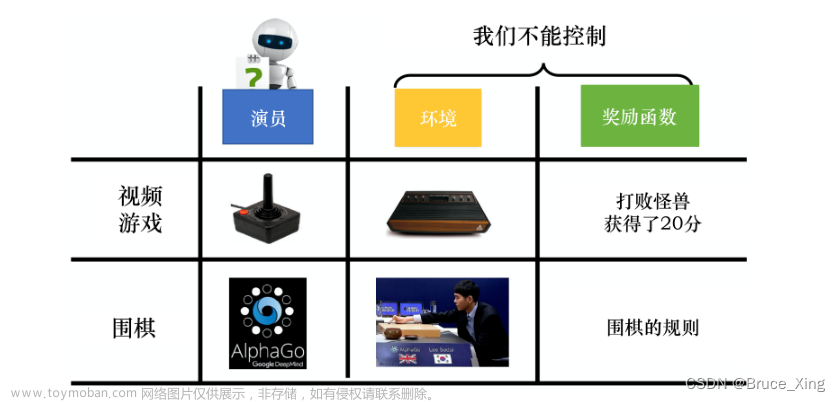
从open AI 的论文可以看到,大语言模型的优化,分下面三个步骤,SFT,RM,PPO,我们跟随大神的步伐,来学习一下这三个步骤和代码实现,本章介绍PPO实践。
生活中,我们经常会遇到,希望chatgpt在指定内容范围内回答问题。目前的解决方案大致可以分为两大类,一类是知识库外挂,代表作如langchain。把chatgpt的结果转换为向量在知识库里检索。如下图,本质上最终还是一种向量检索,chatgpt的能力其实是打了一个大的折扣。
另外一类是扩展现有LLM模型的Context处理长度,把候选直接作为llm模型的Context。这里涉及到两个问题,一个是如何扩展Context长度,一个是如何让llm模型只在指定Context内回答问题。今天我们ppo优化主要解决llm模型只在指定Context内回答问题。

样本
我们在1000篇文章中随机选择30篇作为prompt,让模型从这30篇文章中选择出我们想要的文章。
#随机选择30篇作为prompt
random_articles = df.sample(n=31)
random_article = random_articles.iloc[0]
cat = random_article['category']
article_list = [title + ' (' + cat + ')' for title, cat in zip(random_articles['title'], random_articles['category'])]
input_str = construct_input(article_list, cat)
input_ids = tokenizer.encode(input_str, return_tensors='pt').to('cuda')模型准确率判定
可以回答多篇结果,如果模型有我们希望的回答的结果,加1分,不符合减1分。
#判断命中条数
for ans in answer.split('\n'):
similarity_threshold = 0.9 # 相似度阈值
# 判断是否在input中且分类是否一致
if is_similar(ans, article_list, similarity_threshold):
positive_num = positive_num +1
break
print(i, 'accuracy:', positive_num / (i+1))rm样本制作
第一种
正例:选择一条在prompt中符合条件的新闻为正例
负例:随机选择一条不在prompt中的新闻作为负例,
第二种,
正例:sft一次预测多条,从预测的结果中,挑选出符合条件的为正
负例:sft一次预测多条,从预测的结果中,挑选出不符合条件的为负
比较的结果是第二种方案会好一些。
也可以参考这篇博文ChatGLM-RLHF(三)-RM(Reward Model)实现&代码逐行注释_Pillars-Creation的博客-CSDN博客
ppo训练预测
ppo原理前一章节已经讲了,传送门ChatGLM-RLHF(六)-PPO(Proximal Policy Optimization)原理&实现&代码逐行注释_Pillars-Creation的博客-CSDN博客
需要注意的就是,因为训练时候需要加载sft和rm两个模型, 你需要一个大一点显存的gpu,本例在A100,40G显存上跑通。如果显存小了容易报显存不足的错误。
训练结果
原始预测结果

sft预测结果

ppo预测结果

几点体会,
1,好的sft可以解决大部分的问题,从上面实验看简单sft训练后准确率就可以得到明显提升
2,要根据自身需要定制好的rm样本和loss。有时候单纯根据sft样本,模型可能很难总结出你真正的目的,rm可以帮助模型更好的理解人的期望。
3,rm单独使用效果不一定比sft效果更好,这也比较好理解,rm需要人工标注pair对,数量总是有限的,并且这个pair对,是否清晰表达给了模型用户的全部意图,容易顾此失彼。所以rm我们更多用在最后,结合ppo纠正模型。
4,rm过程可以进行多次,把自己的目标拆解成几个rm过程,更容易达到我们的目标
5,PPO过程确实帮助模型效果得到了提升,并且可以从比较粗劣的rm结果和sft模型对比中学到知识。文章来源:https://www.toymoban.com/news/detail-657743.html
完整代码可以参考:
GitHub - Pillars-Creation/ChatGLM-RLHF-LoRA-RM-PPO: ChatGLM-6B添加了RLHF的实现,以及部分核心代码的逐行讲解 ,实例部分是做了个新闻短标题的生成文章来源地址https://www.toymoban.com/news/detail-657743.html
到了这里,关于大语言模型-RLHF(七)-PPO实践(Proximal Policy Optimization)原理&实现&代码逐行注释的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![[论文笔记] chatgpt——PPO算法(Proximal Policy Optimization)](https://imgs.yssmx.com/Uploads/2024/02/428566-1.png)

![[论文笔记] chatgpt系列 1.1 PPO算法(Proximal Policy Optimization)](https://imgs.yssmx.com/Uploads/2024/02/438457-1.png)