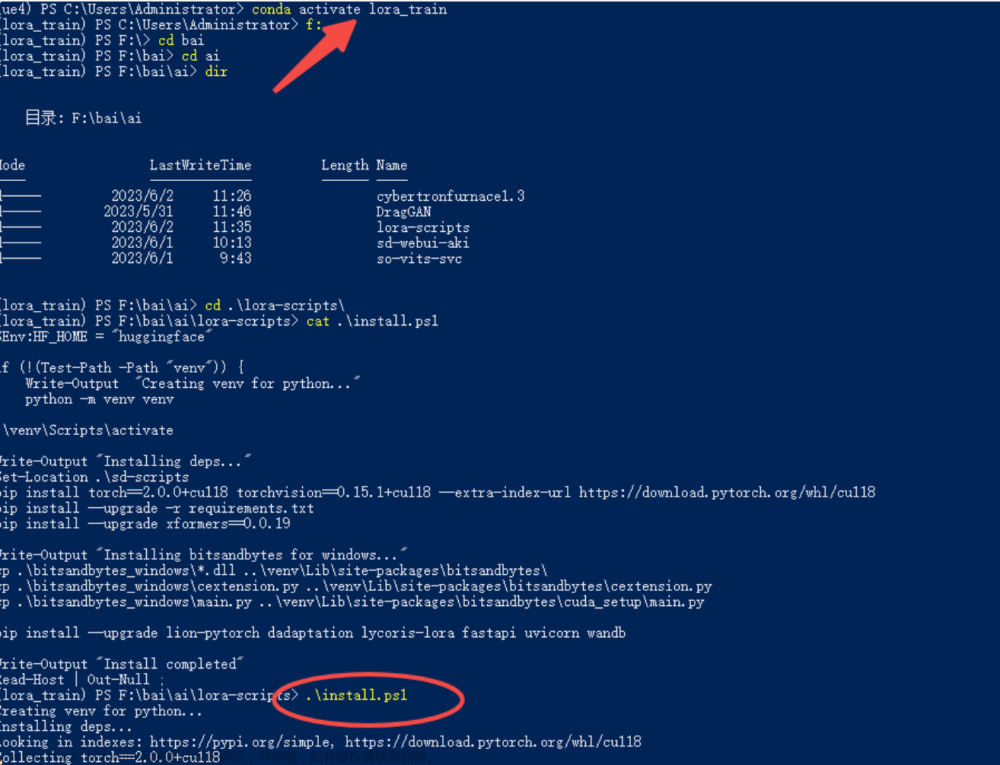
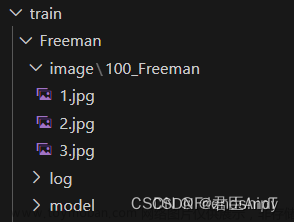
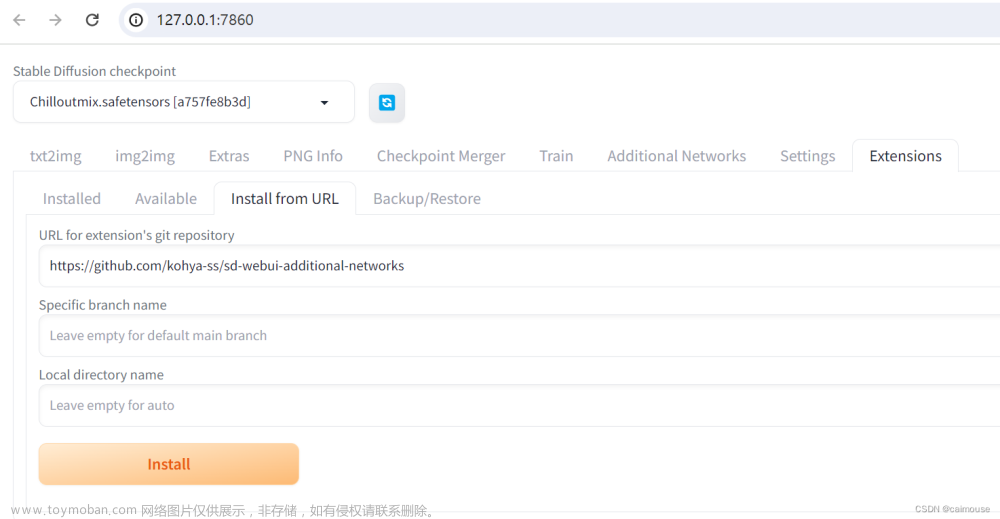
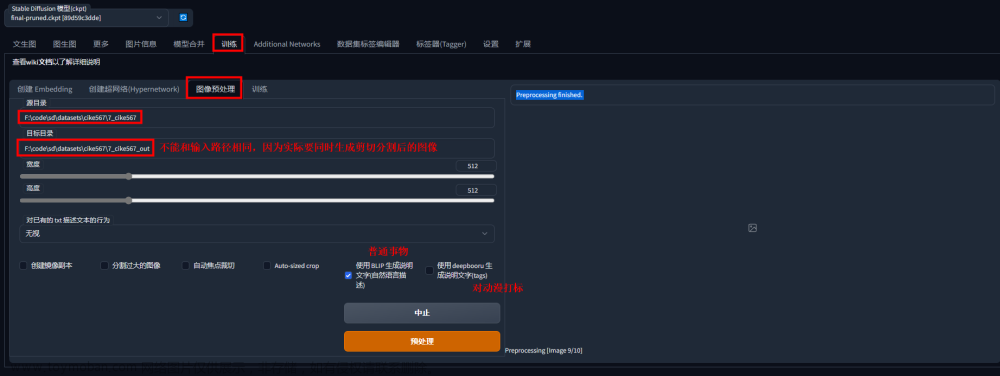
以下内容参考:https://www.bilibili.com/video/BV1Qk4y1E7nv/?spm_id_from=333.337.search-card.all.click&vd_source=3969f30b089463e19db0cc5e8fe4583a
1、训练Lora的2个重点步骤
第一步,准备训练要使用的图片,即优质的图片
第二部,为这些图片打标,即精准的tag
2、图片要求
数量建议20-50张,最多100张图片
不好的图片:模糊的,动作扭曲的,脸部被遮挡的,背景比较复杂的图(扣掉背景)
分辨率:如果以sd2作为基础模型,需要768*768以上
批量调整图片尺寸:https://www.birme.net/?target_width=512&target_height=512
批量调整图片格式:https://www.wdku.net/image/imageformat
3、图片打标
需要安装两个插件:
Tagger(地址:https://github.com/picobyte/stable-diffusion-webui-wd14-tagger) 以及 dataset tag editor(地址:https://github.com/toshiaki1729/stable-diffusion-webui-dataset-tag-editor)
(1)Tagger插件
图片生成tag信息的txt文件,通常输入目录和输出目录一致。

(2)Dataset Tag Editor
对tag进行处理
1)删除重复的单词,Remove duplicate tags
2)删除属于人物特征的tag,比如人物的眼睛、眉毛、鼻子、头发长度等代表人物本身的属性。凡是绑定在人物身上的,就要把它们删除。(因为后续我们需要根据lora名称直接生成这些特征,所以需要模型根据lora名称直接学到这些特征,而不需要再提供其他提示词)
以下内容参考: https://www.jianshu.com/p/e8cb3ba45b1a
4、训练
安装训练图形化工具kohya,日本人写的。
(1)下载
工程地址:https://github.com/bmaltais/kohya_ss
下载后在服务器的位置:/data/work/xiehao/kohya_ss
(2)安装工程依赖包
进入该目录,安装依赖包:pip install -r requirements.txt
(3)生成执行的配置文件
执行accelerate config命令,我的配置如下:

(4)启动训练图形化界面
执行命令:python kohya_gui.py --listen 0.0.0.0 --server_port 12348 --inbrowser

5、实战
(1)从百度下载了25张zhangluyi的图片

(2)图片裁剪为768*768
https://www.birme.net/?target_width=768&target_height=768
(3)图片都转为jpt格式
https://www.wdku.net/image/imageformat
(4)使用Tag插件提取tag
批量提取的方式

执行后在linux上生成了相应的txt文件
(5)通过Dataset Tag Editor处理标签

首先,移除重复项以及人物特征提示词

然后,保存这次修改。


(6)在SD的训练模块对训练集的文件名进行处理

生成的文件信息如下:

这些文件需要放在10_zly的目录下。目录名前面数字_字母,前面的数字是每次训练过程中网络训练单张图片的次数,这个目录命名很重要,定位这个bug花了我一个小时。
(7)在kohya中进行训练
完成数据集准备之后,就可以在kohya进行训练了。
首先,配置基座模型信息。

提供的模型有两种方式:
【方案1】
Pretrained model name or path指定的linux位置对应的模型,需要包含model_index.json、tokenizer目录等信息,不能只有一个safetensors文件。可以通过git lfs clone下载https://huggingface.co/digiplay/majicMIX_realistic_v4(18G)。
 这个关键点很重要,定位加下载处理花了我几个小时。
这个关键点很重要,定位加下载处理花了我几个小时。
【方案2】
Pretrained model name or path中填写safetensors文件路径,
然后在kohya的根目录下存放两个文件
文件1:openai/clip-vit-large-patch14

文件2:laion/CLIP-ViT-bigG-14-laion2B-39B-b160k

这两个文件可以从Huggingface中下载,或者从百度云盘下载:百度网盘 请输入提取码
然后,配置训练目录

接着,配置训练参数

Optimizer这个不能使用默认的值,目前源码中只支持如下5种:

一个个试过去,看下哪个不报错。
成功执行后日志如下图所示,训练占用6G左右的GPU显存资源,训练时长20分钟,最后生成的lora 10M左右。

(8)在stable diffusion webui中检测lora模型效果
训练完成后,将Lora目录放到sd根目录extensions/sd-webui-additional-networks/models/lora下面
Webui上界面操作如下:文章来源:https://www.toymoban.com/news/detail-659115.html
 文章来源地址https://www.toymoban.com/news/detail-659115.html
文章来源地址https://www.toymoban.com/news/detail-659115.html
到了这里,关于Stable Diffusion训练Lora模型的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!