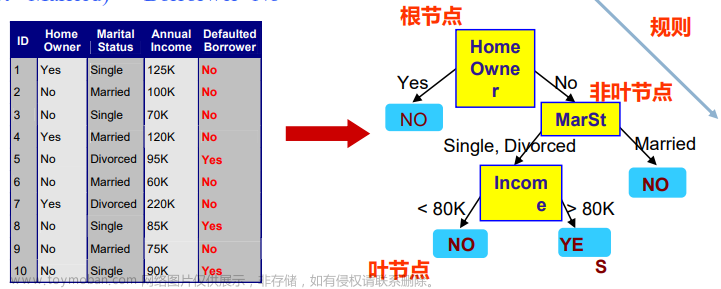
这个是全部文档目录
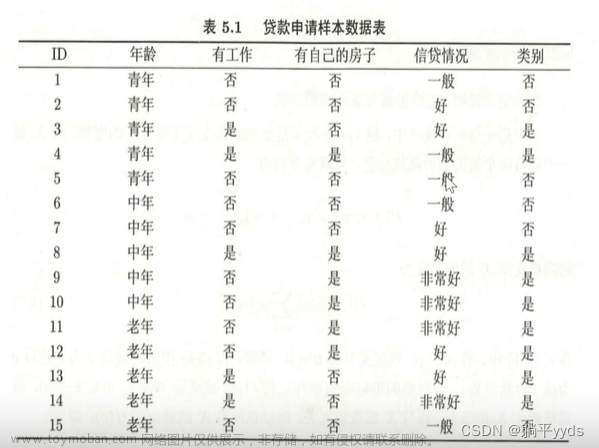
西瓜数据集D如下:
| 编号 | 色泽 | 根蒂 | 敲声 | 纹理 | 脐部 | 触感 | 好瓜 |
|---|---|---|---|---|---|---|---|
| 1 | 青绿 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 是 |
| 2 | 乌黑 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 是 |
| 3 | 乌黑 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 是 |
| 4 | 青绿 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 是 |
| 5 | 浅白 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 是 |
| 6 | 青绿 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 是 |
| 7 | 乌黑 | 稍蜷 | 浊响 | 稍糊 | 稍凹 | 软粘 | 是 |
| 8 | 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 硬滑 | 是 |
| 9 | 乌黑 | 稍蜷 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 否 |
| 10 | 青绿 | 硬挺 | 清脆 | 清晰 | 平坦 | 软粘 | 否 |
| 11 | 浅白 | 硬挺 | 清脆 | 模糊 | 平坦 | 硬滑 | 否 |
| 12 | 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 软粘 | 否 |
| 13 | 青绿 | 稍蜷 | 浊响 | 稍糊 | 凹陷 | 硬滑 | 否 |
| 14 | 浅白 | 稍蜷 | 沉闷 | 稍糊 | 凹陷 | 硬滑 | 否 |
| 15 | 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 否 |
| 16 | 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 硬滑 | 否 |
| 17 | 青绿 | 蜷缩 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 否 |
信息熵: 描述信息的混乱程度,越接近1越混乱(纯度越低),0则不混乱(纯度越高)
- 信息熵是描述集合D的混乱程度(纯度)的值
- 以西瓜数据集为例,前7列(包含编号列)均为属性列,不是划分类别的指标,此例上一个瓜是否为好瓜是判断类别的唯一标准,则按照好瓜(是),好瓜(否)分为2类,即二分类问题
- 故D的信息熵仅由最后一列(好瓜)进行计算
- 简单看来:
- 好瓜的比例:(记为P(好瓜));
- 坏瓜的比例:(记为P(坏瓜)),
- 进行一次对比,最混乱情况也就是各一半,纯度最高情况则全部是好瓜/坏瓜.
- 如出现多个类别,则每个类别占比相同时最混乱,只有一个类别数据时纯度最高
- 举例说明
- (例1) 情况1.2的纯度大于情况1.1
( 情况 1.1 ) : P 好瓜 = 1 2 , P 坏瓜 = 1 2 (情况1.1):P_{ 好瓜} = \frac12,P_{坏瓜} = \frac12 (情况1.1):P好瓜=21,P坏瓜=21
( 情况 1.2 ) : P 好瓜 = 1 10 , P 坏瓜 = 9 10 (情况1.2):P_{ 好瓜} = \frac1{10},P_{坏瓜} = \frac9{10} (情况1.2):P好瓜=101,P坏瓜=109 - (例2) 情况2.2的纯度大于情况2.1
( 情况 2.1 ) : P 好瓜 = 2 10 , P 坏瓜 = 8 10 (情况2.1):P_{ 好瓜} = \frac2{10},P_{坏瓜} = \frac8{10} (情况2.1):P好瓜=102,P坏瓜=108
( 情况 2.2 ) : P 好瓜 = 1 10 , P 坏瓜 = 9 10 (情况2.2):P_{ 好瓜} = \frac1{10},P_{坏瓜} = \frac9{10} (情况2.2):P好瓜=101,P坏瓜=109 - 这样看来,在二分类问题中,取每个情况取最大的pk,比较大小,越大的纯度越高即可
- 但是三分类问题就会有点问题
- (例3) 情况3.2的纯度大于情况3.1
( 情况 3.1 ) : P 1 = 6 10 , P 2 = 2 10 , P 3 = 2 10 (情况3.1):P_1 = \frac6{10},P_2 = \frac2{10},P_3 = \frac2{10} (情况3.1):P1=106,P2=102,P3=102
( 情况 3.2 ) : P 1 = 6 10 , P 2 = 3 10 , P 3 = 1 10 (情况3.2):P_1 = \frac6{10},P_2 = \frac3{10},P_3 = \frac1{10} (情况3.2):P1=106,P2=103,P3=101
- (例1) 情况1.2的纯度大于情况1.1
- 在例3的情况下,仅仅比较最大值6/10都是一样的,那么就需要比较第二大的值,3/10>2/10,故3.2的纯度大于情况3.1
- 由此可见,比较两个样本D信息熵的方法有了
- 但是不太方便,如果要用一个值来量化纯度(混乱程度),思路很清晰,同一个情况(一个集合D)中的分类占比越大,则对纯度程度的贡献就越大.即在(情况3.2)中 6/10的纯度意义 > 3/10 > 1/10
- 使用log函数可以实现8提到的要求.pk值越小,则log(pk)会更小.选用以2为底的对数函数,故当前样本集合D中第k类样本所占比例为pk(k=1,2,3,…,|y|),则D的信息熵为:
E n t ( D ) = − ∑ k = 1 ∣ y ∣ p k l o g 2 p k Ent(D) = -\sum\limits _{k=1}^{|y|}p_klog_2p_k Ent(D)=−k=1∑∣y∣pklog2pk
信息增益: 使用某个属性a对样本集D进行划分所能获得的纯度提升程度
- 计算信息增益的目的,是选出一个属性,可以最大的划分数据
- 则:
信息增益 = 混乱程度 − 使用 a 进行划分后的混乱程度 信息增益 = 混乱程度 - 使用a进行划分后的混乱程度 信息增益=混乱程度−使用a进行划分后的混乱程度 - 则:
使用 a 进行划分后的混乱程度 = 即每个子集的混乱程度乘以各自的权重之和 使用a进行划分后的混乱程度 = 即每个子集的混乱程度乘以各自的权重之和 使用a进行划分后的混乱程度=即每个子集的混乱程度乘以各自的权重之和 - 又混乱程度可以使用信息熵Ent(D)进行计算
- 则可以推导,计算公式为:
G a i n ( D , a ) = E n t ( D ) − ∑ v = 1 V ∣ D v ∣ ∣ D ∣ E n t ( D v ) Gain(D,a) = Ent(D) - \sum\limits _{v=1}^V \frac{|Dv|}{|D|}Ent(D^v) Gain(D,a)=Ent(D)−v=1∑V∣D∣∣Dv∣Ent(Dv)
- 注:
∣ D ∣ 即表示集合 D 中的元素个数 |D| 即表示集合D中的元素个数 ∣D∣即表示集合D中的元素个数
以西瓜数据集举例说明
- D包含若干属性,若使用某个属性a(即样本中的某列,例如色泽)对D进行划分,将D划分为多个子集
- 以西瓜数据为例,如使用属性色泽进行划分,则一共有3个属性值,则将全部数据划分为3个子集,即:
D 按照色泽划分 = D 青绿 ∪ D 乌黑 ∪ D 浅白 D_{按照色泽划分} = D_{青绿} \cup D_{乌黑} \cup D_{浅白} D按照色泽划分=D青绿∪D乌黑∪D浅白 - 故a在D上的信息增益为:
G a i n ( D , 色泽 ) = E n t ( D ) − ( ∣ D 青绿 ∣ ∣ D ∣ E n t ( D 青绿 ) + ∣ D 乌黑 ∣ ∣ D ∣ E n t ( D 乌黑 ) + ∣ D 浅白 ∣ ∣ D ∣ E n t ( D 浅白 ) ) Gain(D,{色泽}) = Ent(D) - (\frac{|D_{青绿}|}{|D|}Ent(D_{青绿}) +\frac{|D_{乌黑}|}{|D|}Ent(D_{乌黑})+ \frac{|D_{浅白}|}{|D|}Ent(D_{浅白}) ) Gain(D,色泽)=Ent(D)−(∣D∣∣D青绿∣Ent(D青绿)+∣D∣∣D乌黑∣Ent(D乌黑)+∣D∣∣D浅白∣Ent(D浅白)) - 可以看出,属性(色泽)对样本集D进行划分所能获得的纯度提升程度即为:Gain(D,色泽). 如每次都选择提升程度最大的一个,则决策树的分支越少.
文章来源地址https://www.toymoban.com/news/detail-659252.html
文章来源:https://www.toymoban.com/news/detail-659252.html
到了这里,关于信息熵,信息增益,增益率的理解的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!