎么走
删除索引:drop index 索引名 on 表名;
索引的原理
1:哈希表?只能比较相等;没法范围查询;不行
2:二叉搜索树?查询元素时间复杂度;单边树跟链表一样O(n);能范围查询;但是元素多;树的高度就会比较高;比较的次数就会比较多。
3:N叉搜索树;分叉多;树的高度就降低了。每个节点有多个值,同时有多个分叉,树的高度降低了,比较次数虽然没有减少,但是在硬盘上读的次数减少了。因为每一个节点都是在硬盘上的(就好比你一次丢5袋垃圾肯定比丢5次一袋垃圾快);可能会出现在根节点、不深的位置查的比较快;查询速度不均衡。
4:B+树;N叉搜索树已经很合适但是还不够;需要进一步补充。量身定做;最大值要重复出现
这也是N插搜索树;每个节点包含N个key,N个key划分N个区间;最后一个Key是最大值;例如上面:11比8大就放15的左边;最右边永远最大。
父元素的Key会反复在子元素以最大值出现;最终在叶子节点包含所有数据全集;最后用类似链表方式连接
1:高度下降IO操作就少了、
2:范围查询更香;
3:所有的查询都落在叶子节点上;无论查哪个元素中间;中间的比较次数都不多
4:所有的Key都在叶子节点上体现;使用非叶子节点不必存表的数据行;把所有的数据行放到叶子节点上即可;非叶子节点只需要存索引列的值
如果多索引:
比如主键索引是id,非主键索引的姓名。
那么姓名索引的B+树的叶子节点存储的都是主键id,找到id后,再去主键索引idB+树去遍历,主键idB+树的叶子节点存储的是完整数据行
它的实现会帮我们构建好这颗树;然后我们要输入的数据就会走这颗树去查询
B+树只是在MySQL的InnDB这个数据库储存引擎所使用的典型数据结构。不同的数据库有不同的储存引擎,索引的数据结构也会有所差异。(储存引擎;实现数据库具体如何在硬盘上组织数据)
事务
事务初衷:把有些操作不能分割的打包成一个整体(原子性)。比如:转账分两部分;用户A钱 - -;用户B钱++。如果中间出现问题;导致的结果但是致命的;可能没转成功就扣钱了。
回滚事务:上述如果中间出现问题;就自动恢复执行之前的样子;让你看起来没执行的样子(就像你走5步回到原点;和你在原点一直没有动的区别)
使用事务
Start transaction;//开启事务;开启后这些sql代码先攒着;等commit再一起执行;保证原子性
sql;
sql
sql;
commit;//提交事务
//出现问题就rollback;回滚事务
事务特性
什么是事务?
事务(Transaction)是一组一起执行的操作,通常用来执行一些相关的任务,而且必须被视为一个不可分割的单元。
1:原子性; 事务是一个原子操作,要么全部成功,要么全部失败。如果事务的任何部分失败,系统必须将其恢复到原始状态,即回滚
2:原子性:事务在执行前后,数据库必须保持一致性状态。这意味着事务的执行不会破坏数据库的完整性约束,如唯一性约束、外键约束等。
3:持久性;事务产生的修改会写入硬盘。(先把要执行的过程记录到硬盘;然后再真正的去执行;根据这个如果断电下次重连就知道上次执行到哪;然后进行回滚)
4:隔离性;并发执行事务之间的相互隔离;让每个事务在执行的过程中感知不到别的事务对数据库的修改和存在
一个数据库服务器;同时执行多个事务的时候;事务之间相互影响程度(一个服务器有多个客户端;可能并发出现线程安全问题;尤其是操作同一个表的时候)
MySQL隔离级别
隔离性越高;并发程度越低;效率是慢了点;但是准确度高。(反之则反之)
MySQL隔离级别就为我们提供不同档位的并发程度;有些场景我们可能需要准(算钱);有些场景我们可能需要快
脏读:我在进行修改博客的时候;然后另一个人在读;但是我改到一半发现我写错了;不行我得擦掉重写。而恰好我写错的部分就被那个人读走了(加锁:我在写的时候不给你读)
解决:降低并发性;提高隔离性(给写操作加锁)
不可重复读:根据脏读的要求;我写的时候不给另一个人看。ok;我写完了;另一个人现在开始读了一半;然后我发现有问题这个例子举的不好;我得重新修改一下;我把我博客改了重新发布。这就导致另一个人刚刚读到牛一天吃100斤草;再往下读;怎么变成马这样吃能一天跑千里呢?
解决:给读操作也加锁;读的时候;我不能改
幻读:根据上述两个要求;我又整活了。你读你的;不给我改是吧;我就是闲不下来;我要学习;我又写一篇新文章;或者觉得有篇不好我删掉重写;结果是他读当前的文件内容没问题;但是他看到的文件个数改变了。同一个事务;两次读到的结果集不同。
解决:舍弃并发;别卷了;他在读的时候你就休息一下;该休息就得好好休息;才能更好的学习文章来源:https://www.toymoban.com/news/detail-657477.html
四个隔离级别:
默认挡位是第三个;我们可以根据具体要解决需求场景;在MySQL配置文件决定使用哪个隔离级别文章来源地址https://www.toymoban.com/news/detail-657477.html
到了这里,关于MySQL之索引和事务的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!