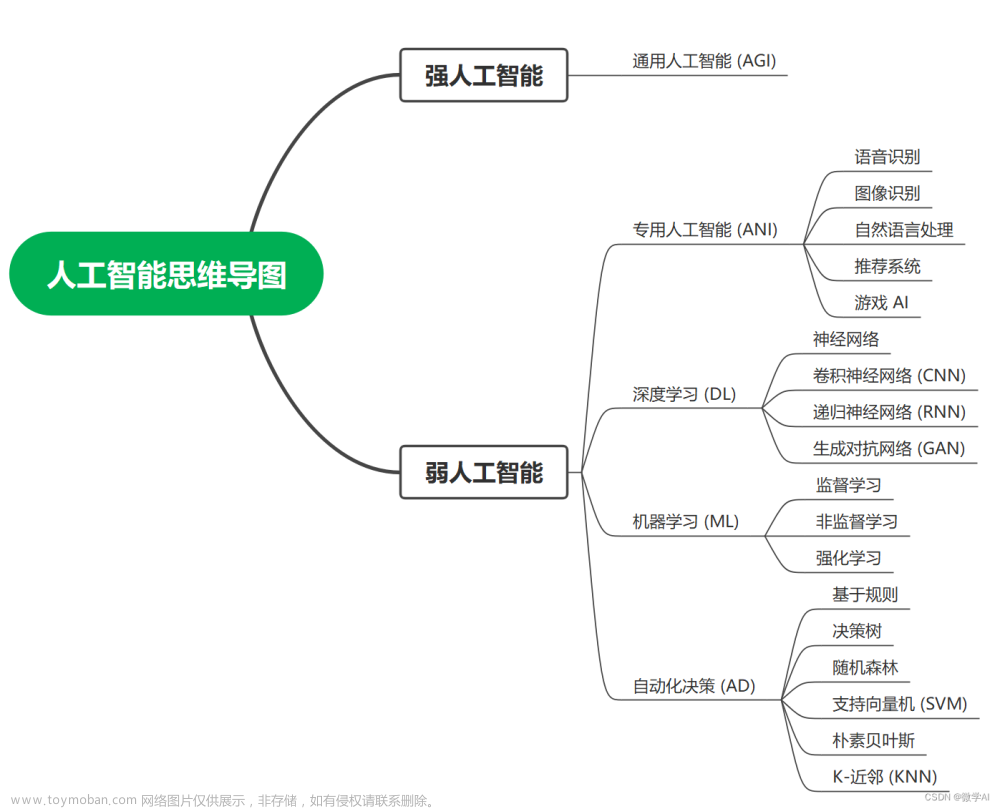
最近几天学习了机器学习经典算法,通过此次学习入门了机器学习,并将经典算法的代码实现并记录下来,方便后续查找与使用。
这次记录主要分为两部分:第一部分是机器学习思维导图,以框架的形式描述机器学习开发流程,并附有相关的具体python库,做索引使用;第二部分是相关算法的代码实现(其实就是调包),方便后面使用时直接复制粘贴,改改就可以用,尤其是在数学建模中很实用。
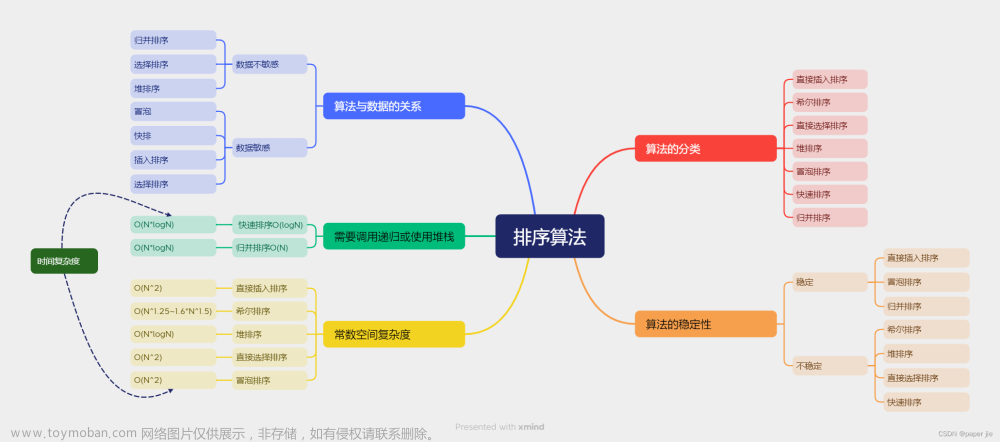
第一部分,思维导图:
第二部分,代码示例:文章来源:https://www.toymoban.com/news/detail-657847.html
机器学习代码示例
导包
import numpy as np
import pandas as pd
from matplotlib.pyplot import plot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import StandardScaler
from sklearn.feature_selection import VarianceThreshold
from scipy.stats import pearsonr
from sklearn.model_selection import GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import MultinomialNB
from sklearn.tree import DecisionTreeClassifier, export_graphviz
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LinearRegression, SGDRegressor, Ridge, LogisticRegression
from sklearn.metrics import mean_squared_error
from sklearn.metrics import classification_report
from sklearn.metrics import roc_auc_score
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
import joblib
特征工程
特征抽取
def dict_demo():
data = [{'city': '北京', 'temperature': 100}, {'city': '上海', 'temperature': 200},
{'city': '广州', 'temperature': 300}]
transfer = DictVectorizer()
data_new = transfer.fit_transform(data)
data_new = data_new.toarray()
print(data_new)
print(transfer.get_feature_names_out())
# dict_demo()
def count_demo():
data = ["I love love China", "I don't love China"]
transfer = CountVectorizer()
data_new = transfer.fit_transform(data)
data_new = data_new.toarray()
print(data_new)
print(transfer.get_feature_names_out())
# count_demo()
def chinese_demo(d):
tt = " ".join(list(jieba.cut(d)))
return tt
# data = [
# "晚风轻轻飘荡,心事都不去想,那失望也不失望,惆怅也不惆怅,都在风中飞扬",
# "晚风轻轻飘荡,随我迎波逐浪,那欢畅都更欢畅,幻想更幻想,就像 你还在身旁"]
# res = []
# for t in data:
# res.append(chinese_demo(t))
#
# transfer = TfidfVectorizer()
# new_data = transfer.fit_transform(res)
# new_data = new_data.toarray()
# print(new_data)
# print(transfer.get_feature_names_out())
数据预处理
def minmax_demo():
data = pd.read_csv("datasets/dating.txt")
data = data.iloc[:, 0:3]
print(data)
transfer = MinMaxScaler()
data_new = transfer.fit_transform(data)
print(data_new)
return None
# minmax_demo()
def standard_demo():
data = pd.read_csv("datasets/dating.txt")
data = data.iloc[:, 0:3]
print(data)
transfer = StandardScaler()
data_new = transfer.fit_transform(data)
print(data_new)
return None
# standard_demo()
def stats_demo():
data = pd.read_csv("./datasets/factor_returns.csv")
data = data.iloc[:, 1:10]
transfer = VarianceThreshold(threshold=10)
data_new = transfer.fit_transform(data)
print(data_new)
print(data_new.shape)
df = pd.DataFrame(data_new, columns=transfer.get_feature_names_out())
print(df)
# stats_demo()
def pear_demo():
data = pd.read_csv("./datasets/factor_returns.csv")
data = data.iloc[:, 1:10]
print(data.corr(method="pearson"))
# pear_demo()
模型训练
分类算法
KNN
# 读取数据
iris = load_iris()
# 数据集划分
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.3, random_state=42)
# 数据标准化
transfer = StandardScaler()
transfer.fit(x_train)
x_train = transfer.transform(x_train)
x_test = transfer.transform(x_test)
# 模型训练
estimator = KNeighborsClassifier(n_neighbors=i)
estimator.fit(x_train, y_train)
# 模型预测
y_predict = estimator.predict(x_test)
score = estimator.score(x_test, y_test)
print("score:", score)
朴素贝叶斯
new = fetch_20newsgroups(subset="all")
x_train, x_test, y_train, y_test = train_test_split(new.data, new.target, random_state=42)
# 文本特征提取
transfer = TfidfVectorizer()
transfer.fit(x_train)
x_train = transfer.transform(x_train)
x_test = transfer.transform(x_test)
estimator = MultinomialNB()
estimator.fit(x_train, y_train)
score = estimator.score(x_test, y_test)
print(score)
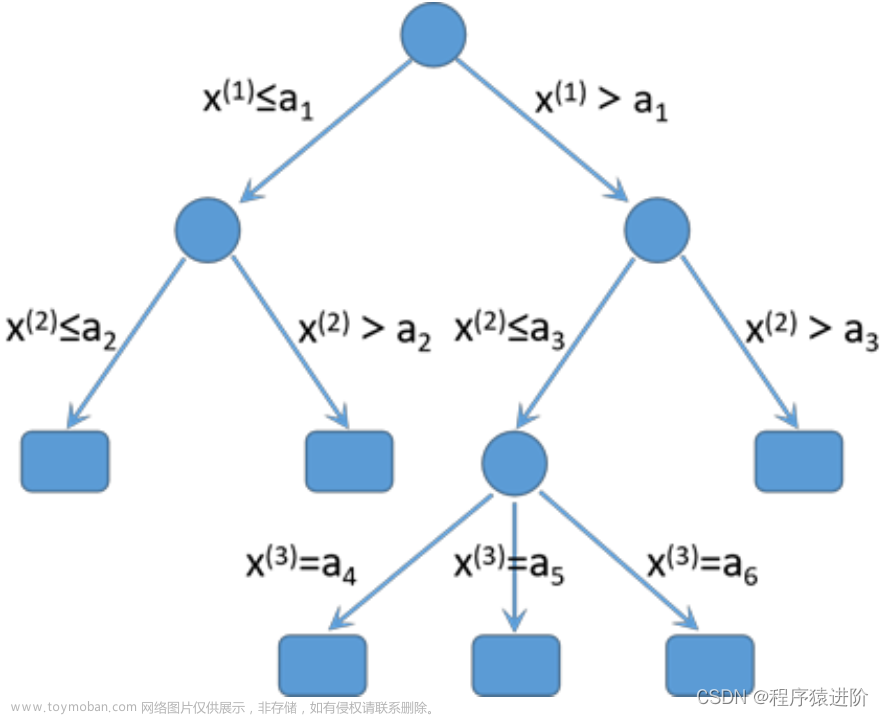
决策树
iris = load_iris()
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.3, random_state=42)
estimator = DecisionTreeClassifier(criterion='gini')
estimator.fit(x_train, y_train)
score = estimator.score(x_test, y_test)
print(score)
# 决策树可视化
export_graphviz(estimator, out_file='tree.dot', feature_names=iris.feature_names)
随机森林
x_train, x_test, y_train, y_test = train_test_split(x, y, train_size=0.7)
estimator = RandomForestClassifier(random_state=42, max_features='sqrt')
param_dict = {'n_estimators': range(10, 50), 'max_depth': range(5, 10)}
estimator = GridSearchCV(estimator=estimator, param_grid=param_dict, cv=3)
estimator.fit(x_train, y_train)
print(estimator.best_score_)
print(estimator.best_estimator_)
print(estimator.best_params_)
回归算法
线性回归
def demo1():
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
x_train, x_test, y_train, y_test = train_test_split(data, target, train_size=0.7, random_state=42)
transfer = StandardScaler()
transfer.fit(x_train)
x_train = transfer.transform(x_train)
x_test = transfer.transform(x_test)
estimator = LinearRegression()
estimator.fit(x_train, y_train)
y_predict = estimator.predict(x_test)
mse = mean_squared_error(y_test, y_predict)
print("正规方程-", estimator.coef_)
print("正规方程-", estimator.intercept_)
print(mse)
def demo2():
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
x_train, x_test, y_train, y_test = train_test_split(data, target, train_size=0.7, random_state=42)
transfer = StandardScaler()
transfer.fit(x_train)
x_train = transfer.transform(x_train)
x_test = transfer.transform(x_test)
estimator = SGDRegressor()
estimator.fit(x_train, y_train)
y_predict = estimator.predict(x_test)
mse = mean_squared_error(y_test, y_predict)
print("梯度下降", estimator.coef_)
print("梯度下降", estimator.intercept_)
print(mse)
岭回归
def demo3():
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
x_train, x_test, y_train, y_test = train_test_split(data, target, train_size=0.7, random_state=42)
transfer = StandardScaler()
transfer.fit(x_train)
x_train = transfer.transform(x_train)
x_test = transfer.transform(x_test)
estimator = Ridge()
estimator.fit(x_train, y_train)
y_predict = estimator.predict(x_test)
mse = mean_squared_error(y_test, y_predict)
print("梯度下降", estimator.coef_)
print("梯度下降", estimator.intercept_)
print(mse)
逻辑回归
def demo4():
data = pd.read_csv("./datasets/breast-cancer-wisconsin.data",
names=['Sample code number', 'Clump Thickness', 'Uniformity of Cell Size',
'Uniformity of Cell Shape',
'Marginal Adhesion', 'Single Epithelial Cell Size', 'Bare Nuclei', 'Bland Chromatin',
' Normal Nucleoli', 'Mitoses', 'Class'])
data.replace(to_replace="?", value=np.nan, inplace=True)
data.dropna(inplace=True)
x = data.iloc[:, 1:-1]
y = data['Class']
x_train, x_test, y_train, y_test = train_test_split(x, y, train_size=0.7, random_state=42)
transfer = StandardScaler()
transfer.fit(x_train)
x_train = transfer.transform(x_train)
x_test = transfer.transform(x_test)
estimator = LogisticRegression()
estimator.fit(x_train, y_train)
# joblib.dump(estimator, 'estimator.pkl')
# estimator = joblib.load('estimator.pkl')
y_predict = estimator.predict(x_test)
print(estimator.coef_)
print(estimator.intercept_)
score = estimator.score(x_test, y_test)
print(score)
report = classification_report(y_test, y_predict, labels=[2, 4], target_names=["良性", "恶性"])
print(report)
auc = roc_auc_score(y_test, y_predict)
print(auc)
聚类算法
KMeans
data = pd.read_csv("./datasets/factor_returns.csv")
data = data.iloc[:, 1:10]
transfer = VarianceThreshold(threshold=10)
data_new = transfer.fit_transform(data)
# df = pd.DataFrame(data_new, columns=transfer.get_feature_names_out())
estimator = KMeans()
estimator.fit(data_new)
y_predict = estimator.predict(data_new)
print(y_predict)
s = silhouette_score(data_new, y_predict)
print(s)
模型调优
# 网格搜索与交叉验证:以KNN为例
iris = load_iris()
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.3, random_state=42)
transfer = StandardScaler()
transfer.fit(x_train)
x_train = transfer.transform(x_train)
x_test = transfer.transform(x_test)
estimator = KNeighborsClassifier()
# 网格搜素设置
para_dict = {"n_neighbors": range(1, 10)}
estimator = GridSearchCV(estimator, para_dict, cv=10)
estimator.fit(x_train, y_train)
# 最佳参数
print("best_score_:", estimator.best_score_)
print("best_estimator_:", estimator.best_estimator_)
print("best_params_:", estimator.best_params_)
本文作者:CodingOrange
本文链接:https://www.cnblogs.com/CodingOrange/p/17642747.html
转载请注明出处!文章来源地址https://www.toymoban.com/news/detail-657847.html
到了这里,关于python机器学习经典算法代码示例及思维导图(数学建模必备)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!