一、UUID
UUID的标准形式包含32个16进制数字,以 “ - ” 进行分割,形式为 8-4-4-4-12的32个字符,实例
550e8400-e29b-41d4-a716-446655440000。
优点:
- 性能高,本地生成,没有网络消耗
缺点:
- 不易存储,长度太长,32个16进制数字,128位
- 不安全,会暴露MAC地址
- UUID作为MySQL主键,会导致索引页分页,插入慢;长度太长,导致每个索引页存放的索引变少,索引效率降低
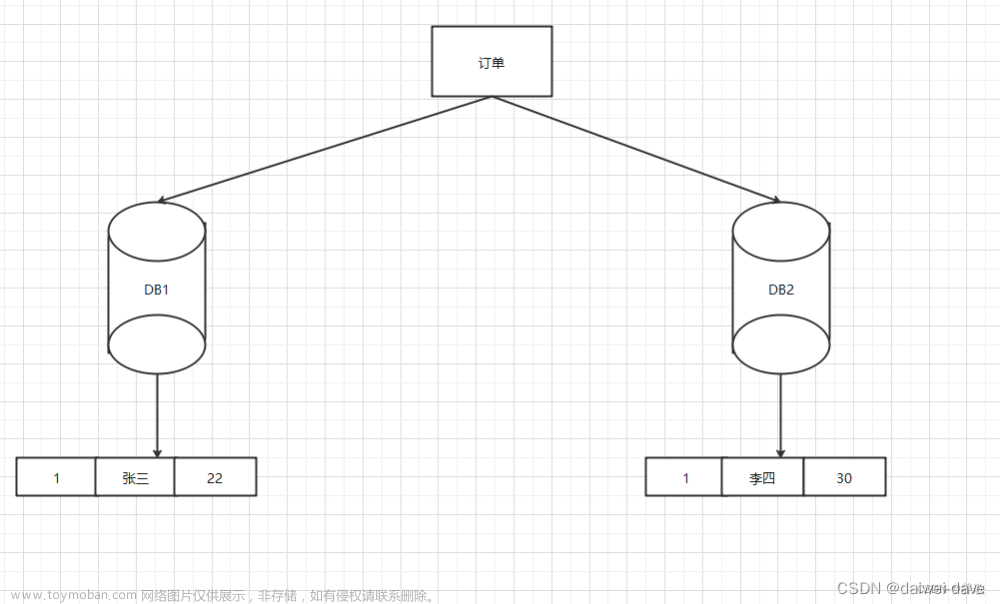
二、数据库方式
1、数据库生成之简单方式
利用给字段设置auto_increment_increment和auto_increment_offset来保证ID自增,每次业务使用下列SQL读写MySQL得到ID号作为业务的唯一ID
begin;
// 如果表中存在相同的数据,则将表中的数据删除,然后重新插入一条数据
2 REPLACE INTO Tickets64 (stub) VALUES ('a');
3 SELECT LAST_INSERT_ID();
4 commit;

优点:
- 非常简单,利用现有数据库系统的功能实现,成本小
- ID单调递增,可以实现一些对ID有特殊要求的业务
缺点
- 强依赖DB,当DB异常时,整个系统不可使用,属于致命问题。应该配置主从复制以尽可能增加可用性(但是主从切换时可能会导致重复发号)
- ID发号,性能瓶颈限制在单台MySQL的读写性能
2、数据库生成 - 多台机器和设置步长,解决性能问题
在分布式系统中我们可以多部署几台机器,每台机器设置不同的初始值,且步长和机器数相等
比如有两台机器。设置步长step为2,TicketServer1的初始值为1(1,3,5,7,9,11…)、TicketServer2的初始值为2(2,4,6,8,10…)
假设我们要部署N台机器,步长需设置为N,每台的初始值依次为0,1,2…N-1那么整个架构就变成了如下图所示:
这种架构貌似能够满足性能的需求,但有以下几个缺点:
-
系统水平扩展比较困难,比如定义好了步长和机器台数之后,如果要添加机器该怎么
做?假设现在只有一台机器发号是1,2,3,4,5(步长是1),这个时候需要扩容机器一台。可
以这样做:把第二台机器的初始值设置得比第一台超过很多,比如14(假设在扩容时间之
内第一台不可能发到14),同时设置步长为2,那么这台机器下发的号码都是14以后的偶
数。然后摘掉第一台,把ID值保留为奇数,比如7,然后修改第一台的步长为2。让它符合
我们定义的号段标准,对于这个例子来说就是让第一台以后只能产生奇数。扩容方案看起来
复杂吗?貌似还好,现在想象一下如果我们线上有100台机器,这个时候要扩容该怎么做?
简直是噩梦。所以系统水平扩展方案复杂难以实现。 -
ID没有了单调递增的特性,只能趋势递增,这个缺点对于一般业务需求不是很重要,可以容忍
-
数据库压力还是很大,每次获取ID都得读写一次数据库,只能靠堆机器来提高性能
3、Leaf-segment 方案实现
Leaf-segment方案,在使用数据库的方案上,做了如下改变:
- 原方案每次获取ID都得读写一次数据库,造成数据库压力大
- 改为利用批量获取,每次获取一个segment(step决定大小)号段的值。用完之后再去数据库获取新的号段,可以大大的减轻数据库的压力
- 各个业务不同的发号需求用biz_tag字段来区分,每个biz-tag的ID获取相互隔离,互不影响。
如果以后有性能需求需要对数据库扩容,不需要上述描述的复杂的扩容操作,只需要对biz_tag分库分表就行。
数据库表设计如下:
重要字段说明:
- biz_tag用来区分业务
- max_id表示该biz_tag目前所被分配的ID号段的最大值
- step表示每次分配的号段长度。原来获取ID每次都需要写数据库,现在只需要把step设置得足够大,比如1000。那么只有当1000个号被消耗完了之后才会去重新读写一次数据库。读写数据库的频率从1减小到了1/step
系统架构
优缺点:
优点:
- 将分配ID的压力由数据库转移到web服务(Leaf), Leaf服务可以很方便的进行线程扩展,性能完全能够支撑大多数业务场景
- 容灾性高:Leaf服务内部有号段缓存,即使DB宕机,短时间内Leaf仍能正常对外提供服务
- 可以自定义max_id的大小,非常方便业务从原有的ID方式上迁移过来
缺点:
- ID号码不够随机,能够泄露发号数量的信息,不太安全
- TP999数据波动大(当一个号段的ID使用完全后,leaf服务去mysql取号段,在此过程中应用服务如果有很大的并发过来,就会导致没有ID进行分配,从而导致响应时间变长,出现尖刺)
- DB宕机的话,整个系统不可使用
4、双 buffer 优化
对于第二个缺点(响应存在峰值),Leaf-segment做了一些优化,简单的说就是:
Leaf 取号段的时机是在号段消耗完的时候进行的,也就意味着号段临界点的ID下发时间取决于下一次从DB取回号段的时间,并且在这期间进来的请求也会因为DB号段没有取回来,导致线程阻塞。如果请求DB的网络和DB的性能稳定,这种情况对系统的影响是不大的,但是假如取DB的时候网络发生抖动,或者DB发生慢查询就会导致整个系统的响应时间变慢。
为此,我们希望DB取号段的过程能够做到无阻塞,不需要在DB取号段的时候阻塞请求线程,即当号段消费到某个点时就异步的把下一个号段加载到内存中。而不需要等到号段用尽的时候才去更新号段。这样做就可以很大程度上的降低系统的TP999指标。

采用双buffer的方式,Leaf服务内部有两个号段缓存区segment。当前号段已下发10%时,如果下一个号段未更新,则另启一个更新线程去更新下一个号段。当前号段全部下发完后,如果下个号段准备好了则切换到下个号段为当前segment接着下发,循环往复
每个biz-tag都有消费速度监控,通常推荐segment长度设置为服务高峰期发号QPS的600倍(10分钟),这样即使DB宕机,Leaf仍能持续发号10-20分钟不受影响
5、Leaf高可用容灾
对于第三点“DB可用性”问题,我们目前采用一主两从的方式,同时分机房部署,Master和Slave之间采用半同步方式同步数据
这里,我其实是没怎么听懂的 !即使使用了主从,在数据同步过程不是还会有ID重复吗

三、基于Redis实现分布式ID
四、雪花算法
1、雪花算法介绍
Snowflake,雪花算法是由Twitter开源的分布式ID生成算法,以划分命名空间的方式将64-bit位分割成多个部分,每个部分代表不同的含义。而 Java中64bit的整数是Long类型,所以在 Java 中 SnowFlake 算法生成的 ID 就是 long 来存储的。
- 第1位:占用1bit,第一位为符号位,不使用。
- 第1部分:41位的时间戳,41-bit位可表示2^41个数,每个数代表毫秒,那么雪花算法可
用的时间年限是(2^41)/(1000606024365)=69 年的时间 - 第2部分:10-bit位可表示机器数,即2^10 = 1024台机器,通常不会部署这么多台机器。也可以划分为多个(比如前5位可以作为机房ID 0-31个机房,后5位作为每个机房的机器ID)
- 第3部分:12-bit位是自增序列,可表示2^12 = 4096个数。
41位时间戳是固定的,时间戳转二进制的长度是41位,后面两个部分都可以灵活调正,只要注意后面位运算的位数就行
2、 雪花算法生产环境架构:

3、雪花算法的时钟回拨问题
回拨时间很短( <= 100ms)
让当前循环一段时间进行等待
回拨时间适中 (100ms < < 1s)
在内存中维护最近 每个 1ms 内的最大值
回拨时间较长 (1s < <= 5s)
结合雪花算法生产环境架构,当客户端段捕获到时钟回拨异常后,由客户端进行重试
时钟回拨时间很长 (> 5s)
直接将出问题的机器下线,然后发送短信告诉运维人员,这台机器出现问题
4、美团 Leaf-snowflake 方案
Leaf-snowflake方案完全沿用snowflake方案的bit位设计,即“1+41+10+12”的方式组装ID号。对于workerID的分配,当服务集群数量较小的情况下,完全可以手动配置。Leaf服务规模较大,动手配置成本太高。所以使用Zookeeper持久顺序节点的特性自动对snowflake节点配置wokerID。
Leafsnowflake是按照下面几个步骤启动的:
- 启动Leaf-snowflake服务,连接Zookeeper,在leaf_forever父节点下检查自己是否已经注册过(是否有该顺序子节点)。
- 如果有注册过直接取回自己的workerID(zk顺序节点生成的int类型ID号),启动服务。
- 如果没有注册过,就在该父节点下面创建一个持久顺序节点,创建成功后取回顺序号当做自己的workerID号,启动服务

解决时钟问题
因为这种方案依赖时间,如果机器的时钟发生了回拨,那么就会有可能生成重复的ID号,需要解决时钟回退的问题。文章来源:https://www.toymoban.com/news/detail-657953.html
这一部分暂时没看懂,等会回来补充下!!!文章来源地址https://www.toymoban.com/news/detail-657953.html
到了这里,关于分布式唯一ID实战的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!