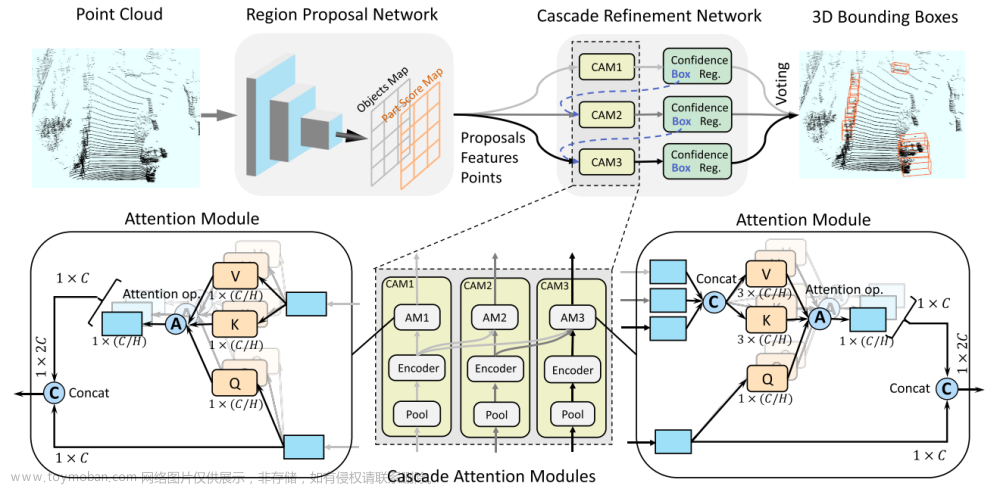
一、与图像相比,基于点云的目标检测一直面临着一些挑战:
1、非结构化数据:点云作为场景中点的位置具有稀疏和非结构化的性质,因此它们的密度和数量都随着场景中对象而变化。
2、不变性排列:点云本质上是一长串点(nx3矩阵,其中n是点数)。 在几何上,点的顺序不影响它在底层矩阵结构中的表示方式,例如, 相同的点云可以由两个完全不同的矩阵表示。
3、实时性要求:由于自动驾驶汽车需要非常快速地做出反应,因此必须实时执行物体检测。这意味着检测网络必须在两次扫描之间的时间间隔内提供结果。
4、点云数量上的变化:在图像中,像素的数量是一个给定的常数,取决于相机。 然而,点云的数量可能会有很大的变化,这取决于各种传感器。
二、基于3D点云的目标检测概述:
检测步骤:
(1)数据表示:存在两种主要的数据表示方法:将点云转换为“体素”、“柱子”或“平截头体”或基于投影(鸟瞰图)等结构,或者直接处理点云原始数据。
(2)特征提取:最常用的特征类型是①局部特征②全局特征③场景特征
逐点特征提取器 Point-wise feature extractors
处理原始点云,PointNet、PointNet++ ,精度高、内存需求高、计算复杂度高
分段特征提取器 Segment-wise feature extractors
处理体素特征, VoxelNet,实时性好
(3)基于模型的检测:提取特征后,需要一个检测网络来生成上下文特征(例如对象类、边界框)并最终输出模型预测。基于检测器网络架构,可用类型大致可分为两类:①两步法: R-CNN、Faster R-CNN 或 PointRCNN 、②一步法:YOLO 或 SSD
一步法目标检测器在一个步骤中执行建议区域、分类和边界框回归,这使得它们明显更快,因此更适合实时应用。但在许多情况下,两步法检测器往往会获得更好的准确度。
三、计算机视觉小目标检测概述:
1、小目标的定义:
(1)基于相对尺度:例如①目标边界框的宽高与图像的宽高比例小于一定值,较为通用的比例值为0.1;②目标边界框面积与图像面积的比值开方小于一定值,较为通用的值为0.03;③根据目标实际覆盖像素与图像总像素之间比例来对小目标进行定义。
(2)基于绝对尺度:目前最为通用的定义来自于目标检测领域的通用数据集——MS COCO数据集,将小目标定义为分辨率小于32像素×32像素的目标。
2、小目标检测面对的难题:
(1) 可利用特征少
(2) 定位精度要求高
(3) 现有数据集中小目标占比少
(4) 样本不均衡问题
(5) 小目标聚集问题
(6) 网络结构原因
3、小目标检测研究思路:
(1)数据增强:提升小目标检测性能的最简单和有效的方法,通过不同的数据增强策略可以扩充训练数据集的规模,丰富数据集的多样性,从而增强检测模型的鲁棒性和泛化能力。增强方法有:复制增强、自适应采样、尺度匹配、缩放与拼接、自学习数据增强。
数据增强这一策略虽然在一定程度上解决了小目标信息量少、缺乏外貌特征和纹理等问题,有效提高了网络的泛化能力,在最终检测性能上获得了较好的效果,但同时带来了计算成本的增加。而且在实际应用中,往往需要针对目标特性做出优化,设计不当的数据增强策略可能会引入新的噪声,损害特征提取的性能,这也给算法的设计带来了挑战。
(2)多尺度学习:小目标同时需要深层语义信息与浅层表征信息,而多尺度学习将这两种相结合,是一种提升小目标检测性能的有效策略。早期方法:使用不同大小的卷积核通过不同的感受野大小来获取不同尺度的信息,计算复杂被弃用。目前使用的四种方法:①图像金字塔、②利用较浅层的特征图来检测较小的目标,而利用较深层的特征图来检测较大的目标、③多尺度融合网络、④特征金字塔FPN(Feature Pyramid network)
多尺度特征融合同时考虑了浅层的表征信息和深层的语义信息,有利于小目标的特征提取,能够有效地提升小目标检测性能。然而,现有多尺度学习方法在提高检测性能的同时也增加了额外的计算量,并且在特征融合过程中难以避免干扰噪声的影响,这些问题导致了基于多尺度学习的小目标检测性能难以得到进一步提升。
(3)上下文学习:在真实世界中,“目标与场景”和“目标与目标”之间通常存在一种共存关系,通过利用这种关系将有助于提升小目标的检测性能。通过对上下文进行适当的建模可以提升目标检测性能,尤其是对于小目标这种外观特征不明显的目标:基于隐式上下文特征学习和基于显式上下文推理的目标检测。
基于上下文学习的方法充分利用了图像中与目标相关的信息,能够有效提升小目标检测的性能。但是,已有方法没有考虑到场景中的上下文信息可能匮乏的问题,同时没有针对性地利用场景中易于检测的结果来辅助小目标的检测。未来的研究方向可以从以下两个角度出发:(1)构建基于类别语义池的上下文记忆模型,通过利用历史记忆的上下文来缓解当前图像中上下文信息匮乏的问题;(2)基于图推理的小目标检测,通过图模型和目标检测模型的结合来针对性地提升小目标的检测性能。
(4)生成对抗学习:通过将低分辨率小目标的特征映射成与高分辨率目标等价的特征,从而达到与尺寸较大目标同等的检测性能:一种有效的方法是通过结合生成对抗网络(Generative adversarial network, GAN)来提高小目标的分辨率,缩小小目标与大/中尺度目标之间的特征差异,增强小目标的特征表达,进而提高小目标检测的性能。
基于生成对抗模型的目标检测算法通过增强小目标的特征信息,可以显著提升检测性能。同时,利用生成对抗模型来超分小目标这一步骤无需任何特别的结构设计,能够轻易地将已有的生成对抗模型和检测模型相结合。但是,目前依旧面临两个无法避免的问题:(1)生成对抗网络难以训练,不易在生成器和鉴别器之间取得好的平衡;(2)生成器在训练过程中产生样本的多样性有限,训练到一定程度后对于性能的提升有限。
(5)无锚机制:现有的锚框设计难以获得平衡小目标召回率与计算成本之间的矛盾,而且这种方式导致了小目标的正样本与大目标的正样本极度不均衡,使得模型更加关注于大目标的检测性能,从而忽视了小目标的检测。极端情况下,设计的锚框如果远远大于小目标,那么小目标将会出现无正样本的情况。小目标正样本的缺失,将使得算法只能学习到适用于较大目标的检测模型。此外,锚框的使用引入了大量的超参,比如锚框的数量、宽高比和大小等,使得网络难以训练,不易提升小目标的检测性能。一种摆脱锚框机制的思路是将目标检测任务转换为关键点的估计,即基于关键点的目标检测方法。基于关键点的目标检测方法主要包含两个大类:基于角点的检测和基于中心的检测。①基于角点的检测器通过对从卷积特征图中学习到的角点分组来预测目标边界框。②基于中心预测的目标检测框架,称为CenterNet。③代表点(RepPoints)检测方法,这种方法能够自动学习目标的空间信息和局部语义特征,一定程度上提升了小目标检测的精度。④基于全卷积的单级目标检测器FCOS(Fully convolutional one‑stage),避免了基于锚框机制的方法中超参过多、难以训练的问题。
(6)其他优化策略。
4、未来可能的关注点:
(1)特征融合方面。现有的方法通常通过融合深度神经网络中同层的多尺度特征来提升小目标的特征表达能力。尽管这种方式一定程度提升了小目标的检测性能,但是在特征融合的过程中没有考虑到语义间隔和噪声干扰的问题。因此,如何消除特征融合中的语义间隔和噪声干扰问题是未来的一个研究方向。
(2)上下文学习方面。尽管上下文在目标检测中已经得到了充分的重视,并在众多目标检测算法中得到了充分利用。但是,场景中并不是所有上下文信息都是有价值的,无效的上下文信息将可能破坏目标区域的原始特征,如何从图像中挖掘有利于提升小目标区域特征表示的上下文信息是未来的一个研究方向。此外,现有的上下文建模方法对于不同尺度目标是同等对待,并没有针对小目标而做相应的设计。因此,如何在检测模型中利用易于检测目标来辅助小目标的检测是未来的一个重要研究方向。
(3)超分辨率重构方面。尽管已有一些方法通过生成对抗的方式来提升小目标的特征,以此获得与大目标等价的特征表示,并取得了一定的成效。但是,这一类方法研究还尚少,仍有较大的研究空间。超分辨率重构是一种最直接的、可解释的提升小目标检测性能的方法。如何将超分辨率重构中先进技术与目标检测技术深度结合是未来的一个可行研究思路。
四、目标检测相关论文:
(1)目前单阶段网络结构的研究还不是很多,3D目标检测的最终要求要实现实时性能,提高速度,实现一种单阶段网络结构是未来研究的重点。
(2)因为数据集有限,如何使用弱监督来训练网络也可能是未来研究的方向。
(3)如何更加有效地利用融合不同传感器获得的信息一直以来都是研究的重点。
(4)如何提高小目标检测精度是一个值得关注和思考的方向。
《Structure Aware Single-stage 3D Object Detection from Point Cloud》
《Self-training for Unsupervised Domain Adaptation on 3D ObjectDetection》
《HVPR: Hybrid Voxel-Point Representation for Single-stage 3D Object Detection》
《LiDAR R-CNN: An Efficient and Universal 3D Object Detector》
《SE-SSD: Self-Ensembling Single-Stage Object Detector From Point Cloud》
《PVGNet: A Bottom-Up One-Stage 3D Object Detector with Integrated Multi-Level Features》
《3D Object Detection with Pointformer》
《Deep Learning for 3D Point Clouds A Survey》
《A Survey on 3D Object Detection Methods for Autonomous Driving Applications》
《PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation》
《PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space》
五、基于原始点的特征提取:PointNet、PointNet++:
PointNet
(1)输入数据:原始点云{Pi| i = 1, ..., n};Pi=(x, y, z)
无序性,点云是一个点集,没有固定的顺序;
与邻域点又相互作用,点云中的个体不是独立的,与周围的点具相关,具有局域特征;
刚体旋转、平移不变性,旋转和平移不会改变点云的分类、分割结果。
(2)模型:
它直接将点云作为输入,并输出整个输入的类标签或输入的每个点的每个点段/部分标签。在初始阶段,每个点都是相同和独立地处理的。在基本设置中,每个点只用它的三个坐标(x、y、z)来表示。可以通过计算法线和其他局部或全局特征来添加其他维度。
核心函数: max pooling
Effectively the network learns a set of optimization functions/criteria that select interesting or informative points of the point cloud and encode the reason for their selection. The final fully connected layers of the network aggregate these learnt optimal values into the global descriptor for the entire shape as mentioned above (shape classifification) or are used to predict per point labels (shape segmentation).
网络的学习内容:选择点云中的信息点并且编码选择的原因
完全连接层:将学到的最优值聚合到全局描述符做形状分类或分割
处理过程:

模块一: max pooling(作为对称函数聚合所有点的信息)
对称函数:在对称函数中,函数的输出值不随输入变数的排列而改变。从函数的形式中可以看出若输入变数排列后,方程式不会改变。

用多层感知器网络近似h,g用单变量函数和最大池化函数的组成。输出形成了一个向量[f1,...,fK],它是输入集的全局签名。
模块二:Local and Global Information Aggregation
在计算了全局点云特征向量后,我们通过将全局特征与每个点特征连接起来,将其反馈给每个点特征。然后,我们根据结合的点特征提取新的每个点特征——这一次,每个点特征同时了解局部和全局信息。
模块三: Joint Alignment Network(对齐输入点和点特征)
刚性变换:定义为不改变任何两点之间距离的变换,一般这种转换只包括平移和旋转。
如果点云经历了一定的几何变换,如刚性变换,则点云的语义标记必须是不变的。点集学习到的表示对这些变换也是不变的,解决方案:在特征提取之前将所有输入集对齐到一个规范空间。
通过一个小网络(图2中的T-net)来预测一个仿射变换矩阵,并将此转换直接应用于输入点的坐标。
为了降低优化难度,约束特征变换矩阵为接近正交矩阵:

A为由一个小网络预测的特征对齐矩阵
(3)输出:
语义分割:Our model will output n × m scores for each of the n points and each of the m semantic subcategories.
目标分类:Our proposed deep network outputs k scores for all the k candidate classes.
该网络可以通过一组稀疏的关键点来总结一个输入点云,对输入点的小扰动或异常值、缺失数据有着很好的鲁棒性。
详细解释:
https://blog.csdn.net/u014636245/article/details/82755966
PointNet在当时除了有出众的结果,相比于其他网络还有两个显著的优势:
(1)Pointnet更轻量并且执行速度快,PointNet相比于其他网络减少88%浮点运算。
(2)PointNet对数据的缺失更鲁棒,PointNet在丢失50%的数据后,仅仅减少了2%的精度。这说明PointNet学会了如何去挑选感兴趣的点(关键点)。
PointNet还存在明显的缺点:
(1)由于PointNet网络只考虑了全局特征,直接暴力地将所有的点最大池化为了一个全局特征,因此丢失了每个点的局部信息,局部点与点之间的联系并没有被网络学习到。在分类和物体的Part Segmentation中,这样的问题还可以通过中心化物体的坐标轴来部分地解决,但在场景分割中,这就导致效果十分一般了。
(2)虽然PointNet加入了T-Net实现了网络的旋转平移不变性,但相比于CNN实际效果仍然有限。
PointNet++
PointNet提取特征的方式是对所有点云数据提取一个全局特征。显然,这会带来很大的局限性,这也和目前流行的能够逐层提取局部特征的CNN方式不一样。CNN通过分层不断地使用卷积核扫描图像上的像素并做内积,使得越到后面的特征图感受野越大,同时每个像素包含的信息也越多。受CNN的启发,作者借鉴了CNN的多层感受野的思想,提出了PointNet++,它能够在不同尺度提取局部特征,通过多层网络结构得到更深层次的特征。

(1)改进特征提取方法:PointNet++采用了分层抽取特征的思想,把每一次特征提取称为Set Abstraction。Set Abstraction又分为三部分,分别是采样层、分组层、特征提取层。采样层通过FPS(farthest point sampling)最远点采样算法,提取点云中的部分key point。分组层以key point为中心,在某个范围内寻找最近个k近邻点组成group。特征提取层是将这k个点通过PointNet的核心网络进行特征提取。这样每一层得到的中心点都是上一层中心点的子集,并且随着层数加深,中心点的个数越来越少,但是每一个中心点包含的信息越来越多。
(2)解决点云密度不均匀问题:由于雷达传感器的成像特点,离传感器越近的区域点云更密集,越远的地方约稀疏。所以,如果在Group的时候通过在固定范围选取的固定个数的近邻点是不合适的。为此PointNet++提出了两种 “自适应” 点云稠密稀疏的方案,分别是:多尺度组合(multi-scale grouping, MSG) 方式、多分辨率组合(multi-resolution grouping, MRG) 方式。
(3)Set Segmentation
采样层:最远点采样算法(farthest point sampling, FPS),先选定部分点作为局部区域的中心,通过设定需要采样的点云数量来控制模型的计算量,再通过后续网络学习点的局部特征。该算法相对于随机采样算法来说,能够更均匀地覆盖整个采样空间。
组合层:为了提取一个点的局部特征,作者首先将点云数据中的一个点的局部区域定义为由其周围给定半径划出的球形空间内所包含的点集。组合层的作用就是,将采样层选出的每一个点的局部区域中的所包含的点聚集起来,方便后续网络学习每个点的局部特征。
特征提取层:PointNet是一个基于点云数据的特征提取网络,它可以对组合层给出的各个局部进行特征提取来得到局部特征。值得注意的是,虽然组合层给出的各个局部区域可能由不同数量的点云构成,但是通过PointNet后都能得到维度一致的特征,这是由由max函数的特性决定的。
(4)非均匀采样密度下的鲁棒特征学习
①多尺度组合(multi-scale grouping, MSG):
多尺度组合方式的做法相对来说比较直接,它为每个中心点设定不同尺度的半径,使其学习到不同尺度的局部特征,并最后将它们串联在一起。由于需要对每个局部的每个尺度进行特征提取,其计算量的增加也是很显著的。
②多分辨率组合(multi-resolution grouping, MRG):
为了解决多尺度组合(MSG) 计算量大的问题,作者提出了多分辨率组合(MRG) 的方式。该方法由两部分组成,第一部分先对局部区域内的点集划分为更小的区域,在小区域上进行特征学习后,再次通过特征学习网络学习更高维度的特征。第二部分则是直接对局部区域的所有原始点云数据进行特征学习。然后再将两部分学习得到的特征进行拼接。
详细解释:
https://blog.csdn.net/u013086672/article/details/105890875(理论)文章来源:https://www.toymoban.com/news/detail-659505.html
https://zhuanlan.zhihu.com/p/266324173(代码)文章来源地址https://www.toymoban.com/news/detail-659505.html
到了这里,关于基于3D点云的小目标检测学习笔记的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!