前言
OpenAI API 几乎可以应用于任何涉及理解或生成自然语言或实现代码等场景。提供一系列具有不同学习训练的模型,适用于处理不同的任务,并且自己能够自定义学习模型,通过大样本数据去喂养该模型,使其能实现自己的应用场景。这些模型可用于从内容生成到语义搜索和分类的所有领域。
一、账号注册申请密钥
openai获取密钥
二、参数详情
- models:模型,其包含Davinci, Curie, Babbage 和 Ada等子模型,每个子模型的功能不尽相同
- prompt:生成完成的提示,编码为字符串、字符串数组、标记数组或标记数组数组。
- tokens:文本长度限制,要求输入和输出的文本总长度不能超过各模型限定的Tokens长度
- temperature:温度,使用什么采样温度,介于 0 和 2 之间。较高的值(如 0.8)将使输出更加随机,而较低的值(如 0.2)将使输出更加集中和确定。控制结果随机性,0.0表示结果固定,随机性大可以设置为0.9
- topP:一种替代温度采样的方法,称为核采样,其中模型考虑具有 top_p 概率质量的标记的结果。所以 0.1 意味着只考虑构成前 10% 概率质量的标记。
- frequencyPenalty:-2.0 和 2.0 之间的数字。正值会根据新标记在文本中的现有频率对其进行惩罚,从而降低模型逐字重复同一行的可能性。
- presencePenalty:-2.0 和 2.0 之间的数字。正值会根据到目前为止是否出现在文本中来惩罚新标记,从而增加模型谈论新主题的可能性。
- stop:API 将停止生成更多令牌的最多 4 个序列。返回的文本将不包含停止序列。
- n:为每个提示生成多少完成。
- stream:是否以流方式返回输出
三、Java集成
1.调用接口
这边就以流的方式接收结果
// 调用接口 https://api.openai.com/v1/completions
// 请求头:
Authorization: Bearer + KEY
// 参数:
Map<String, Object> param = new HashMap<>();
param.put("model", "text-davinci-003");
param.put("prompt", text);
param.put("max_tokens", 2048);
param.put("temperature", 0);
param.put("frequency_penalty", 0);
param.put("presence_penalty", 0);
param.put("stream", true);
param.put("stop", CollectionUtil.newArrayList("\n"));
2.响应数据
// text/event-stream
//设置推送内容类型为事件流
response.setContentType("text/event-stream");
//消息流编码格式
response.setCharacterEncoding("utf-8");
// 将收到的流数据返回给前端显示
四、效果
问答示例效果:

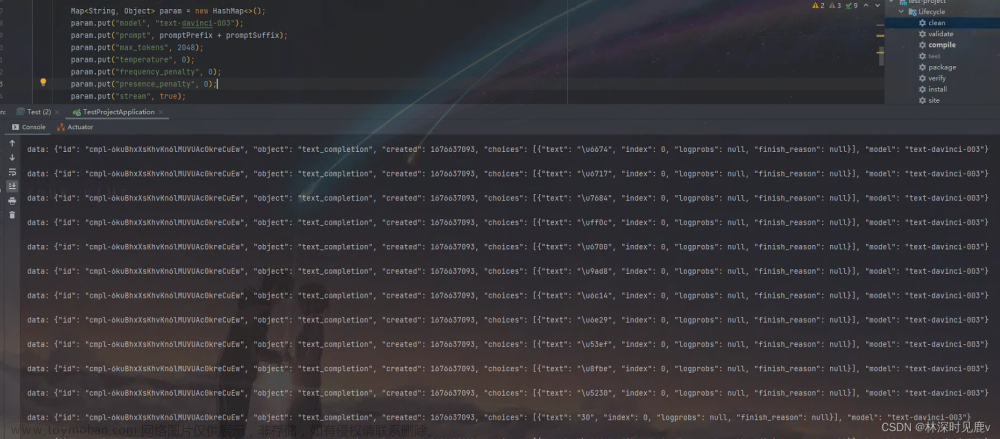
后端运行实时接收与推送数据:
 文章来源:https://www.toymoban.com/news/detail-658171.html
文章来源:https://www.toymoban.com/news/detail-658171.html
总结
效果还是不错的,可以接入AI聊天机器人~~~文章来源地址https://www.toymoban.com/news/detail-658171.html
到了这里,关于Java实现AI机器人聊天的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!












