一、数据解析方式
爬虫抓取到整个页面数据之后,我们需要从中提取出有价值的数据,无用的过滤掉。这个过程称为数据解析,也叫数据提取。数据解析的方式有多种,按照网站数据来源是静态还是动态进行分类,如下:
- 动态网站:字典取值。动态网站的数据一般都是JS发过来的,基本都是json格式数据,我们只需要将json格式转换为字典进行取值。
- 静态网站:xpath取值 + 正则取值。
说明:爬虫开发中,用的最多的数据解析方式是字典取值和xpath取值,占到80%以上,其余的少部分是正则取值。
二、xpath介绍
xpath全称XML Path Language,即XML路径语言。它是一门在XML文档中查找信息的语言,最初是用来搜寻XML文档的,但是它同样适用于HTML文档的搜索。
xpath的选择功能十分强大,它提供了非常简明的路径选择表达式。另外,它还提供了众多的内建函数,用于字符串、数值、时间的匹配处理等,几乎所有我们想要定位的节点,都可以用XPath来选择。
三、环境安装
1. 插件安装
很多爬虫的初学者由于对解析工具语法的不熟练,经常会有这种情况:抓来的数据经过解析之后发现不是自己要的,就会多次调试代码,直至提取出精确的价值数据,这样就会导致爬虫多次频繁请求网站,结果自己的IP被网站封掉。那有没有好的办法规避这种情况呢?
有的,Chrome浏览器支持众多插件,其中就有适合xpath语法的元素查找插件:XPath Helper,在谷歌应用商店可以搜索安装,安装好之后图标如下图所示:

使用该插件的方法很简单,在Chrome浏览器中,打开任意网页之后,同时按下 Ctrl+Shift+X 键就可以看到网页上方的XPath Helper调试窗口,左边窗口是要输入的xpath语法,右边窗口是该xpath语法定位出的结果展示。这样就非常方便我们写爬虫项目,如果不确定解析出的结果是不是我们想要的,就可以先在调试窗口中多次调试,结果没有错误,再直接把该代码复制到我们的爬虫代码中运行,如下图:

2. 依赖库安装
在Python代码中,若要使用xpath解析,需要安装lxml这个第三方库,它对xpath语法提供了良好的支持,安装lxml库步骤如下:
1.同时按下win + R键,打开运行框,在里面输入cmd,点击确定。

2.来到控制台中,输入安装命令:pip install lxml -i https://mirrors.aliyun.com/pypi/simple/,然后按下回车键,等候安装完成,出现“Successfully installed …”字样即为安装成功。

四、xpath语法
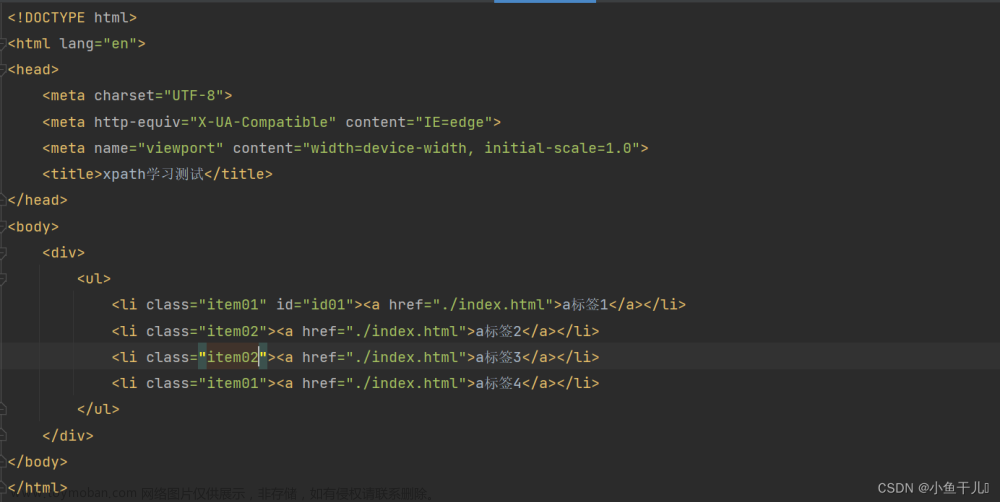
xpath语法,也叫xpath路径表达式。因为xpath查找内容是按照HTML代码的标签树结构搜索的,每一个标签都有自己的父标签和子标签,比如下图这组HTML代码所示:
<body>
<div>
<a href="/ershoufang/dongcheng/" title="北京东城在售二手房 ">东城</a>
<a href="/ershoufang/xicheng/" title="北京西城在售二手房 ">西城</a>
<a href="/ershoufang/chaoyang/" title="北京朝阳在售二手房 ">朝阳</a>
<a href="/ershoufang/haidian/" title="北京海淀在售二手房 ">海淀</a>
</div>
</body>
代码中的 body 标签就是 div 标签的父标签,同理,div 标签是 body 标签的子标签。标签之间的这种父子关系用xpath语法表示的话就是用 / 分隔,比如我们要找 a 标签,xpath写法就是:div/a,或者 body/div/a。这种就类似我们的电脑上面文件路径表示方法,故而,xpath语法又叫xpath路径表达式。
看到上面这些,有的小伙伴可能会纳闷:既然找 a 标签,干嘛不直接写 a 就行了,怎么写这么多父子关系进行约束呢?是不是多此一举了?

没关系,看看下面这组代码图片:

如果说要在上面这组代码中找到高亮显示的这行 “2室1厅 | 53平米 | 南 北 | 精装 | 中楼层(共5层) | 板楼” 文字,单单输入 span 标签能找到吗?显然不能,因为里面有多个 span 标签,所以,使用xpath路径表达式的用意,就是希望使用标签的父子关系约束,来精确定位到我们要找的那个标签。
讲了这么多,接下来我们就看看xpath路径表达式的常用规则。使用xpath规则匹配查找的源码如下:
<body>
<div>
<a href="/ershoufang/dongcheng/" title="北京东城在售二手房 ">东城</a>
<a href="/ershoufang/xicheng/" title="北京西城在售二手房 ">西城</a>
<a href="/ershoufang/chaoyang/" title="北京朝阳在售二手房 ">朝阳</a>
</div>
</body>
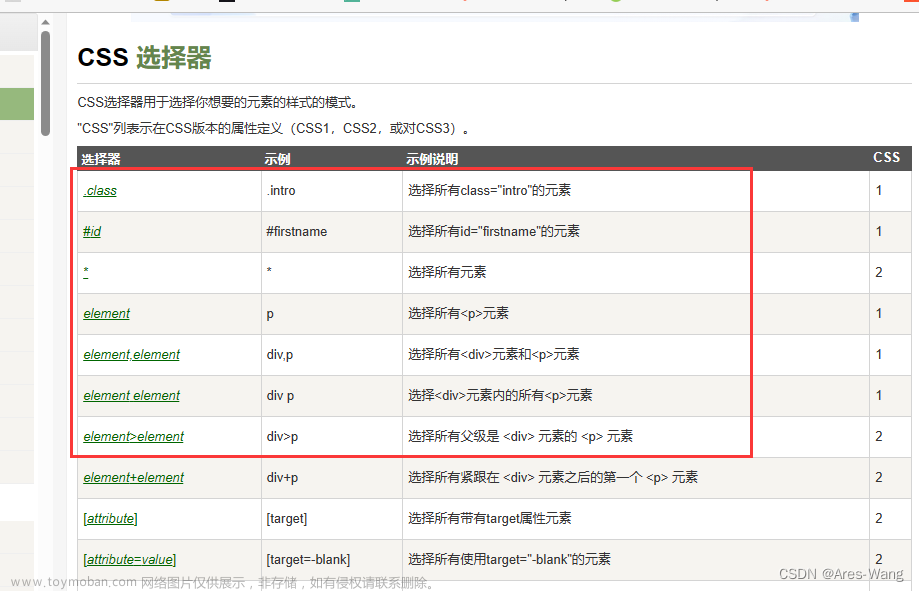
/ 表示两个相邻元素节点关系,也可以说父子关系
用法示例:如果要找上述代码中的 a 标签,路径表达式为:div/a
注意:如果当前查找出来的标签有多个,比如上面查找到的 a 标签有3个,我们想要第2个,写法就是 div/a[2],同理,我们需要第几个标签,就在标签后面加上[顺序值]
// 表示两个不相邻元素节点关系,也可以说爷孙这种隔代关系
用法示例:还是从上述代码中找 a 标签,路径表达式还可以写为:body//a
注意:// 也表示从任意位置开始检索,而不考虑它们的位置。xpath查找标签的顺序正常是从HTML文档头部开始查找,当一个HTML文档中标签非常多,我们查找的标签位于文档的中间某位置。如果直接从头部标签开始一级级往下检索,非常繁琐。用 “// + 标签名” 就相当于从该标签开始检索书写。比如我们还是要找 a 标签,可以写成 //a。
. 指代当前节点,比如xpath路径表达式找到某个元素后,想在此元素基础上往后面查找其他元素,那么前面的路径表达式就可以省略,用 . 替换
@ 选取属性,作用就是更精确定位某个标签
用法示例:比如上面我们正常查找的 a 标签是有3个,我们还是要找第2个 a 标签,已经学了一种方法就是 a 标签后面加上[顺序值]。但是如果 a 标签有几十个呢,我们就要一个个数顺序,很繁琐也容易出错。这时候就可以通过标签自身的属性值来精确定位某个标签。我们仔细可以看出上面的每个 a 标签里面的 href 和 title 两个属性值都是彼此不同的,那我们要找第2个,可以这样写://a[@href=“/ershoufang/xicheng/”] 或者 //a[@title="北京西城在售二手房 "]。格式就是:标签名[@属性名=属性值]
text() 提取标签中的文本内容
用法示例:上面的几种方式定位的都是某个标签,如果要拿到标签中的详细内容,比如要拿到第2个 a 标签的文本内容 “西城”这两个字,写法是://a[@title="北京西城在售二手房 "]/text()。格式是:标签/text()
注意:/text()一定要写在标签及标签属性值后面,因为属性值是修饰该标签的,可以精确定位到某个标签,其次后面才加/text(),表示该标签的文本内容。当然定位的标签如果无需属性值作为修饰即可找到,则直接就是标签名加上/text()。
@属性名 提取标签内指定属性名的属性值
用法示例:上面我们提取了标签的文本内容,但是有时候可能需要提取标签内的某个属性名对应的属性值。比如要提取第2个 a 标签中 title 的属性值 “北京西城在售二手房” 这句话,写法是://a[@title="北京西城在售二手房 "]/@title 或者 //a[2]/@title 都可以。格式是:标签/@属性名
以上就是开发中最常见的xpath表达式,记住这些对于日后解析爬虫来说就完全够用了。当然xpath还有许多其他路径表达式,有兴趣的小伙伴也可以额外探索。
五、xpath语法在Python代码中的使用
上面介绍的只是xpath路径表达式,但是如何实际在Python代码中使用呢?这就需要用到上面提到的依赖库 lxml 了。因为我们用爬虫抓取到的网页源码虽然是HTML文档,但是其实是字符串类型的数据,如下图抓取房源信息代码所示:

而xpath解析的是html或者lxml文档中的标签元素对象,不是字符串。我们就需要将抓到的字符串类型源码转换为html或者lxml文档中的标签元素对象,然后就可以正常使用xpath路径表达式进行解析查找。
如何将字符串内容转换成标签元素对象,要使用 lxml 库里面的 etree 模块中的 HTML() 方法,语法格式如下:
from lxml import etree # 导入 lxml 库中的 etree 模块
变量名 = etree.HTML(网页源码) # 使用 etree 模块的 HTML() 方法,括号中就是爬虫拿到的字符串类型的网页源码,将转换后的标签对象用变量保存
代码示例如下图所示:

转换为标签元素对象之后,就可以正常使用上面介绍的xpath路径表达式了,语法格式如下:
标签元素对象.xpath('路径表达式') # 标签元素对象就是我们刚刚转换好的,括号里面的是双引号或者单引号都可以,包裹的就是路径表达式
代码示例如下图所示:
 文章来源:https://www.toymoban.com/news/detail-659479.html
文章来源:https://www.toymoban.com/news/detail-659479.html
注意:在Python代码中,xpath路径表达式最终拿到的解析结果是以列表形式返回的,如果没有解析到目标数据,结果为空列表。文章来源地址https://www.toymoban.com/news/detail-659479.html
到了这里,关于Python爬虫解析工具之xpath使用详解的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!