前言
过去半年,随着ChatGPT的火爆,直接带火了整个LLM这个方向,然LLM毕竟更多是基于过去的经验数据预训练而来,没法获取最新的知识,以及各企业私有的知识
- 为了获取最新的知识,ChatGPT plus版集成了bing搜索的功能,有的模型则会调用一个定位于 “链接各种AI模型、工具”的langchain的bing功能
- 为了处理企业私有的知识,要么基于开源模型微调,要么更可以基于langchain里集成的向量数据库和LLM搭建本地知识库问答(此处的向量数据库的独特性在哪呢?举个例子,传统数据库做图片检索可能是通过关键词去搜索,向量数据库是通过语义搜索图片中相同或相近的向量并呈现结果)
所以越来越多的人开始关注langchain并把它与LLM结合起来应用,更直接推动了数据库、知识图谱与LLM的结合应用(详见下一篇文章:知识图谱实战导论:从什么是KG到LLM与KG/DB的结合实战)
本文则侧重讲解
- 什么是LangChain及langchain的整体组成架构
- 通过langchain-ChatGLM构建本地知识库问答的基本流程,与每个流程背后的逻辑
- 解读langchain-ChatGLM项目的关键源码,不只是把它当做一个工具使用,因为对工具的原理更了解,则对工具的使用更顺畅
一开始解读不易,因为涉及的项目、技术点不少,所以一开始容易绕晕,好在根据该项目的流程一步步抽丝剥茧之后,给大家呈现了清晰的代码架构
过程中,我从接触该langchain-ChatGLM项目到整体源码梳理清晰并写清楚历时了近一周,而大家有了本文之后,可能不到一天便可以理清了(提升近7倍效率) ,这便是本文的价值和意义之一 - langchain-ChatGLM项目的升级版:langchain-Chatchat
- 我司基于langchain-chatchat二次开发的企业多文档知识库问答系统
阅读过程中若有任何问题,欢迎随时留言,会一一及时回复/解答,共同探讨、共同深挖
第一部分 LangChain的整体组成架构:LLM的外挂/功能库
通俗讲,所谓langchain (官网地址、GitHub地址),即把AI中常用的很多功能都封装成库,且有调用各种商用模型API、开源模型的接口,支持以下各种组件
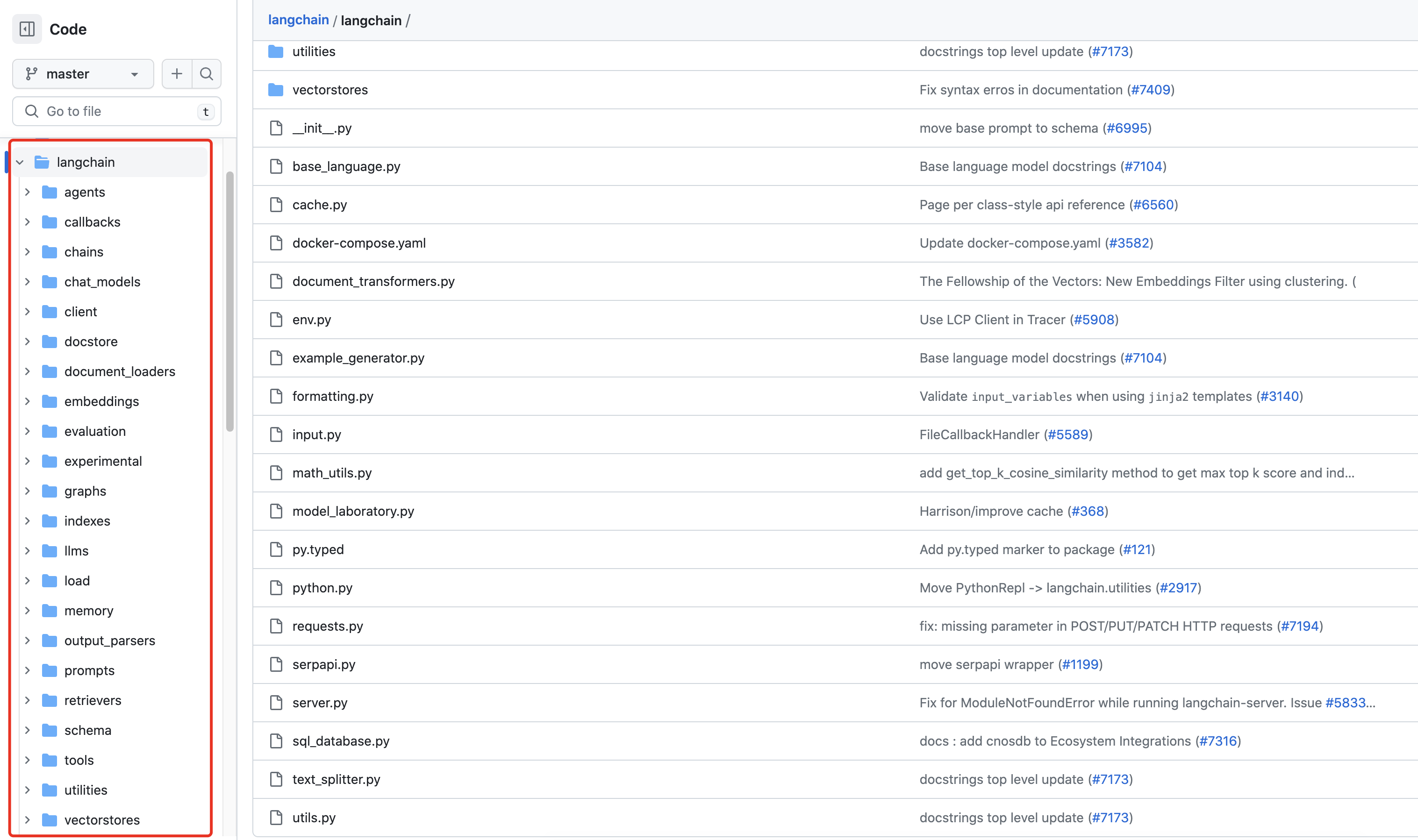
初次接触的朋友一看这么多组件可能直接晕了(封装的东西非常多,感觉它想把LLM所需要用到的功能/工具都封装起来),为方便理解,我们可以先从大的层面把整个langchain库划分为三个大层:基础层、能力层、应用层
1.1 基础层:models、LLMs、index
1.1.1 Models:模型
各种类型的模型和模型集成,比如OpenAI的各个API/GPT-4等等,为各种不同基础模型提供统一接口
比如通过API完成一次问答
import os
os.environ["OPENAI_API_KEY"] = '你的api key'
from langchain.llms import OpenAI
llm = OpenAI(model_name="text-davinci-003",max_tokens=1024)
llm("怎么评价人工智能")得到的回答如下图所示

1.1.2 LLMS层
这一层主要强调对models层能力的封装以及服务化输出能力,主要有:
- 各类LLM模型管理平台:强调的模型的种类丰富度以及易用性
- 一体化服务能力产品:强调开箱即用
- 差异化能力:比如聚焦于Prompt管理(包括提示管理、提示优化和提示序列化)、基于共享资源的模型运行模式等等
比如Google's PaLM Text APIs,再比如 llms/openai.py 文件下
model_token_mapping = {
"gpt-4": 8192,
"gpt-4-0314": 8192,
"gpt-4-0613": 8192,
"gpt-4-32k": 32768,
"gpt-4-32k-0314": 32768,
"gpt-4-32k-0613": 32768,
"gpt-3.5-turbo": 4096,
"gpt-3.5-turbo-0301": 4096,
"gpt-3.5-turbo-0613": 4096,
"gpt-3.5-turbo-16k": 16385,
"gpt-3.5-turbo-16k-0613": 16385,
"text-ada-001": 2049,
"ada": 2049,
"text-babbage-001": 2040,
"babbage": 2049,
"text-curie-001": 2049,
"curie": 2049,
"davinci": 2049,
"text-davinci-003": 4097,
"text-davinci-002": 4097,
"code-davinci-002": 8001,
"code-davinci-001": 8001,
"code-cushman-002": 2048,
"code-cushman-001": 2048,
}1.1.3 Index(索引):Vector方案、KG方案
对用户私域文本、图片、PDF等各类文档进行存储和检索(相当于结构化文档,以便让外部数据和模型交互),具体实现上有两个方案:一个Vector方案、一个KG方案
1.1.3.1 Index(索引)之Vector方案
对于Vector方案:即对文件先切分为Chunks,在按Chunks分别编码存储并检索,可参考此代码文件:langchain/libs/langchain/langchain/indexes /vectorstore.py
该代码文件依次实现
模块导入:导入了各种类型检查、数据结构、预定义类和函数
接下来,实现了一个函数_get_default_text_splitter,两个类VectorStoreIndexWrapper、VectorstoreIndexCreator
_get_default_text_splitter 函数:
这是一个私有函数,返回一个默认的文本分割器,它可以将文本递归地分割成大小为1000的块,且块与块之间有重叠
# 默认的文本分割器函数
def _get_default_text_splitter() -> TextSplitter:
return RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0)为什么要进行切割?
原因很简单, embedding(text2vec,文本转化为向量)以及 LLM encoder 对输入 tokens 都有限制。embedding 会将一个 text(长字符串)的语义信息压缩成一个向量,但其对 text 包含的 tokens 是有限制的,一段话压缩成一个向量是 ok,但一本书压缩成一个向量可能就丢失了绝大多数语义
接下来是,VectorStoreIndexWrapper 类:
这是一个包装类,主要是为了方便地访问和查询向量存储(Vector Store)
- vectorstore: 一个向量存储对象的属性
vectorstore: VectorStore # 向量存储对象 class Config: """Configuration for this pydantic object.""" extra = Extra.forbid # 额外配置项 arbitrary_types_allowed = True # 允许任意类型 - query: 一个方法,它接受一个问题字符串并查询向量存储来获取答案
解释一下上面出现的提取器
# 查询向量存储的函数 def query( self, question: str, # 输入的问题字符串 llm: Optional[BaseLanguageModel] = None, # 可选的语言模型参数,默认为None retriever_kwargs: Optional[Dict[str, Any]] = None, # 提取器的可选参数,默认为None **kwargs: Any # 其他关键字参数 ) -> str: """Query the vectorstore.""" # 函数的文档字符串,描述函数的功能 # 如果没有提供语言模型参数,则使用OpenAI作为默认语言模型,并设定温度参数为0 llm = llm or OpenAI(temperature=0) # 如果没有提供提取器的参数,则初始化为空字典 retriever_kwargs = retriever_kwargs or {} # 创建一个基于语言模型和向量存储提取器的检索QA链 chain = RetrievalQA.from_chain_type( llm, retriever=self.vectorstore.as_retriever(**retriever_kwargs), **kwargs ) # 使用创建的QA链运行提供的问题,并返回结果 return chain.run(question)提取器首先从大型语料库中检索与问题相关的文档或片段,然后生成器根据这些检索到的文档生成答案。
提取器可以基于许多不同的技术,包括:
a.基于关键字的检索:使用关键字匹配来查找相关文档
b.向量空间模型:将文档和查询都表示为向量,并通过计算它们之间的相似度来检索相关文档
c.基于深度学习的方法:使用预训练的神经网络模型(如BERT、RoBERTa等)将文档和查询编码为向量,并进行相似度计算
d.索引方法:例如倒排索引,这是搜索引擎常用的技术,可以快速找到包含特定词或短语的文档
这些方法可以独立使用,也可以结合使用,以提高检索的准确性和速度 - query_with_sources: 类似于query,但它还返回与查询结果相关的数据源
# 查询向量存储并返回数据源的函数 def query_with_sources( self, question: str, llm: Optional[BaseLanguageModel] = None, retriever_kwargs: Optional[Dict[str, Any]] = None, **kwargs: Any ) -> dict: """Query the vectorstore and get back sources.""" llm = llm or OpenAI(temperature=0) # 默认使用OpenAI作为语言模型 retriever_kwargs = retriever_kwargs or {} # 提取器参数 chain = RetrievalQAWithSourcesChain.from_chain_type( llm, retriever=self.vectorstore.as_retriever(**retriever_kwargs), **kwargs ) return chain({chain.question_key: question})
最后是VectorstoreIndexCreator 类:
这是一个创建向量存储索引的类
- vectorstore_cls: 使用的向量存储类,默认为Chroma
一个简化的向量存储可以看作是一个大型的表格或数据库,其中每行代表一个项目(如文档、图像、句子等),而每个项目则有一个与之关联的高维向量。向量的维度可以从几十到几千,取决于所使用的嵌入模型
vectorstore_cls: Type[VectorStore] = Chroma # 默认使用Chroma作为向量存储类
例如:
至于这里的Chroma是一种常见的向量数据库,可以通过与LangChain的集成,实现基于语言模型的各种应用Item ID Vector (in a high dimensional space) 1 [0.34, -0.2, 0.5, ...] 2 [-0.1, 0.3, -0.4, ...] ... ... 
- embedding: 使用的嵌入类,默认为OpenAIEmbeddings
顺带说一下,Huggingface 有一个 embedding 的 benchmark:https://huggingface.co/spaces/mteb/leaderboard
embedding: Embeddings = Field(default_factory=OpenAIEmbeddings) # 默认使用OpenAIEmbeddings作为嵌入类 - text_splitter: 用于分割文本的文本分割器
text_splitter: TextSplitter = Field(default_factory=_get_default_text_splitter) # 默认文本分割器 - from_loaders: 从给定的加载器列表中创建一个向量存储索引
# 从加载器创建向量存储索引的函数 def from_loaders(self, loaders: List[BaseLoader]) -> VectorStoreIndexWrapper: """Create a vectorstore index from loaders.""" docs = [] for loader in loaders: # 遍历加载器 docs.extend(loader.load()) # 加载文档 return self.from_documents(docs) - from_documents: 从给定的文档列表中创建一个向量存储索引
# 从文档创建向量存储索引的函数 def from_documents(self, documents: List[Document]) -> VectorStoreIndexWrapper: """Create a vectorstore index from documents.""" sub_docs = self.text_splitter.split_documents(documents) # 分割文档 vectorstore = self.vectorstore_cls.from_documents( sub_docs, self.embedding, **self.vectorstore_kwargs # 从文档创建向量存储 ) return VectorStoreIndexWrapper(vectorstore=vectorstore) # 返回向量存储的包装对象
1.1.3.2 Index(索引)之KG方案
对于KG方案:这部分利用LLM抽取文件中的三元组,将其存储为KG供后续检索,可参考此代码文件:langchain/libs/langchain/langchain/indexes /graph.py
"""Graph Index Creator.""" # 定义"图索引创建器"的描述
# 导入相关的模块和类型定义
from typing import Optional, Type # 导入可选类型和类型的基础类型
from langchain import BasePromptTemplate # 导入基础提示模板
from langchain.chains.llm import LLMChain # 导入LLM链
from langchain.graphs.networkx_graph import NetworkxEntityGraph, parse_triples # 导入Networkx实体图和解析三元组的功能
from langchain.indexes.prompts.knowledge_triplet_extraction import ( # 从知识三元组提取模块导入对应的提示
KNOWLEDGE_TRIPLE_EXTRACTION_PROMPT,
)
from langchain.pydantic_v1 import BaseModel # 导入基础模型
from langchain.schema.language_model import BaseLanguageModel # 导入基础语言模型的定义
class GraphIndexCreator(BaseModel): # 定义图索引创建器类,继承自BaseModel
"""Functionality to create graph index.""" # 描述该类的功能为"创建图索引"
llm: Optional[BaseLanguageModel] = None # 定义可选的语言模型属性,默认为None
graph_type: Type[NetworkxEntityGraph] = NetworkxEntityGraph # 定义图的类型,默认为NetworkxEntityGraph
def from_text(
self, text: str, prompt: BasePromptTemplate = KNOWLEDGE_TRIPLE_EXTRACTION_PROMPT
) -> NetworkxEntityGraph: # 定义一个方法,从文本中创建图索引
"""Create graph index from text.""" # 描述该方法的功能
if self.llm is None: # 如果语言模型为None,则抛出异常
raise ValueError("llm should not be None")
graph = self.graph_type() # 创建一个新的图
chain = LLMChain(llm=self.llm, prompt=prompt) # 使用当前的语言模型和提示创建一个LLM链
output = chain.predict(text=text) # 使用LLM链对文本进行预测
knowledge = parse_triples(output) # 解析预测输出得到的三元组
for triple in knowledge: # 遍历所有的三元组
graph.add_triple(triple) # 将三元组添加到图中
return graph # 返回创建的图
async def afrom_text( # 定义一个异步版本的from_text方法
self, text: str, prompt: BasePromptTemplate = KNOWLEDGE_TRIPLE_EXTRACTION_PROMPT
) -> NetworkxEntityGraph:
"""Create graph index from text asynchronously.""" # 描述该异步方法的功能
if self.llm is None: # 如果语言模型为None,则抛出异常
raise ValueError("llm should not be None")
graph = self.graph_type() # 创建一个新的图
chain = LLMChain(llm=self.llm, prompt=prompt) # 使用当前的语言模型和提示创建一个LLM链
output = await chain.apredict(text=text) # 异步使用LLM链对文本进行预测
knowledge = parse_triples(output) # 解析预测输出得到的三元组
for triple in knowledge: # 遍历所有的三元组
graph.add_triple(triple) # 将三元组添加到图中
return graph # 返回创建的图另外,为了索引,便不得不牵涉以下这些能力
-
Document Loaders,文档加载的标准接口
与各种格式的文档及数据源集成,比如Arxiv、Email、Excel、Markdown、PDF(所以可以做类似ChatPDF这样的应用)、Youtube …
相近的还有
docstore,其中包含wikipedia.py等
document_transformers -
embeddings(langchain/libs/langchain/langchain/embeddings),则涉及到各种embeddings算法,分别体现在各种代码文件中:
elasticsearch.py、google_palm.py、gpt4all.py、huggingface.py、huggingface_hub.py
llamacpp.py、minimax.py、modelscope_hub.py、mosaicml.py
openai.py
sentence_transformer.py、spacy_embeddings.py、tensorflow_hub.py、vertexai.py
1.2 能力层:Chains、Memory、Tools
如果基础层提供了最核心的能力,能力层则给这些能力安装上手、脚、脑,让其具有记忆和触发万物的能力,包括:Chains、Memory、Tool三部分
1.2.1 Chains:链接
简言之,相当于包括一系列对各种组件的调用,可能是一个 Prompt 模板,一个语言模型,一个输出解析器,一起工作处理用户的输入,生成响应,并处理输出
具体而言,则相当于按照不同的需求抽象并定制化不同的执行逻辑,Chain可以相互嵌套并串行执行,通过这一层,让LLM的能力链接到各行各业
- 比如与Elasticsearch数据库交互的:elasticsearch_database
- 比如基于知识图谱问答的:graph_qa
其中的代码文件:chains/graph_qa/base.py 便实现了一个基于知识图谱实现的问答系统,具体步骤为
首先,根据提取到的实体在知识图谱中查找相关的信息「这是通过 self.graph.get_entity_knowledge(entity) 实现的,它返回的是与实体相关的所有信息,形式为三元组」
然后,将所有的三元组组合起来,形成上下文
最后,将问题和上下文一起输入到qa_chain,得到最后的答案entities = get_entities(entity_string) # 获取实体列表。 context = "" # 初始化上下文。 all_triplets = [] # 初始化三元组列表。 for entity in entities: # 遍历每个实体 all_triplets.extend(self.graph.get_entity_knowledge(entity)) # 获取实体的所有知识并加入到三元组列表中。 context = "\n".join(all_triplets) # 用换行符连接所有的三元组作为上下文。 # 打印完整的上下文。 _run_manager.on_text("Full Context:", end="\n", verbose=self.verbose) _run_manager.on_text(context, color="green", end="\n", verbose=self.verbose) # 使用上下文和问题获取答案。 result = self.qa_chain( {"question": question, "context": context}, callbacks=_run_manager.get_child(), ) return {self.output_key: result[self.qa_chain.output_key]} # 返回答案 - 比如能自动生成代码并执行的:llm_math等等
- 比如面向私域数据的:qa_with_sources,其中的这份代码文件 chains/qa_with_sources/vector_db.py 则是使用向量数据库的问题回答,核心在于以下两个函数
reduce_tokens_below_limit_get_docs# 定义基于向量数据库的问题回答类 class VectorDBQAWithSourcesChain(BaseQAWithSourcesChain): """Question-answering with sources over a vector database.""" # 定义向量数据库的字段 vectorstore: VectorStore = Field(exclude=True) """Vector Database to connect to.""" # 定义返回结果的数量 k: int = 4 # 是否基于token限制来减少返回结果的数量 reduce_k_below_max_tokens: bool = False # 定义返回的文档基于token的最大限制 max_tokens_limit: int = 3375 # 定义额外的搜索参数 search_kwargs: Dict[str, Any] = Field(default_factory=dict) # 定义函数来根据最大token限制来减少文档 def _reduce_tokens_below_limit(self, docs: List[Document]) -> List[Document]: num_docs = len(docs) # 检查是否需要根据token减少文档数量 if self.reduce_k_below_max_tokens and isinstance( self.combine_documents_chain, StuffDocumentsChain ): tokens = [ self.combine_documents_chain.llm_chain.llm.get_num_tokens( doc.page_content ) for doc in docs ] token_count = sum(tokens[:num_docs]) # 减少文档数量直到满足token限制 while token_count > self.max_tokens_limit: num_docs -= 1 token_count -= tokens[num_docs] return docs[:num_docs]# 获取相关文档的函数 def _get_docs( self, inputs: Dict[str, Any], *, run_manager: CallbackManagerForChainRun ) -> List[Document]: question = inputs[self.question_key] # 从向量存储中搜索相似的文档 docs = self.vectorstore.similarity_search( question, k=self.k, **self.search_kwargs ) return self._reduce_tokens_below_limit(docs) - 比如面向SQL数据源的:sql_database,可以重点关注这份代码文件:chains/sql_database/query.py
- 比如面向模型对话的:chat_models,包括这些代码文件:__init__.py、anthropic.py、azure_openai.py、base.py、fake.py、google_palm.py、human.py、jinachat.py、openai.py、promptlayer_openai.py、vertexai.py
另外,还有比较让人眼前一亮的:
constitutional_ai:对最终结果进行偏见、合规问题处理的逻辑,保证最终的结果符合价值观
llm_checker:能让LLM自动检测自己的输出是否有没有问题的逻辑
1.2.2 Memory:记忆
简言之,用来保存和模型交互时的上下文状态,处理长期记忆
具体而言,这层主要有两个核心点:
对Chains的执行过程中的输入、输出进行记忆并结构化存储,为下一步的交互提供上下文,这部分简单存储在Redis即可
根据交互历史构建知识图谱,根据关联信息给出准确结果,对应的代码文件为:memory/kg.py
# 定义知识图谱对话记忆类
class ConversationKGMemory(BaseChatMemory):
"""知识图谱对话记忆类
在对话中与外部知识图谱集成,存储和检索对话中的知识三元组信息。
"""
k: int = 2 # 考虑的上下文对话数量
human_prefix: str = "Human" # 人类前缀
ai_prefix: str = "AI" # AI前缀
kg: NetworkxEntityGraph = Field(default_factory=NetworkxEntityGraph) # 知识图谱实例
knowledge_extraction_prompt: BasePromptTemplate = KNOWLEDGE_TRIPLE_EXTRACTION_PROMPT # 知识提取提示
entity_extraction_prompt: BasePromptTemplate = ENTITY_EXTRACTION_PROMPT # 实体提取提示
llm: BaseLanguageModel # 基础语言模型
summary_message_cls: Type[BaseMessage] = SystemMessage # 总结消息类
memory_key: str = "history" # 历史记忆键
def load_memory_variables(self, inputs: Dict[str, Any]) -> Dict[str, Any]:
"""返回历史缓冲区。"""
entities = self._get_current_entities(inputs) # 获取当前实体
summary_strings = []
for entity in entities: # 对于每个实体
knowledge = self.kg.get_entity_knowledge(entity) # 获取与实体相关的知识
if knowledge:
summary = f"On {entity}: {'. '.join(knowledge)}." # 构建总结字符串
summary_strings.append(summary)
context: Union[str, List]
if not summary_strings:
context = [] if self.return_messages else ""
elif self.return_messages:
context = [
self.summary_message_cls(content=text) for text in summary_strings
]
else:
context = "\n".join(summary_strings)
return {self.memory_key: context}
@property
def memory_variables(self) -> List[str]:
"""始终返回记忆变量列表。"""
return [self.memory_key]
def _get_prompt_input_key(self, inputs: Dict[str, Any]) -> str:
"""获取提示的输入键。"""
if self.input_key is None:
return get_prompt_input_key(inputs, self.memory_variables)
return self.input_key
def _get_prompt_output_key(self, outputs: Dict[str, Any]) -> str:
"""获取提示的输出键。"""
if self.output_key is None:
if len(outputs) != 1:
raise ValueError(f"One output key expected, got {outputs.keys()}")
return list(outputs.keys())[0]
return self.output_key
def get_current_entities(self, input_string: str) -> List[str]:
"""从输入字符串中获取当前实体。"""
chain = LLMChain(llm=self.llm, prompt=self.entity_extraction_prompt)
buffer_string = get_buffer_string(
self.chat_memory.messages[-self.k * 2 :],
human_prefix=self.human_prefix,
ai_prefix=self.ai_prefix,
)
output = chain.predict(
history=buffer_string,
input=input_string,
)
return get_entities(output)
def _get_current_entities(self, inputs: Dict[str, Any]) -> List[str]:
"""获取对话中的当前实体。"""
prompt_input_key = self._get_prompt_input_key(inputs)
return self.get_current_entities(inputs[prompt_input_key])
def get_knowledge_triplets(self, input_string: str) -> List[KnowledgeTriple]:
"""从输入字符串中获取知识三元组。"""
chain = LLMChain(llm=self.llm, prompt=self.knowledge_extraction_prompt)
buffer_string = get_buffer_string(
self.chat_memory.messages[-self.k * 2 :],
human_prefix=self.human_prefix,
ai_prefix=self.ai_prefix,
)
output = chain.predict(
history=buffer_string,
input=input_string,
verbose=True,
)
knowledge = parse_triples(output) # 解析三元组
return knowledge
def _get_and_update_kg(self, inputs: Dict[str, Any]) -> None:
"""从对话历史中获取并更新知识图谱。"""
prompt_input_key = self._get_prompt_input_key(inputs)
knowledge = self.get_knowledge_triplets(inputs[prompt_input_key])
for triple in knowledge:
self.kg.add_triple(triple) # 向知识图谱中添加三元组
def save_context(self, inputs: Dict[str, Any], outputs: Dict[str, str]) -> None:
"""将此对话的上下文保存到缓冲区。"""
super().save_context(inputs, outputs)
self._get_and_update_kg(inputs)
def clear(self) -> None:
"""清除记忆内容。"""
super().clear()
self.kg.clear() # 清除知识图谱内容1.2.3 Tools层,工具
其实Chains层可以根据LLM + Prompt执行一些特定的逻辑,但是如果要用Chain实现所有的逻辑不现实,可以通过Tools层也可以实现,Tools层理解为技能比较合理,典型的比如搜索、Wikipedia、天气预报、ChatGPT服务等等
1.3 应用层:Agents
1.3.1 Agents:代理
简言之,有了基础层和能力层,我们可以构建各种各样好玩的,有价值的服务,这里就是Agent
具体而言,Agent 作为代理人去向 LLM 发出请求,然后采取行动,且检查结果直到工作完成,包括LLM无法处理的任务的代理 (例如搜索或计算,类似ChatGPT plus的插件有调用bing和计算器的功能)
比如,Agent 可以使用维基百科查找 Barack Obama 的出生日期,然后使用计算器计算他在 2023 年的年龄
# pip install wikipedia
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.agents import AgentType
tools = load_tools(["wikipedia", "llm-math"], llm=llm)
agent = initialize_agent(tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True)
agent.run("奥巴马的生日是哪天? 到2023年他多少岁了?")此外,关于Wikipedia可以关注下这个代码文件:langchain/docstore/wikipedia.py ...
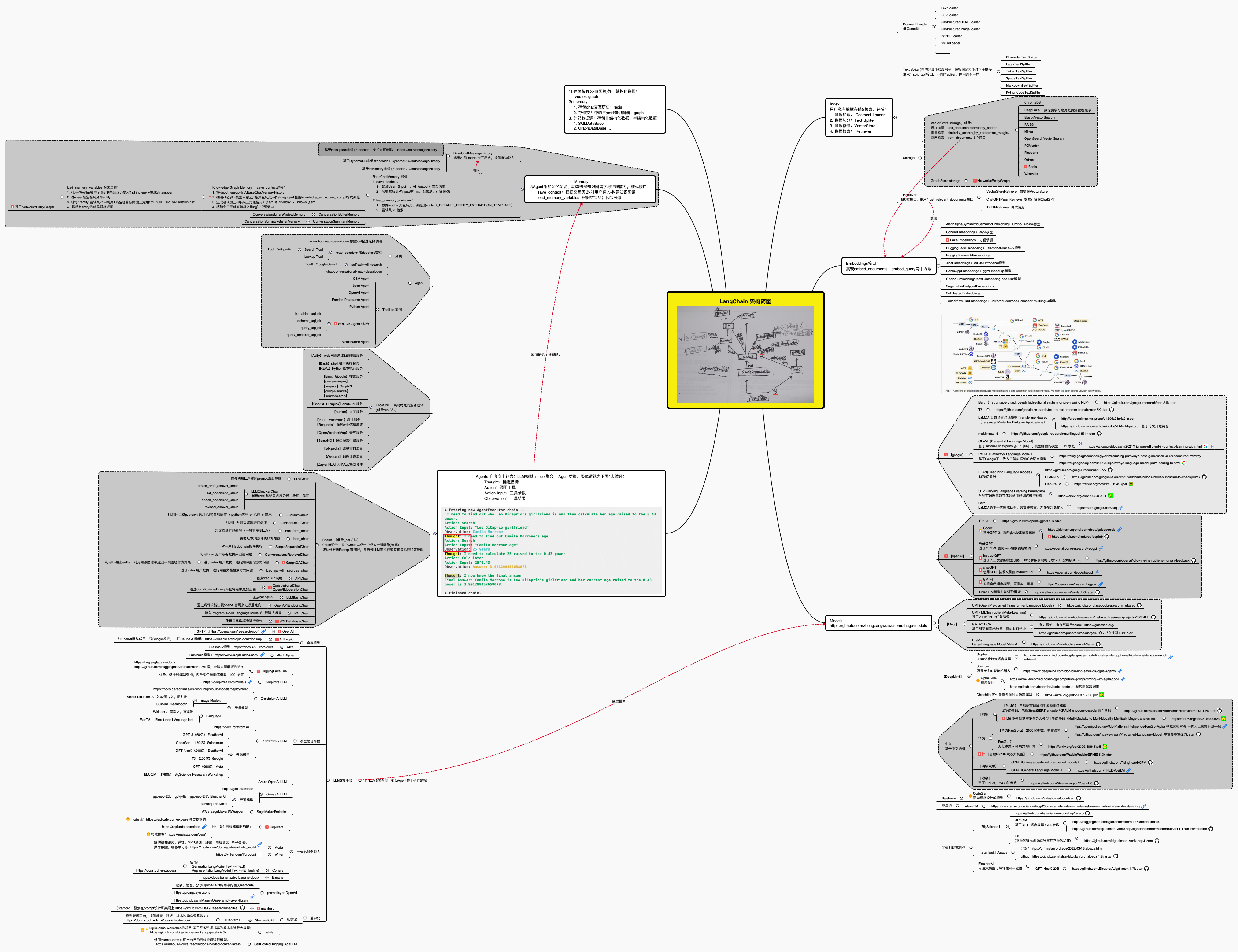
最终langchain的整体技术架构可以如下图所示 (查看高清大图,此外,这里还有另一个架构图)
第二部分 基于LangChain + ChatGLM-6B(23年7月初版)的本地知识库问答
2.1 核心步骤:如何通过LangChain+LLM实现本地知识库问答
2023年7月,GitHub上有一个利用 langchain 思想实现的基于本地知识库的问答应用:langchain-ChatGLM (这是其GitHub地址,当然还有和它类似的但现已支持Vicuna-13b的项目,比如LangChain-ChatGLM-Webui ),目标期望建立一套对中文场景与开源模型支持友好、可离线运行的知识库问答解决方案
- 该项目受 GanymedeNil 的项目 document.ai,和 AlexZhangji 创建的 ChatGLM-6B Pull Request 启发,建立了全流程可使用开源模型实现的本地知识库问答应用。现已支持使用 ChatGLM-6B、 ClueAI/ChatYuan-large-v2 等大语言模型的接入
- 该项目中 Embedding 默认选用的是 GanymedeNil/text2vec-large-chinese,LLM 默认选用的是 ChatGLM-6B,依托上述模型,本项目可实现全部使用开源模型离线私有部署
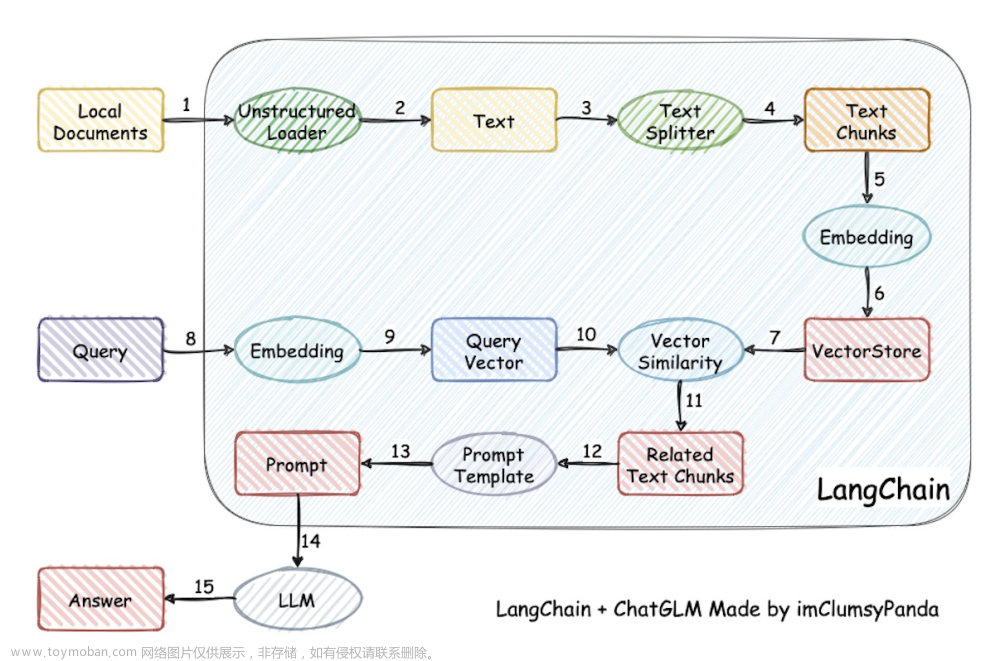
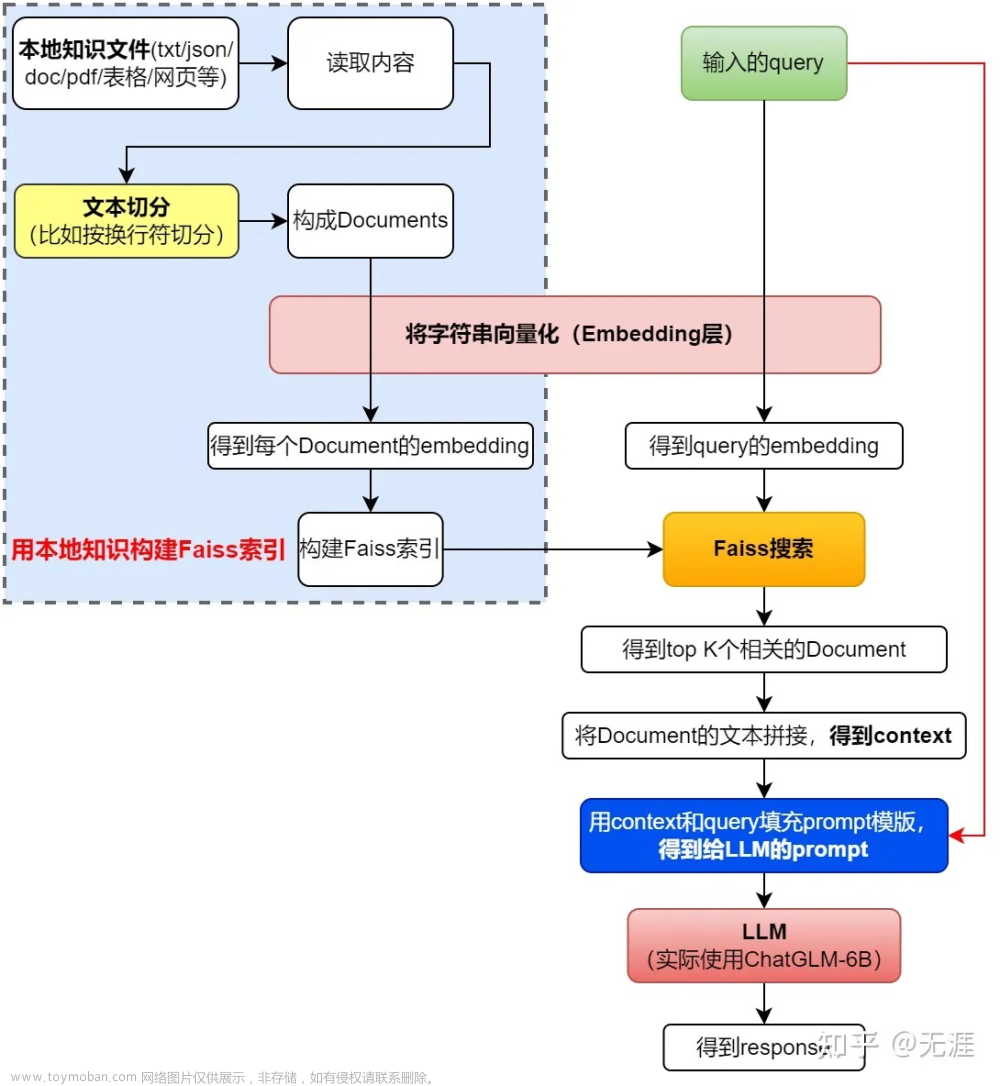
本项目实现原理如下图所示 (与基于文档的问答 大同小异,过程包括:1 加载文档 -> 2 读取文档 -> 3/4文档分割 -> 5/6 文本向量化 -> 8/9 问句向量化 -> 10 在文档向量中匹配出与问句向量最相似的top k个 -> 11/12/13 匹配出的文本作为上下文和问题一起添加到prompt中 -> 14/15提交给LLM生成回答 )
-
第一阶段:加载文件-读取文件-文本分割(Text splitter)
加载文件:这是读取存储在本地的知识库文件的步骤
读取文件:读取加载的文件内容,通常是将其转化为文本格式
文本分割(Text splitter):按照一定的规则(例如段落、句子、词语等)将文本分割 -
第二阶段:文本向量化(embedding)-存储到向量数据库
文本向量化(embedding):这通常涉及到NLP的特征抽取,可以通过诸如TF-IDF、word2vec、BERT等方法将分割好的文本转化为数值向量
存储到向量数据库:文本向量化之后存储到数据库vectorstore (FAISS,下一节会详解FAISS)def init_vector_store(self): persist_dir = os.path.join(VECTORE_PATH, ".vectordb") # 持久化向量数据库的地址 print("向量数据库持久化地址: ", persist_dir) # 打印持久化地址 # 如果持久化地址存在 if os.path.exists(persist_dir): # 从本地持久化文件中加载 print("从本地向量加载数据...") # 使用 Chroma 加载持久化的向量数据 vector_store = Chroma(persist_directory=persist_dir, embedding_function=self.embeddings) # 如果持久化地址不存在 else: # 加载知识库 documents = self.load_knownlege() # 使用 Chroma 从文档中创建向量存储 vector_store = Chroma.from_documents(documents=documents, embedding=self.embeddings, persist_directory=persist_dir) vector_store.persist() # 持久化向量存储 return vector_store # 返回向量存储其中load_knownlege的实现为
def load_knownlege(self): docments = [] # 初始化一个空列表来存储文档 # 遍历 DATASETS_DIR 目录下的所有文件 for root, _, files in os.walk(DATASETS_DIR, topdown=False): for file in files: filename = os.path.join(root, file) # 获取文件的完整路径 docs = self._load_file(filename) # 加载文件中的文档 # 更新 metadata 数据 new_docs = [] # 初始化一个空列表来存储新文档 for doc in docs: # 更新文档的 metadata,将 "source" 字段的值替换为不包含 DATASETS_DIR 的相对路径 doc.metadata = {"source": doc.metadata["source"].replace(DATASETS_DIR, "")} print("文档2向量初始化中, 请稍等...", doc.metadata) # 打印正在初始化的文档的 metadata new_docs.append(doc) # 将文档添加到新文档列表 docments += new_docs # 将新文档列表添加到总文档列表 return docments # 返回所有文档的列表 -
第三阶段:问句向量化
这是将用户的查询或问题转化为向量,应使用与文本向量化相同的方法,以便在相同的空间中进行比较 -
第四阶段:在文本向量中匹配出与问句向量最相似的top k个
这一步是信息检索的核心,通过计算余弦相似度、欧氏距离等方式,找出与问句向量最接近的文本向量def query(self, q): """在向量数据库中查找与问句向量相似的文本向量""" vector_store = self.init_vector_store() docs = vector_store.similarity_search_with_score(q, k=self.top_k) for doc in docs: dc, s = doc yield s, dc -
第五阶段:匹配出的文本作为上下文和问题一起添加到prompt中
这是利用匹配出的文本来形成与问题相关的上下文,用于输入给语言模型 -
第六阶段:提交给LLM生成回答
最后,将这个问题和上下文一起提交给语言模型(例如GPT系列),让它生成回答
比如知识查询(代码来源)class KnownLedgeBaseQA: # 初始化 def __init__(self) -> None: k2v = KnownLedge2Vector() # 创建一个知识到向量的转换器 self.vector_store = k2v.init_vector_store() # 初始化向量存储 self.llm = VicunaLLM() # 创建一个 VicunaLLM 对象 # 获得与查询相似的答案 def get_similar_answer(self, query): # 创建一个提示模板 prompt = PromptTemplate( template=conv_qa_prompt_template, input_variables=["context", "question"] # 输入变量包括 "context"(上下文) 和 "question"(问题) ) # 使用向量存储来检索文档 retriever = self.vector_store.as_retriever(search_kwargs={"k": VECTOR_SEARCH_TOP_K}) docs = retriever.get_relevant_documents(query=query) # 获取与查询相关的文本 context = [d.page_content for d in docs] # 从文本中提取出内容 result = prompt.format(context="\n".join(context), question=query) # 格式化模板,并用从文本中提取出的内容和问题填充 return result # 返回结果
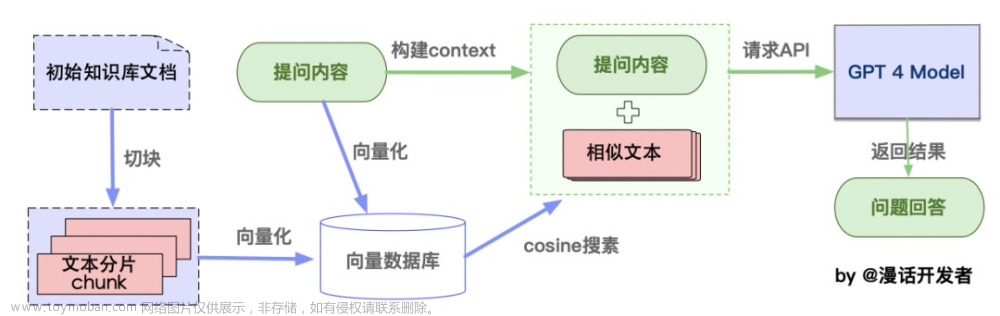
如你所见,这种通过组合langchain+LLM的方式,特别适合一些垂直领域或大型集团企业搭建通过LLM的智能对话能力搭建企业内部的私有问答系统,也适合个人专门针对一些英文paper进行问答,比如比较火的一个开源项目:ChatPDF,其从文档处理角度来看,实现流程如下(图源):
2.2 Facebook AI Similarity Search(FAISS):高效向量相似度检索
Faiss的全称是Facebook AI Similarity Search (官方介绍页、GitHub地址),是FaceBook的AI团队针对大规模相似度检索问题开发的一个工具,使用C++编写,有python接口,对10亿量级的索引可以做到毫秒级检索的性能
简单来说,Faiss的工作,就是把我们自己的候选向量集封装成一个index数据库,它可以加速我们检索相似向量TopK的过程,其中有些索引还支持GPU构建
2.2.1 Faiss检索相似向量TopK的基本流程
Faiss检索相似向量TopK的工程基本都能分为三步:
- 得到向量库
import numpy as np d = 64 # 向量维度 nb = 100000 # index向量库的数据量 nq = 10000 # 待检索query的数目 np.random.seed(1234) xb = np.random.random((nb, d)).astype('float32') xb[:, 0] += np.arange(nb) / 1000. # index向量库的向量 xq = np.random.random((nq, d)).astype('float32') xq[:, 0] += np.arange(nq) / 1000. # 待检索的query向量 - 用faiss 构建index,并将向量添加到index中
其中的构建索引选用暴力检索的方法FlatL2,L2代表构建的index采用的相似度度量方法为L2范数,即欧氏距离import faiss index = faiss.IndexFlatL2(d) print(index.is_trained) # 输出为True,代表该类index不需要训练,只需要add向量进去即可 index.add(xb) # 将向量库中的向量加入到index中 print(index.ntotal) # 输出index中包含的向量总数,为100000 - 用faiss index 检索,检索出TopK的相似query
k = 4 # topK的K值 D, I = index.search(xq, k)# xq为待检索向量,返回的I为每个待检索query最相似TopK的索引list,D为其对应的距离 print(I[:5]) print(D[-5:])打印输出为:
>>>
[[ 0 393 363 78]
[ 1 555 277 364]
[ 2 304 101 13]
[ 3 173 18 182]
[ 4 288 370 531]]
[[ 0. 7.17517328 7.2076292 7.25116253]
[ 0. 6.32356453 6.6845808 6.79994535]
[ 0. 5.79640865 6.39173603 7.28151226]
[ 0. 7.27790546 7.52798653 7.66284657]
[ 0. 6.76380348 7.29512024 7.36881447]]
2.2.2 FAISS构建索引的多种方式
构建index方法和传参方法可以为
dim, measure = 64, faiss.METRIC_L2
param = 'Flat'
index = faiss.index_factory(dim, param, measure)- dim为向量维数
- 最重要的是param参数,它是传入index的参数,代表需要构建什么类型的索引;
- measure为度量方法,目前支持两种,欧氏距离和inner product,即内积。因此,要计算余弦相似度,只需要将vecs归一化后,使用内积度量即可
此文,现在faiss官方支持八种度量方式,分别是:
- METRIC_INNER_PRODUCT(内积)
- METRIC_L1(曼哈顿距离)
- METRIC_L2(欧氏距离)
- METRIC_Linf(无穷范数)
- METRIC_Lp(p范数)
- METRIC_BrayCurtis(BC相异度)
- METRIC_Canberra(兰氏距离/堪培拉距离)
- METRIC_JensenShannon(JS散度)
2.2.2.1 Flat :暴力检索
- 优点:该方法是Faiss所有index中最准确的,召回率最高的方法,没有之一;
- 缺点:速度慢,占内存大。
- 使用情况:向量候选集很少,在50万以内,并且内存不紧张。
- 注:虽然都是暴力检索,faiss的暴力检索速度比一般程序猿自己写的暴力检索要快上不少,所以并不代表其无用武之地,建议有暴力检索需求的同学还是用下faiss。
- 构建方法:
dim, measure = 64, faiss.METRIC_L2
param = 'Flat'
index = faiss.index_factory(dim, param, measure)
index.is_trained # 输出为True
index.add(xb) # 向index中添加向量2.2.2.2 IVFx Flat :倒排暴力检索
- 优点:IVF主要利用倒排的思想,在文档检索场景下的倒排技术是指,一个kw后面挂上很多个包含该词的doc,由于kw数量远远小于doc,因此会大大减少了检索的时间。在向量中如何使用倒排呢?可以拿出每个聚类中心下的向量ID,每个中心ID后面挂上一堆非中心向量,每次查询向量的时候找到最近的几个中心ID,分别搜索这几个中心下的非中心向量。通过减小搜索范围,提升搜索效率。
- 缺点:速度也还不是很快。
- 使用情况:相比Flat会大大增加检索的速度,建议百万级别向量可以使用。
- 参数:IVFx中的x是k-means聚类中心的个数
- 构建方法:
dim, measure = 64, faiss.METRIC_L2
param = 'IVF100,Flat' # 代表k-means聚类中心为100,
index = faiss.index_factory(dim, param, measure)
print(index.is_trained) # 此时输出为False,因为倒排索引需要训练k-means,
index.train(xb) # 因此需要先训练index,再add向量
index.add(xb) 2.2.2.3 PQx :乘积量化
- 优点:利用乘积量化的方法,改进了普通检索,将一个向量的维度切成x段,每段分别进行检索,每段向量的检索结果取交集后得出最后的TopK。因此速度很快,而且占用内存较小,召回率也相对较高。
- 缺点:召回率相较于暴力检索,下降较多。
- 使用情况:内存及其稀缺,并且需要较快的检索速度,不那么在意召回率
- 参数:PQx中的x为将向量切分的段数,因此,x需要能被向量维度整除,且x越大,切分越细致,时间复杂度越高
- 构建方法:
dim, measure = 64, faiss.METRIC_L2
param = 'PQ16'
index = faiss.index_factory(dim, param, measure)
print(index.is_trained) # 此时输出为False,因为倒排索引需要训练k-means,
index.train(xb) # 因此需要先训练index,再add向量
index.add(xb) 2.2.2.4 IVFxPQy 倒排乘积量化
- 优点:工业界大量使用此方法,各项指标都均可以接受,利用乘积量化的方法,改进了IVF的k-means,将一个向量的维度切成x段,每段分别进行k-means再检索。
- 缺点:集百家之长,自然也集百家之短
- 使用情况:一般来说,各方面没啥特殊的极端要求的话,最推荐使用该方法!
- 参数:IVFx,PQy,其中的x和y同上
- 构建方法:
dim, measure = 64, faiss.METRIC_L2
param = 'IVF100,PQ16'
index = faiss.index_factory(dim, param, measure)
print(index.is_trained) # 此时输出为False,因为倒排索引需要训练k-means,
index.train(xb) # 因此需要先训练index,再add向量 index.add(xb) 2.2.2.5 LSH 局部敏感哈希
- 原理:哈希对大家再熟悉不过,向量也可以采用哈希来加速查找,我们这里说的哈希指的是局部敏感哈希(Locality Sensitive Hashing,LSH),不同于传统哈希尽量不产生碰撞,局部敏感哈希依赖碰撞来查找近邻。高维空间的两点若距离很近,那么设计一种哈希函数对这两点进行哈希计算后分桶,使得他们哈希分桶值有很大的概率是一样的,若两点之间的距离较远,则他们哈希分桶值相同的概率会很小。
- 优点:训练非常快,支持分批导入,index占内存很小,检索也比较快
- 缺点:召回率非常拉垮。
- 使用情况:候选向量库非常大,离线检索,内存资源比较稀缺的情况
- 构建方法:
dim, measure = 64, faiss.METRIC_L2
param = 'LSH'
index = faiss.index_factory(dim, param, measure)
print(index.is_trained) # 此时输出为True
index.add(xb) 2.2.2.6 HNSWx
- 优点:该方法为基于图检索的改进方法,检索速度极快,10亿级别秒出检索结果,而且召回率几乎可以媲美Flat,最高能达到惊人的97%。检索的时间复杂度为loglogn,几乎可以无视候选向量的量级了。并且支持分批导入,极其适合线上任务,毫秒级别体验。
- 缺点:构建索引极慢,占用内存极大(是Faiss中最大的,大于原向量占用的内存大小)
- 参数:HNSWx中的x为构建图时每个点最多连接多少个节点,x越大,构图越复杂,查询越精确,当然构建index时间也就越慢,x取4~64中的任何一个整数。
- 使用情况:不在乎内存,并且有充裕的时间来构建index
- 构建方法:
dim, measure = 64, faiss.METRIC_L2
param = 'HNSW64'
index = faiss.index_factory(dim, param, measure)
print(index.is_trained) # 此时输出为True
index.add(xb)2.3 项目部署:langchain + ChatGLM-6B搭建本地知识库问答
2.3.1 部署过程一:支持多种使用模式
其中的LLM模型可以根据实际业务的需求选定,本项目中用的ChatGLM-6B,其GitHub地址为:https://github.com/THUDM/ChatGLM-6B
ChatGLM-6B 是⼀个开源的、⽀持中英双语的对话语⾔模型,基于 General LanguageModel (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)
ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答
- 新建一个python3.8.13的环境(模型文件还是可以用的)
conda create -n langchain python==3.8.13 - 拉取项目
git clone https://github.com/imClumsyPanda/langchain-ChatGLM.git - 进入目录
cd langchain-ChatGLM - 安装requirements.txt
conda activate langchain pip install -r requirements.txt - 当前环境支持装langchain的最高版本是0.0.166,无法安装0.0.174,就先装下0.0.166试下
修改配置文件路径:vi configs/model_config.py - 将chatglm-6b的路径设置成自己的
“chatglm-6b”: { “name”: “chatglm-6b”, “pretrained_model_name”: “/data/sim_chatgpt/chatglm-6b”, “local_model_path”: None, “provides”: “ChatGLM” - 修改要运行的代码文件:webui.py
vi webui.py - 将最后launch函数中的share设置为True,inbrowser设置为True
- 执行webui.py文件
可能是网络问题,无法创建一个公用链接。可以进行云服务器和本地端口的映射,参考:https://www.cnblogs.com/monologuesmw/p/14465117.html
python webui.py
对应输出:
占用显存情况:大约15个G
2.3.2 部署过程二:支持多种社区上的在线体验
项目地址:https://github.com/thomas-yanxin/LangChain-ChatGLM-Webui
HUggingFace社区在线体验:https://huggingface.co/spaces/thomas-yanxin/LangChain-ChatLLM
另外也支持ModelScope魔搭社区、飞桨AIStudio社区等在线体验
- 下载项目
git clone https://github.com/thomas-yanxin/LangChain-ChatGLM-Webui.git - 进入目录
cd LangChain-ChatGLM-Webui - 安装所需的包
pip install -r requirements.txt pip install gradio==3.10 - 修改config.py
init_llm = "ChatGLM-6B" llm_model_dict = { "chatglm": { "ChatGLM-6B": "/data/sim_chatgpt/chatglm-6b", - 修改app.py文件,将launch函数中的share设置为True,inbrowser设置为True
执行webui.py文件python webui.py
显存占用约13G
第三部分 逐行深入分析:langchain-ChatGLM(23年7月初版)项目的源码解读
再回顾一遍langchain-ChatGLM这个项目的架构图(图源)
你会发现该项目主要由以下各大模块组成(注意,该项目的最新版已经变化很大,本第三部分可以认为是针对v0.1.14左右的版本,往上最多到v0.1.16,新版对很多功能做了更高的封装,而从原理理解的角度来说,看老版 更好理解些)
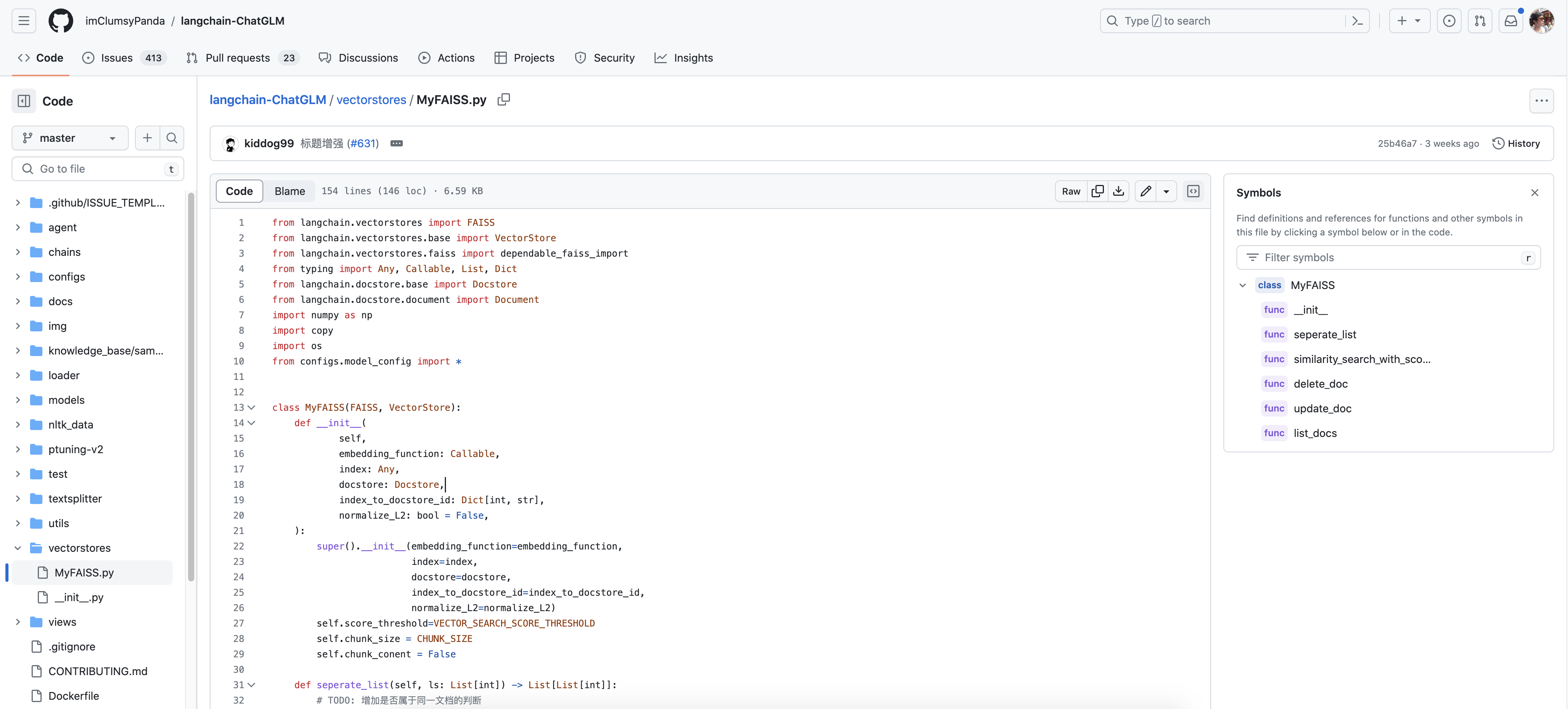
- chains: 工作链路实现,如 chains/local_doc_qa 实现了基于本地⽂档的问答实现
- configs:配置文件存储
- knowledge_base/content:用于存储上传的原始⽂件
- loader: 文档加载器的实现类
- models: llm的接⼝类与实现类,针对开源模型提供流式输出⽀持
- textsplitter: 文本切分的实现类
- vectorstores:用于存储向量库⽂件,即本地知识库本体
- ..
接下来,为方便读者一目了然,更快理解
- 我基本给“下面该项目中的每一行代码”都添加上了中文注释
- 且为理解更顺畅,我解读各个代码文件夹的顺序是根据项目流程逐一展开的 (而非上图GitHub上各个代码文件夹的呈现顺序)
如有问题,可以随时留言评论
3.1 agent:custom_agent/bing_search
3.1.1 agent/custom_agent.py
from langchain.agents import Tool # 导入工具模块
from langchain.tools import BaseTool # 导入基础工具类
from langchain import PromptTemplate, LLMChain # 导入提示模板和语言模型链
from agent.custom_search import DeepSearch # 导入自定义搜索模块
# 导入基础单动作代理,输出解析器,语言模型单动作代理和代理执行器
from langchain.agents import BaseSingleActionAgent, AgentOutputParser, LLMSingleActionAgent, AgentExecutor
from typing import List, Tuple, Any, Union, Optional, Type # 导入类型注释模块
from langchain.schema import AgentAction, AgentFinish # 导入代理动作和代理完成模式
from langchain.prompts import StringPromptTemplate # 导入字符串提示模板
from langchain.callbacks.manager import CallbackManagerForToolRun # 导入工具运行回调管理器
from langchain.base_language import BaseLanguageModel # 导入基础语言模型
import re # 导入正则表达式模块
# 定义一个代理模板字符串
agent_template = """
你现在是一个{role}。这里是一些已知信息:
{related_content}
{background_infomation}
{question_guide}:{input}
{answer_format}
"""
# 定义一个自定义提示模板类,继承自字符串提示模板
class CustomPromptTemplate(StringPromptTemplate):
template: str # 提示模板字符串
tools: List[Tool] # 工具列表
# 定义一个格式化函数,根据提供的参数生成最终的提示模板
def format(self, **kwargs) -> str:
intermediate_steps = kwargs.pop("intermediate_steps")
# 判断是否有互联网查询信息
if len(intermediate_steps) == 0:
# 如果没有,则给出默认的背景信息,角色,问题指导和回答格式
background_infomation = "\n"
role = "傻瓜机器人"
question_guide = "我现在有一个问题"
answer_format = "如果你知道答案,请直接给出你的回答!如果你不知道答案,请你只回答\"DeepSearch('搜索词')\",并将'搜索词'替换为你认为需要搜索的关键词,除此之外不要回答其他任何内容。\n\n下面请回答我上面提出的问题!"
else:
# 否则,根据 intermediate_steps 中的 AgentAction 拼装 background_infomation
background_infomation = "\n\n你还有这些已知信息作为参考:\n\n"
action, observation = intermediate_steps[0]
background_infomation += f"{observation}\n"
role = "聪明的 AI 助手"
question_guide = "请根据这些已知信息回答我的问题"
answer_format = ""
kwargs["background_infomation"] = background_infomation
kwargs["role"] = role
kwargs["question_guide"] = question_guide
kwargs["answer_format"] = answer_format
return self.template.format(**kwargs) # 格式化模板并返回
# 定义一个自定义搜索工具类,继承自基础工具类
class CustomSearchTool(BaseTool):
name: str = "DeepSearch" # 工具名称
description: str = "" # 工具描述
# 定义一个运行函数,接受一个查询字符串和一个可选的回调管理器作为参数,返回DeepSearch的搜索结果
def _run(self, query: str, run_manager: Optional[CallbackManagerForToolRun] = None):
return DeepSearch.search(query = query)
# 定义一个异步运行函数,但由于DeepSearch不支持异步,所以直接抛出一个未实现错误
async def _arun(self, query: str):
raise NotImplementedError("DeepSearch does not support async")
# 定义一个自定义代理类,继承自基础单动作代理
class CustomAgent(BaseSingleActionAgent):
# 定义一个输入键的属性
@property
def input_keys(self):
return ["input"]
# 定义一个计划函数,接受一组中间步骤和其他参数,返回一个代理动作或者代理完成
def plan(self, intermedate_steps: List[Tuple[AgentAction, str]],
**kwargs: Any) -> Union[AgentAction, AgentFinish]:
return AgentAction(tool="DeepSearch", tool_input=kwargs["input"], log="")
# 定义一个自定义输出解析器,继承自代理输出解析器
class CustomOutputParser(AgentOutputParser):
# 定义一个解析函数,接受一个语言模型的输出字符串,返回一个代理动作或者代理完成
def parse(self, llm_output: str) -> Union[AgentAction, AgentFinish]:
# 使用正则表达式匹配输出字符串,group1是调用函数名字,group2是传入参数
match = re.match(r'^[\s\w]*(DeepSearch)\(([^\)]+)\)', llm_output, re.DOTALL)
print(match)
# 如果语言模型没有返回 DeepSearch() 则认为直接结束指令
if not match:
return AgentFinish(
return_values={"output": llm_output.strip()},
log=llm_output,
)
# 否则的话都认为需要调用 Tool
else:
action = match.group(1).strip()
action_input = match.group(2).strip()
return AgentAction(tool=action, tool_input=action_input.strip(" ").strip('"'), log=llm_output)
# 定义一个深度代理类
class DeepAgent:
tool_name: str = "DeepSearch" # 工具名称
agent_executor: any # 代理执行器
tools: List[Tool] # 工具列表
llm_chain: any # 语言模型链
# 定义一个查询函数,接受一个相关内容字符串和一个查询字符串,返回执行器的运行结果
def query(self, related_content: str = "", query: str = ""):
tool_name =这段代码的主要目的是建立一个深度搜索的AI代理。AI代理首先通过接收一个问题输入,然后根据输入生成一个提示模板,然后通过该模板引导AI生成回答或进行更深入的搜索。现在,我将继续为剩余的代码添加中文注释
```python
self.tool_name
result = self.agent_executor.run(related_content=related_content, input=query ,tool_name=self.tool_name)
return result # 返回执行器的运行结果
# 在初始化函数中,首先从DeepSearch工具创建一个工具实例,并添加到工具列表中
def __init__(self, llm: BaseLanguageModel, **kwargs):
tools = [
Tool.from_function(
func=DeepSearch.search,
name="DeepSearch",
description=""
)
]
self.tools = tools # 保存工具列表
tool_names = [tool.name for tool in tools] # 提取工具列表中的工具名称
output_parser = CustomOutputParser() # 创建一个自定义输出解析器实例
# 创建一个自定义提示模板实例
prompt = CustomPromptTemplate(template=agent_template,
tools=tools,
input_variables=["related_content","tool_name", "input", "intermediate_steps"])
# 创建一个语言模型链实例
llm_chain = LLMChain(llm=llm, prompt=prompt)
self.llm_chain = llm_chain # 保存语言模型链实例
# 创建一个语言模型单动作代理实例
agent = LLMSingleActionAgent(
llm_chain=llm_chain,
output_parser=output_parser,
stop=["\nObservation:"],
allowed_tools=tool_names
)
# 创建一个代理执行器实例
agent_executor = AgentExecutor.from_agent_and_tools(agent=agent, tools=tools, verbose=True)
self.agent_executor = agent_executor # 保存代理执行器实例3.1.2 agent/bing_search.py
#coding=utf8
# 声明文件编码格式为 utf8
from langchain.utilities import BingSearchAPIWrapper
# 导入 BingSearchAPIWrapper 类,这个类用于与 Bing 搜索 API 进行交互
from configs.model_config import BING_SEARCH_URL, BING_SUBSCRIPTION_KEY
# 导入配置文件中的 Bing 搜索 URL 和 Bing 订阅密钥
def bing_search(text, result_len=3):
# 定义一个名为 bing_search 的函数,该函数接收一个文本和结果长度的参数,默认结果长度为3
if not (BING_SEARCH_URL and BING_SUBSCRIPTION_KEY):
# 如果 Bing 搜索 URL 或 Bing 订阅密钥未设置,则返回一个错误信息的文档
return [{"snippet": "please set BING_SUBSCRIPTION_KEY and BING_SEARCH_URL in os ENV",
"title": "env inof not fould",
"link": "https://python.langchain.com/en/latest/modules/agents/tools/examples/bing_search.html"}]
search = BingSearchAPIWrapper(bing_subscription_key=BING_SUBSCRIPTION_KEY,
bing_search_url=BING_SEARCH_URL)
# 创建 BingSearchAPIWrapper 类的实例,该实例用于与 Bing 搜索 API 进行交互
return search.results(text, result_len)
# 返回搜索结果,结果的数量由 result_len 参数决定
if __name__ == "__main__":
# 如果这个文件被直接运行,而不是被导入作为模块,那么就执行以下代码
r = bing_search('python')
# 使用 Bing 搜索 API 来搜索 "python" 这个词,并将结果保存在变量 r 中
print(r)
# 打印出搜索结果3.2 models:包含models和文档加载器loader
- models: llm的接⼝类与实现类,针对开源模型提供流式输出⽀持
- loader: 文档加载器的实现类
3.2.1 models/chatglm_llm.py
from abc import ABC # 导入抽象基类
from langchain.llms.base import LLM # 导入语言学习模型基类
from typing import Optional, List # 导入类型标注模块
from models.loader import LoaderCheckPoint # 导入模型加载点
from models.base import (BaseAnswer, # 导入基本回答模型
AnswerResult) # 导入回答结果模型
class ChatGLM(BaseAnswer, LLM, ABC): # 定义ChatGLM类,继承基础回答、语言学习模型和抽象基类
max_token: int = 10000 # 最大的token数
temperature: float = 0.01 # 温度参数,用于控制生成文本的随机性
top_p = 0.9 # 排序前0.9的token会被保留
checkPoint: LoaderCheckPoint = None # 检查点模型
# history = [] # 历史记录
history_len: int = 10 # 历史记录长度
def __init__(self, checkPoint: LoaderCheckPoint = None): # 初始化方法
super().__init__() # 调用父类的初始化方法
self.checkPoint = checkPoint # 赋值检查点模型
@property
def _llm_type(self) -> str: # 定义只读属性_llm_type,返回语言学习模型的类型
return "ChatGLM"
@property
def _check_point(self) -> LoaderCheckPoint: # 定义只读属性_check_point,返回检查点模型
return self.checkPoint
@property
def _history_len(self) -> int: # 定义只读属性_history_len,返回历史记录的长度
return self.history_len
def set_history_len(self, history_len: int = 10) -> None: # 设置历史记录长度
self.history_len = history_len
def _call(self, prompt: str, stop: Optional[List[str]] = None) -> str: # 定义_call方法,实现模型的具体调用
print(f"__call:{prompt}") # 打印调用的提示信息
response, _ = self.checkPoint.model.chat( # 调用模型的chat方法,获取回答和其他信息
self.checkPoint.tokenizer, # 使用的分词器
prompt, # 提示信息
history=[], # 历史记录
max_length=self.max_token, # 最大长度
temperature=self.temperature # 温度参数
)
print(f"response:{response}") # 打印回答信息
print(f"+++++++++++++++++++++++++++++++++++") # 打印分隔线
return response # 返回回答
def generatorAnswer(self, prompt: str,
history: List[List[str]] = [],
streaming: bool = False): # 定义生成回答的方法,可以处理流式输入
if streaming: # 如果是流式输入
history += [[]] # 在历史记录中添加新的空列表
for inum, (stream_resp, _) in enumerate(self.checkPoint.model.stream_chat( # 对模型的stream_chat方法返回的结果进行枚举
self.checkPoint.tokenizer, # 使用的分词器
prompt, # 提示信息
history=history[-self.history_len:-1] if self.history_len > 1 else [], # 使用的历史记录
max_length=self.max_token, # 最大长度
temperature=self.temperature # 温度参数
)):
# self.checkPoint.clear_torch_cache() # 清空缓存
history[-1] = [prompt, stream_resp] # 更新最后一个历史记录
answer_result = AnswerResult() # 创建回答结果对象
answer_result.history = history # 更新回答结果的历史记录
answer_result.llm_output = {"answer": stream_resp} # 更新回答结果的输出
yield answer_result # 生成回答结果
else: # 如果不是流式输入
response, _ = self.checkPoint.model.chat( # 调用模型的chat方法,获取回答和其他信息
self.checkPoint.tokenizer, # 使用的分词器
prompt, # 提示信息
history=history[-self.history_len:] if self.history_len > 0 else [], # 使用的历史记录
max_length=self.max_token, # 最大长度
temperature=self.temperature # 温度参数
)
self.checkPoint.clear_torch_cache() # 清空缓存
history += [[prompt, response]] # 更新历史记录
answer_result = AnswerResult() # 创建回答结果对象
answer_result.history = history # 更新回答结果的历史记录
answer_result.llm_output = {"answer": response} # 更新回答结果的输出
yield answer_result # 生成回答结果3.2.2 models/shared.py
这个文件的作用是远程调用LLM
import sys # 导入sys模块,通常用于与Python解释器进行交互
from typing import Any # 从typing模块导入Any,用于表示任何类型
# 从models.loader.args模块导入parser,可能是解析命令行参数用
from models.loader.args import parser
# 从models.loader模块导入LoaderCheckPoint,可能是模型加载点
from models.loader import LoaderCheckPoint
# 从configs.model_config模块导入llm_model_dict和LLM_MODEL
from configs.model_config import (llm_model_dict, LLM_MODEL)
# 从models.base模块导入BaseAnswer,即模型的基础类
from models.base import BaseAnswer
# 定义一个名为loaderCheckPoint的变量,类型为LoaderCheckPoint,并初始化为None
loaderCheckPoint: LoaderCheckPoint = None
def loaderLLM(llm_model: str = None, no_remote_model: bool = False, use_ptuning_v2: bool = False) -> Any:
"""
初始化 llm_model_ins LLM
:param llm_model: 模型名称
:param no_remote_model: 是否使用远程模型,如果需要加载本地模型,则添加 `--no-remote-model
:param use_ptuning_v2: 是否使用 p-tuning-v2 PrefixEncoder
:return:
"""
pre_model_name = loaderCheckPoint.model_name # 获取loaderCheckPoint的模型名称
llm_model_info = llm_model_dict[pre_model_name] # 从模型字典中获取模型信息
if no_remote_model: # 如果不使用远程模型
loaderCheckPoint.no_remote_model = no_remote_model # 将loaderCheckPoint的no_remote_model设置为True
if use_ptuning_v2: # 如果使用p-tuning-v2
loaderCheckPoint.use_ptuning_v2 = use_ptuning_v2 # 将loaderCheckPoint的use_ptuning_v2设置为True
if llm_model: # 如果指定了模型名称
llm_model_info = llm_model_dict[llm_model] # 从模型字典中获取指定的模型信息
if loaderCheckPoint.no_remote_model: # 如果不使用远程模型
loaderCheckPoint.model_name = llm_model_info['name'] # 将loaderCheckPoint的模型名称设置为模型信息中的name
else: # 如果使用远程模型
loaderCheckPoint.model_name = llm_model_info['pretrained_model_name'] # 将loaderCheckPoint的模型名称设置为模型信息中的pretrained_model_name
loaderCheckPoint.model_path = llm_model_info["local_model_path"] # 设置模型的本地路径
if 'FastChatOpenAILLM' in llm_model_info["provides"]: # 如果模型信息中的provides包含'FastChatOpenAILLM'
loaderCheckPoint.unload_model() # 卸载模型
else: # 如果不包含
loaderCheckPoint.reload_model() # 重新加载模型
provides_class = getattr(sys.modules['models'], llm_model_info['provides']) # 获取模型类
modelInsLLM = provides_class(checkPoint=loaderCheckPoint) # 创建模型实例
if 'FastChatOpenAILLM' in llm_model_info["provides"]: # 如果模型信息中的provides包含'FastChatOpenAILLM'
modelInsLLM.set_api_base_url(llm_model_info['api_base_url']) # 设置API基础URL
modelInsLLM.call_model_name(llm_model_info['name']) # 设置模型名称
return modelInsLLM # 返回模型实例// 待更..
3.3 configs:配置文件存储model_config.py
import torch.cuda
import torch.backends
import os
import logging
import uuid
LOG_FORMAT = "%(levelname) -5s %(asctime)s" "-1d: %(message)s"
logger = logging.getLogger()
logger.setLevel(logging.INFO)
logging.basicConfig(format=LOG_FORMAT)
# 在以下字典中修改属性值,以指定本地embedding模型存储位置
# 如将 "text2vec": "GanymedeNil/text2vec-large-chinese" 修改为 "text2vec": "User/Downloads/text2vec-large-chinese"
# 此处请写绝对路径
embedding_model_dict = {
"ernie-tiny": "nghuyong/ernie-3.0-nano-zh",
"ernie-base": "nghuyong/ernie-3.0-base-zh",
"text2vec-base": "shibing624/text2vec-base-chinese",
"text2vec": "GanymedeNil/text2vec-large-chinese",
"m3e-small": "moka-ai/m3e-small",
"m3e-base": "moka-ai/m3e-base",
}
# Embedding model name
EMBEDDING_MODEL = "text2vec"
# Embedding running device
EMBEDDING_DEVICE = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
# supported LLM models
# llm_model_dict 处理了loader的一些预设行为,如加载位置,模型名称,模型处理器实例
# 在以下字典中修改属性值,以指定本地 LLM 模型存储位置
# 如将 "chatglm-6b" 的 "local_model_path" 由 None 修改为 "User/Downloads/chatglm-6b"
# 此处请写绝对路径
llm_model_dict = {
"chatglm-6b-int4-qe": {
"name": "chatglm-6b-int4-qe",
"pretrained_model_name": "THUDM/chatglm-6b-int4-qe",
"local_model_path": None,
"provides": "ChatGLM"
},
"chatglm-6b-int4": {
"name": "chatglm-6b-int4",
"pretrained_model_name": "THUDM/chatglm-6b-int4",
"local_model_path": None,
"provides": "ChatGLM"
},
"chatglm-6b-int8": {
"name": "chatglm-6b-int8",
"pretrained_model_name": "THUDM/chatglm-6b-int8",
"local_model_path": None,
"provides": "ChatGLM"
},
"chatglm-6b": {
"name": "chatglm-6b",
"pretrained_model_name": "THUDM/chatglm-6b",
"local_model_path": None,
"provides": "ChatGLM"
},
"chatglm2-6b": {
"name": "chatglm2-6b",
"pretrained_model_name": "THUDM/chatglm2-6b",
"local_model_path": None,
"provides": "ChatGLM"
},
"chatglm2-6b-int4": {
"name": "chatglm2-6b-int4",
"pretrained_model_name": "THUDM/chatglm2-6b-int4",
"local_model_path": None,
"provides": "ChatGLM"
},
"chatglm2-6b-int8": {
"name": "chatglm2-6b-int8",
"pretrained_model_name": "THUDM/chatglm2-6b-int8",
"local_model_path": None,
"provides": "ChatGLM"
},
"chatyuan": {
"name": "chatyuan",
"pretrained_model_name": "ClueAI/ChatYuan-large-v2",
"local_model_path": None,
"provides": None
},
"moss": {
"name": "moss",
"pretrained_model_name": "fnlp/moss-moon-003-sft",
"local_model_path": None,
"provides": "MOSSLLM"
},
"vicuna-13b-hf": {
"name": "vicuna-13b-hf",
"pretrained_model_name": "vicuna-13b-hf",
"local_model_path": None,
"provides": "LLamaLLM"
},
# 通过 fastchat 调用的模型请参考如下格式
"fastchat-chatglm-6b": {
"name": "chatglm-6b", # "name"修改为fastchat服务中的"model_name"
"pretrained_model_name": "chatglm-6b",
"local_model_path": None,
"provides": "FastChatOpenAILLM", # 使用fastchat api时,需保证"provides"为"FastChatOpenAILLM"
"api_base_url": "http://localhost:8000/v1" # "name"修改为fastchat服务中的"api_base_url"
},
"fastchat-chatglm2-6b": {
"name": "chatglm2-6b", # "name"修改为fastchat服务中的"model_name"
"pretrained_model_name": "chatglm2-6b",
"local_model_path": None,
"provides": "FastChatOpenAILLM", # 使用fastchat api时,需保证"provides"为"FastChatOpenAILLM"
"api_base_url": "http://localhost:8000/v1" # "name"修改为fastchat服务中的"api_base_url"
},
# 通过 fastchat 调用的模型请参考如下格式
"fastchat-vicuna-13b-hf": {
"name": "vicuna-13b-hf", # "name"修改为fastchat服务中的"model_name"
"pretrained_model_name": "vicuna-13b-hf",
"local_model_path": None,
"provides": "FastChatOpenAILLM", # 使用fastchat api时,需保证"provides"为"FastChatOpenAILLM"
"api_base_url": "http://localhost:8000/v1" # "name"修改为fastchat服务中的"api_base_url"
},
}
# LLM 名称
LLM_MODEL = "chatglm-6b"
# 量化加载8bit 模型
LOAD_IN_8BIT = False
# Load the model with bfloat16 precision. Requires NVIDIA Ampere GPU.
BF16 = False
# 本地lora存放的位置
LORA_DIR = "loras/"
# LLM lora path,默认为空,如果有请直接指定文件夹路径
LLM_LORA_PATH = ""
USE_LORA = True if LLM_LORA_PATH else False
# LLM streaming reponse
STREAMING = True
# Use p-tuning-v2 PrefixEncoder
USE_PTUNING_V2 = False
# LLM running device
LLM_DEVICE = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
# 知识库默认存储路径
KB_ROOT_PATH = os.path.join(os.path.dirname(os.path.dirname(__file__)), "knowledge_base")
# 基于上下文的prompt模版,请务必保留"{question}"和"{context}"
PROMPT_TEMPLATE = """已知信息:
{context}
根据上述已知信息,简洁和专业的来回答用户的问题。如果无法从中得到答案,请说 “根据已知信息无法回答该问题” 或 “没有提供足够的相关信息”,不允许在答案中添加编造成分,答案请使用中文。 问题是:{question}"""
# 缓存知识库数量,如果是ChatGLM2,ChatGLM2-int4,ChatGLM2-int8模型若检索效果不好可以调成’10’
CACHED_VS_NUM = 1
# 文本分句长度
SENTENCE_SIZE = 100
# 匹配后单段上下文长度
CHUNK_SIZE = 250
# 传入LLM的历史记录长度
LLM_HISTORY_LEN = 3
# 知识库检索时返回的匹配内容条数
VECTOR_SEARCH_TOP_K = 5
# 知识检索内容相关度 Score, 数值范围约为0-1100,如果为0,则不生效,经测试设置为小于500时,匹配结果更精准
VECTOR_SEARCH_SCORE_THRESHOLD = 0
NLTK_DATA_PATH = os.path.join(os.path.dirname(os.path.dirname(__file__)), "nltk_data")
FLAG_USER_NAME = uuid.uuid4().hex
logger.info(f"""
loading model config
llm device: {LLM_DEVICE}
embedding device: {EMBEDDING_DEVICE}
dir: {os.path.dirname(os.path.dirname(__file__))}
flagging username: {FLAG_USER_NAME}
""")
# 是否开启跨域,默认为False,如果需要开启,请设置为True
# is open cross domain
OPEN_CROSS_DOMAIN = False
# Bing 搜索必备变量
# 使用 Bing 搜索需要使用 Bing Subscription Key,需要在azure port中申请试用bing search
# 具体申请方式请见
# https://learn.microsoft.com/en-us/bing/search-apis/bing-web-search/create-bing-search-service-resource
# 使用python创建bing api 搜索实例详见:
# https://learn.microsoft.com/en-us/bing/search-apis/bing-web-search/quickstarts/rest/python
BING_SEARCH_URL = "https://api.bing.microsoft.com/v7.0/search"
# 注意不是bing Webmaster Tools的api key,
# 此外,如果是在服务器上,报Failed to establish a new connection: [Errno 110] Connection timed out
# 是因为服务器加了防火墙,需要联系管理员加白名单,如果公司的服务器的话,就别想了GG
BING_SUBSCRIPTION_KEY = ""
# 是否开启中文标题加强,以及标题增强的相关配置
# 通过增加标题判断,判断哪些文本为标题,并在metadata中进行标记;
# 然后将文本与往上一级的标题进行拼合,实现文本信息的增强。
ZH_TITLE_ENHANCE = False3.4 loader:文档加载与text转换
3.4.1 loader/pdf_loader.py
# 导入类型提示模块,用于强化代码的可读性和健壮性
from typing import List
# 导入UnstructuredFileLoader,这是一个从非结构化文件中加载文档的类
from langchain.document_loaders.unstructured import UnstructuredFileLoader
# 导入PaddleOCR,这是一个开源的OCR工具,用于从图片中识别和读取文字
from paddleocr import PaddleOCR
# 导入os模块,用于处理文件和目录
import os
# 导入fitz模块,用于处理PDF文件
import fitz
# 导入nltk模块,用于处理文本数据
import nltk
# 导入模型配置文件中的NLTK_DATA_PATH,这是nltk数据的路径
from configs.model_config import NLTK_DATA_PATH
# 设置nltk数据的路径,将模型配置中的路径添加到nltk的数据路径中
nltk.data.path = [NLTK_DATA_PATH] + nltk.data.path
# 定义一个类,UnstructuredPaddlePDFLoader,该类继承自UnstructuredFileLoader
class UnstructuredPaddlePDFLoader(UnstructuredFileLoader):
# 定义一个内部方法_get_elements,返回一个列表
def _get_elements(self) -> List:
# 定义一个内部函数pdf_ocr_txt,用于从pdf中进行OCR并输出文本文件
def pdf_ocr_txt(filepath, dir_path="tmp_files"):
# 将dir_path与filepath的目录部分合并成一个新的路径
full_dir_path = os.path.join(os.path.dirname(filepath), dir_path)
# 如果full_dir_path对应的目录不存在,则创建这个目录
if not os.path.exists(full_dir_path):
os.makedirs(full_dir_path)
# 创建一个PaddleOCR实例,设置一些参数
ocr = PaddleOCR(use_angle_cls=True, lang="ch", use_gpu=False, show_log=False)
# 打开pdf文件
doc = fitz.open(filepath)
# 创建一个txt文件的路径
txt_file_path = os.path.join(full_dir_path, f"{os.path.split(filepath)[-1]}.txt")
# 创建一个临时的图片文件路径
img_name = os.path.join(full_dir_path, 'tmp.png')
# 打开txt_file_path对应的文件,并以写模式打开
with open(txt_file_path, 'w', encoding='utf-8') as fout:
# 遍历pdf的所有页面
for i in range(doc.page_count):
# 获取当前页面
page = doc[i]
# 获取当前页面的文本内容,并写入txt文件
text = page.get_text("")
fout.write(text)
fout.write("\n")
# 获取当前页面的所有图片
img_list = page.get_images()
# 遍历所有图片
for img in img_list:
# 将图片转换为Pixmap对象
pix = fitz.Pixmap(doc, img[0])
# 如果图片有颜色信息,则将其转换为RGB格式
if pix.n - pix.alpha >= 4:
pix = fitz.Pixmap(fitz.csRGB, pix)
# 保存图片
pix.save(img_name)
# 对图片进行OCR识别
result = ocr.ocr(img_name)
# 从OCR结果中提取文本,并写入txt文件
ocr_result = [i[1][0] for line in result for i in line]
fout.write("\n".join(ocr_result))
# 如果图片文件存在,则删除它
if os.path.exists(img_name):
os.remove(img_name)
# 返回txt文件的路径
return txt_file_path
# 调用上面定义的函数,获取txt文件的路径
txt_file_path = pdf_ocr_txt(self.file_path)
# 导入partition_text函数,该函数用于将文本文件分块
from unstructured.partition.text import partition_text
# 对txt文件进行分块,并返回分块结果
return partition_text(filename=txt_file_path, **self.unstructured_kwargs)
# 运行入口
if __name__ == "__main__":
# 导入sys模块,用于操作Python的运行环境
import sys
# 将当前文件的上一级目录添加到Python的搜索路径中
sys.path.append(os.path.dirname(os.path.dirname(__file__)))
# 定义一个pdf文件的路径
filepath = os.path.join(os.path.dirname(os.path.dirname(__file__)), "knowledge_base", "samples", "content", "test.pdf")
# 创建一个UnstructuredPaddlePDFLoader的实例
loader = UnstructuredPaddlePDFLoader(filepath, mode="elements")
# 加载文档
docs = loader.load()
# 遍历并打印所有文档
for doc in docs:
print(doc)// 待更..
3.5 textsplitter:文档切分
3.5.1 textsplitter/ali_text_splitter.py
ali_text_splitter.py的代码如下所示
# 导入CharacterTextSplitter模块,用于文本切分
from langchain.text_splitter import CharacterTextSplitter
import re # 导入正则表达式模块,用于文本匹配和替换
from typing import List # 导入List类型,用于指定返回的数据类型
# 定义一个新的类AliTextSplitter,继承自CharacterTextSplitter
class AliTextSplitter(CharacterTextSplitter):
# 类的初始化函数,如果参数pdf为True,那么使用pdf文本切分规则,否则使用默认规则
def __init__(self, pdf: bool = False, **kwargs):
# 调用父类的初始化函数,接收传入的其他参数
super().__init__(**kwargs)
self.pdf = pdf # 将pdf参数保存为类的成员变量
# 定义文本切分方法,输入参数为一个字符串,返回值为字符串列表
def split_text(self, text: str) -> List[str]:
if self.pdf: # 如果pdf参数为True,那么对文本进行预处理
# 替换掉连续的3个及以上的换行符为一个换行符
text = re.sub(r"\n{3,}", r"\n", text)
# 将所有的空白字符(包括空格、制表符、换页符等)替换为一个空格
text = re.sub('\s', " ", text)
# 将连续的两个换行符替换为一个空字符
text = re.sub("\n\n", "", text)
# 导入pipeline模块,用于创建一个处理流程
from modelscope.pipelines import pipeline
# 创建一个document-segmentation任务的处理流程
# 用的模型为damo/nlp_bert_document-segmentation_chinese-base,计算设备为cpu
p = pipeline(
task="document-segmentation",
model='damo/nlp_bert_document-segmentation_chinese-base',
device="cpu")
result = p(documents=text) # 对输入的文本进行处理,返回处理结果
sent_list = [i for i in result["text"].split("\n\t") if i] # 将处理结果按照换行符和制表符进行切分,得到句子列表
return sent_list # 返回句子列表其中,有三点值得注意下
- 参数use_document_segmentation指定是否用语义切分文档
此处采取的文档语义分割模型为达摩院开源的:nlp_bert_document-segmentation_chinese-base (这是其论文) - 另,如果使用模型进行文档语义切分,那么需要安装:
modelscope[nlp]:pip install "modelscope[nlp]" -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html - 且考虑到使用了三个模型,可能对于低配置gpu不太友好,因此这里将模型load进cpu计算,有需要的话可以替换device为自己的显卡id
3.6 knowledge_base:存储用户上传的文件并向量化
knowledge_bas下面有两个文件,一个content 即用户上传的原始文件,vector_store则用于存储向量库⽂件,即本地知识库本体,因为content因人而异 谁上传啥就是啥 所以没啥好分析,而vector_store下面则有两个文件,一个index.faiss,一个index.pkl
3.7 chains:向量搜索/匹配
如之前所述,本节开头图中“FAISS索引、FAISS搜索”中的“FAISS”是Facebook AI推出的一种用于有效搜索大规模高维向量空间中相似度的库,在大规模数据集中快速找到与给定向量最相似的向量是很多AI应用的重要组成部分,例如在推荐系统、自然语言处理、图像检索等领域
3.7.1 chains/modules /vectorstores.py文件:根据查询向量query在向量数据库中查找与query相似的文本向量
主要是关于
- FAISS (Facebook AI Similarity Search)的使用,具体体现在max_marginal_relevance_search_by_vector 中(如下图的最上面部分)
- 以及一个FAISS向量存储类(FAISSVS,FAISSVS类继承自FAISS类)的定义,包含两个方法
一个 max_marginal_relevance_search (如下图的中间部分,其最后会调用上面的max_marginal_relevance_search_by_vector)
一个 __from (如下图的最下面部分)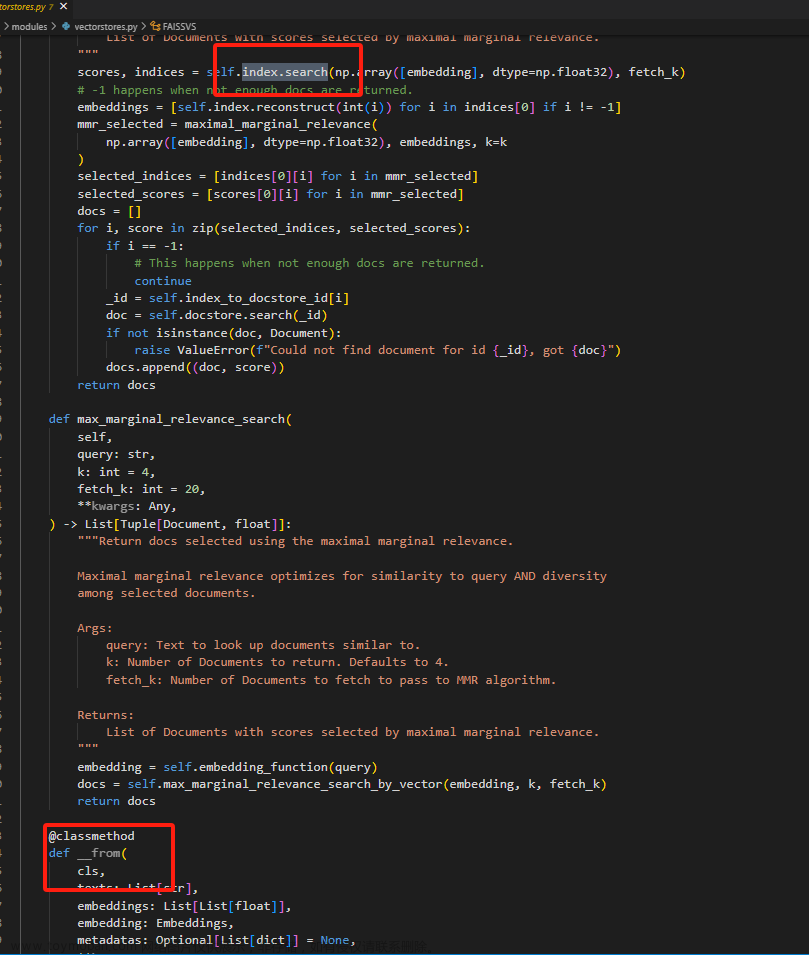
接下来,我们逐一分析下这几个函数
-
max_marginal_relevance_search
分两步,给定查询语句,首先将查询语句转换为嵌入向量「embedding = self.embedding_function(query)」,然后调用 max_marginal_relevance_search_by_vector 函数进行MMR搜索下面看下其中 max_marginal_relevance_search_by_vector 的实现# 使用最大边际相关性返回被选中的文本 def max_marginal_relevance_search( self, query: str, # 查询 k: int = 4, # 返回的文档数量,默认为 4 fetch_k: int = 20, # 用于传递给 MMR 算法的抓取文档数量 **kwargs: Any, ) -> List[Tuple[Document, float]]: # 查询向量化 embedding = self.embedding_function(query) # 调用:max_marginal_relevance_search_by_vector docs = self.max_marginal_relevance_search_by_vector(embedding, k, fetch_k) return docs
该函数通过给定的嵌入向量,使用最大边际相关性(Maximal Marginal Relevance, MMR)方法来返回相关的文本
MMR是一种解决查询结果多样性和相关性的算法,具体来说,它不仅要求返回的文本与查询尽可能相似,而且希望返回的文本集之间尽可能多样注意,上面第6-7行代码中,直接调用的index的search函数# 使用最大边际相关性返回被选中的文档,最大边际相关性旨在优化查询的相似性和选定文本之间的多样性 def max_marginal_relevance_search_by_vector( self, embedding: List[float], k: int = 4, fetch_k: int = 20, **kwargs: Any ) -> List[Tuple[Document, float]]: # 使用索引在文本中搜索与嵌入向量相似的内容,返回最相似的fetch_k个文本的得分和索引 scores, indices = self.index.search(np.array([embedding], dtype=np.float32), fetch_k) # 通过索引从文本中重构出嵌入向量,-1表示没有足够的文本返回 embeddings = [self.index.reconstruct(int(i)) for i in indices[0] if i != -1] # 使用最大边际相关性算法选择出k个最相关的文本 mmr_selected = maximal_marginal_relevance( np.array([embedding], dtype=np.float32), embeddings, k=k ) selected_indices = [indices[0][i] for i in mmr_selected] # 获取被选中的文本的索引 selected_scores = [scores[0][i] for i in mmr_selected] # 获取被选中的文本的得分 docs = [] for i, score in zip(selected_indices, selected_scores): # 对于每个被选中的文本索引和得分 if i == -1: # 如果索引为-1,表示没有足够的文本返回 continue _id = self.index_to_docstore_id[i] # 通过索引获取文本的id doc = self.docstore.search(_id) # 通过id在文档库中搜索文本 if not isinstance(doc, Document): # 如果搜索到的文本不是Document类型,抛出错误 raise ValueError(f"Could not find document for id {_id}, got {doc}") docs.append((doc, score)) # 将文本和得分添加到结果列表中 return docs # 返回结果列表
# 使用索引在文本中搜索与嵌入向量相似的内容,返回最相似的fetch_k个文本的得分和索引
scores, indices = self.index.search(np.array([embedding], dtype=np.float32), fetch_k)
这里面就有来头了,通过和我司杜老师的讨论确定,这个search是根据构建索引时所用的度量指标找到最近的k个向量的,在构建索引时
如果是faiss.IndexFlatIP,就是内积(METRIC_INNER_PRODUCT),可以认为是余弦相似度
如果是faiss.IndexFlatL2,就是欧氏距离(METRIC_L2),更多计算距离的方式详见上文的2.2.2节
其具体的代码实现如下所示(来源:faiss/IndexFlat.cpp#L27)void IndexFlat::search( idx_t n, // 搜索的查询向量的数量 const float* x, // 指向查询向量数据的指针 idx_t k, // 每个查询向量返回的最近邻个数 float* distances, // 返回的距离数组 idx_t* labels, // 返回的标签数组 const SearchParameters* params) const { // 搜索参数 // 如果params非空,则使用params中的选择器,否则使用nullptr IDSelector* sel = params ? params->sel : nullptr; // 检查k(最近邻的数量)必须大于0 FAISS_THROW_IF_NOT(k > 0); // distances和labels被视为堆(用于存储最近邻的结果) if (metric_type == METRIC_INNER_PRODUCT) { // 如果度量类型是内积 float_minheap_array_t res = {size_t(n), size_t(k), labels, distances}; // 使用内积计算最近邻 knn_inner_product(x, get_xb(), d, n, ntotal, &res, sel); } else if (metric_type == METRIC_L2) { // 如果度量类型是L2距离 float_maxheap_array_t res = {size_t(n), size_t(k), labels, distances}; // 使用L2距离计算最近邻 knn_L2sqr(x, get_xb(), d, n, ntotal, &res, nullptr, sel); } else if (is_similarity_metric(metric_type)) { // 如果度量类型是其他相似度度量 float_minheap_array_t res = {size_t(n), size_t(k), labels, distances}; // 使用其他相似度度量计算最近邻 knn_extra_metrics( x, get_xb(), d, n, ntotal, metric_type, metric_arg, &res); } else { // 其他情况 FAISS_THROW_IF_NOT(!sel); // 确保选择器为空 float_maxheap_array_t res = {size_t(n), size_t(k), labels, distances}; // 使用其他相似度度量计算最近邻 knn_extra_metrics( x, get_xb(), d, n, ntotal, metric_type, metric_arg, &res); } } -
__from
用于从一组文本和对应的嵌入向量创建一个FAISSVS实例。该方法首先创建一个FAISS索引并添加嵌入向量,然后创建一个文本存储以存储与每个嵌入向量关联的文本从上面代码的第11-13行中# 从给定的文本、嵌入向量、元数据等信息构建一个FAISS索引对象 def __from( cls, texts: List[str], # 文本列表,每个文本将被转化为一个文本对象 embeddings: List[List[float]], # 对应文本的嵌入向量列表 embedding: Embeddings, # 嵌入向量生成器,用于将查询语句转化为嵌入向量 metadatas: Optional[List[dict]] = None, **kwargs: Any, ) -> FAISS: faiss = dependable_faiss_import() # 导入FAISS库 index = faiss.IndexFlatIP(len(embeddings[0])) # 使用FAISS库创建一个新的索引,索引的维度等于嵌入文本向量的长度 index.add(np.array(embeddings, dtype=np.float32)) # 将嵌入向量添加到FAISS索引中 # quantizer = faiss.IndexFlatL2(len(embeddings[0])) # index = faiss.IndexIVFFlat(quantizer, len(embeddings[0]), 100) # index.train(np.array(embeddings, dtype=np.float32)) # index.add(np.array(embeddings, dtype=np.float32)) documents = [] for i, text in enumerate(texts): # 对于每一段文本 # 获取对应的元数据,如果没有提供元数据则使用空字典 metadata = metadatas[i] if metadatas else {} # 创建一个文本对象并添加到文本列表中 documents.append(Document(page_content=text, metadata=metadata)) # 为每个文本生成一个唯一的ID index_to_id = {i: str(uuid.uuid4()) for i in range(len(documents))} # 创建一个文本库,用于存储文本对象和对应的ID docstore = InMemoryDocstore( {index_to_id[i]: doc for i, doc in enumerate(documents)} ) # 返回FAISS对象 return cls(embedding.embed_query, index, docstore, index_to_id)
faiss = dependable_faiss_import() # 导入FAISS库
index = faiss.IndexFlatIP(len(embeddings[0])) # 使用FAISS库创建一个新的索引,索引的维度等于嵌入文本向量的长度
index.add(np.array(embeddings, dtype=np.float32)) # 将嵌入向量添加到FAISS索引中
可知,构建index的时候就已经指定了用IndexFlatIP(余弦相似度)的方式计算距离(你可以通过这个代码链接验证下:chains/modules/vectorstores.py#L103)
以上就是这段代码的主要内容,通过使用FAISS和MMR,它可以帮助我们在大量文本中找到与给定查询最相关的文本
3.7.2 chains /local_doc_qa.py代码文件:向量搜索
- 导入包和模块
代码开始的部分是一系列的导入语句,导入了必要的 Python 包和模块,包括文件加载器,文本分割器,模型配置,以及一些 Python 内建模块和其他第三方库 - 改写 HuggingFaceEmbeddings 类的哈希方法
代码定义了一个名为 _embeddings_hash 的函数,并将其赋值给 HuggingFaceEmbeddings 类的 __hash__ 方法。这样做的目的是使 HuggingFaceEmbeddings 对象可以被哈希,即可以作为字典的键或者被加入到集合中 - 载入向量存储器
定义了一个名为 load_vector_store 的函数,这个函数用于从本地加载一个向量存储器,返回 FAISS 类的对象。其中使用了 lru_cache 装饰器,可以缓存最近使用的 CACHED_VS_NUM 个结果,提高代码效率 - 文件树遍历
tree 函数是一个递归函数,用于遍历指定目录下的所有文件,返回一个包含所有文件的完整路径和文件名的列表。它可以忽略指定的文件或目录 - 加载文件:
load_file 函数根据文件后缀名选择合适的加载器和文本分割器,加载并分割文件 - 生成提醒:
generate_prompt 函数用于根据相关文档和查询生成一个提醒。提醒的模板由 prompt_template 参数提供 - 创建文档列表
search_result2docs# 创建一个空列表,用于存储文档 def search_result2docs(search_results): docs = [] # 对于搜索结果中的每一项 for result in search_results: # 创建一个文档对象 # 如果结果中包含"snippet"关键字,则其值作为页面内容,否则页面内容为空字符串 # 如果结果中包含"link"关键字,则其值作为元数据中的源链接,否则源链接为空字符串 # 如果结果中包含"title"关键字,则其值作为元数据中的文件名,否则文件名为空字符串 doc = Document(page_content=result["snippet"] if "snippet" in result.keys() else "", metadata={"source": result["link"] if "link" in result.keys() else "", "filename": result["title"] if "title" in result.keys() else ""}) # 将创建的文档对象添加到列表中 docs.append(doc) # 返回文档列表 return docs
之后,定义了一个名为 LocalDocQA 的类,主要用于基于文档的问答任务。基于文档的问答任务的主要功能是,根据一组给定的文档(这里被称为知识库)以及用户输入的问题,返回一个答案,LocalDocQA 类的主要方法包括:
- init_cfg():此方法初始化一些变量,包括将 llm_model(一个语言模型用于生成答案)分配给 self.llm,将一个基于HuggingFace的嵌入模型分配给 self.embeddings,将输入参数 top_k 分配给 self.top_k
- init_knowledge_vector_store():此方法负责初始化知识向量库。它首先检查输入的文件路径,对于路径中的每个文件,将文件内容加载到 Document 对象中,然后将这些文档转换为嵌入向量,并将它们存储在向量库中
- one_knowledge_add():此方法用于向知识库中添加一个新的知识文档。它将输入的标题和内容创建为一个 Document 对象,然后将其转换为嵌入向量,并添加到向量库中
-
get_knowledge_based_answer():此方法是基于给定的知识库和用户输入的问题,来生成一个答案。它首先根据用户输入的问题找到知识库中最相关的文档,然后生成一个包含相关文档和用户问题的提示,将提示传递给 llm_model 来生成答案
且注意一点,这个函数调用了上面已经实现好的:similarity_search_with_score -
get_knowledge_based_conent_test():此方法是为了测试的,它将返回与输入查询最相关的文档和查询提示
# query 查询内容
# vs_path 知识库路径
# chunk_conent 是否启用上下文关联
# score_threshold 搜索匹配score阈值
# vector_search_top_k 搜索知识库内容条数,默认搜索5条结果
# chunk_sizes 匹配单段内容的连接上下文长度
def get_knowledge_based_conent_test(self, query, vs_path, chunk_conent,
score_threshold=VECTOR_SEARCH_SCORE_THRESHOLD,
vector_search_top_k=VECTOR_SEARCH_TOP_K, chunk_size=CHUNK_SIZE): -
get_search_result_based_answer():此方法与 get_knowledge_based_answer() 类似,不过这里使用的是 bing_search 的结果作为知识库
如你所见,这个函数和上面那个函数的主要区别在于,这个函数是直接利用搜索引擎的搜索结果来生成回答的,而上面那个函数是通过查询相似度搜索来找到最相关的文本,然后基于这些文本生成回答的
def get_search_result_based_answer(self, query, chat_history=[], streaming: bool = STREAMING): # 对查询进行 Bing 搜索,并获取搜索结果 results = bing_search(query) # 将搜索结果转化为文本的形式 result_docs = search_result2docs(results) # 生成用于提问的提示语 prompt = generate_prompt(result_docs, query) # 通过 LLM(长语言模型)生成回答 for answer_result in self.llm.generatorAnswer(prompt=prompt, history=chat_history, streaming=streaming): # 获取回答的文本 resp = answer_result.llm_output["answer"] # 获取聊天历史 history = answer_result.history # 将聊天历史中的最后一项的提问替换为当前的查询 history[-1][0] = query # 组装回答的结果 response = {"query": query, "result": resp, "source_documents": result_docs} # 返回回答的结果和聊天历史 yield response, history
而这个bing_search则在3.1.2节中已经定义 - 接下来是分别用于从向量存储中删除文件、更新文件以及列出文件的三个方法
delete_file_from_vector_store
update_file_from_vector_store
list_file_from_vector_store# 删除向量存储中的文件 def delete_file_from_vector_store(self, filepath: str or List[str], # 文件路径,可以是单个文件或多个文件列表 vs_path): # 向量存储路径 vector_store = load_vector_store(vs_path, self.embeddings) # 从给定路径加载向量存储 status = vector_store.delete_doc(filepath) # 删除指定文件 return status # 返回删除状态 # 更新向量存储中的文件 def update_file_from_vector_store(self, filepath: str or List[str], # 需要更新的文件路径,可以是单个文件或多个文件列表 vs_path, # 向量存储路径 docs: List[Document],): # 需要更新的文件内容,文件以文档形式给出 vector_store = load_vector_store(vs_path, self.embeddings) # 从给定路径加载向量存储 status = vector_store.update_doc(filepath, docs) # 更新指定文件 return status # 返回更新状态 # 列出向量存储中的文件 def list_file_from_vector_store(self, vs_path, # 向量存储路径 fullpath=False): # 是否返回完整路径,如果为 False,则只返回文件名 vector_store = load_vector_store(vs_path, self.embeddings) # 从给定路径加载向量存储 docs = vector_store.list_docs() # 列出所有文件 if fullpath: # 如果需要完整路径 return docs # 返回完整路径列表 else: # 如果只需要文件名 return [os.path.split(doc)[-1] for doc in docs] # 用 os.path.split 将路径和文件名分离,只返回文件名列表
__main__部分的代码是 LocalDocQA 类的实例化和使用示例
- 它首先初始化了一个 llm_model_ins 对象
- 然后创建了一个 LocalDocQA 的实例并调用其 init_cfg() 方法进行初始化
- 之后,它指定了一个查询和知识库的路径
- 然后调用 get_knowledge_based_answer() 或 get_search_result_based_answer() 方法获取基于该查询的答案,并打印出答案和来源文档的信息
3.7.3 chains/text_load.py
chain这个文件夹下 还有最后一个项目文件(langchain-ChatGLM/text_load.py at master · imClumsyPanda/langchain-ChatGLM · GitHub),如下所示
import os
import pinecone
from tqdm import tqdm
from langchain.llms import OpenAI
from langchain.text_splitter import SpacyTextSplitter
from langchain.document_loaders import TextLoader
from langchain.document_loaders import DirectoryLoader
from langchain.indexes import VectorstoreIndexCreator
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Pinecone
#一些配置文件
openai_key="你的key" # 注册 openai.com 后获得
pinecone_key="你的key" # 注册 app.pinecone.io 后获得
pinecone_index="你的库" #app.pinecone.io 获得
pinecone_environment="你的Environment" # 登录pinecone后,在indexes页面 查看Environment
pinecone_namespace="你的Namespace" #如果不存在自动创建
#科学上网你懂得
os.environ['HTTP_PROXY'] = 'http://127.0.0.1:7890'
os.environ['HTTPS_PROXY'] = 'http://127.0.0.1:7890'
#初始化pinecone
pinecone.init(
api_key=pinecone_key,
environment=pinecone_environment
)
index = pinecone.Index(pinecone_index)
#初始化OpenAI的embeddings
embeddings = OpenAIEmbeddings(openai_api_key=openai_key)
#初始化text_splitter
text_splitter = SpacyTextSplitter(pipeline='zh_core_web_sm',chunk_size=1000,chunk_overlap=200)
# 读取目录下所有后缀是txt的文件
loader = DirectoryLoader('../docs', glob="**/*.txt", loader_cls=TextLoader)
#读取文本文件
documents = loader.load()
# 使用text_splitter对文档进行分割
split_text = text_splitter.split_documents(documents)
try:
for document in tqdm(split_text):
# 获取向量并储存到pinecone
Pinecone.from_documents([document], embeddings, index_name=pinecone_index)
except Exception as e:
print(f"Error: {e}")
quit()3.8 vectorstores:MyFAISS.py
两个文件,一个__init__.py (就一行代码:from .MyFAISS import MyFAISS),另一个MyFAISS.py,如下代码所示
# 从langchain.vectorstores库导入FAISS
from langchain.vectorstores import FAISS
# 从langchain.vectorstores.base库导入VectorStore
from langchain.vectorstores.base import VectorStore
# 从langchain.vectorstores.faiss库导入dependable_faiss_import
from langchain.vectorstores.faiss import dependable_faiss_import
from typing import Any, Callable, List, Dict # 导入类型检查库
from langchain.docstore.base import Docstore # 从langchain.docstore.base库导入Docstore
# 从langchain.docstore.document库导入Document
from langchain.docstore.document import Document
import numpy as np # 导入numpy库,用于科学计算
import copy # 导入copy库,用于数据复制
import os # 导入os库,用于操作系统相关的操作
from configs.model_config import * # 从configs.model_config库导入所有内容
# 定义MyFAISS类,继承自FAISS和VectorStore两个父类
class MyFAISS(FAISS, VectorStore):接下来,逐一实现以下函数
3.8.1 定义类的初始化函数:__init__
# 定义类的初始化函数
def __init__(
self,
embedding_function: Callable,
index: Any,
docstore: Docstore,
index_to_docstore_id: Dict[int, str],
normalize_L2: bool = False,
):
# 调用父类FAISS的初始化函数
super().__init__(embedding_function=embedding_function,
index=index,
docstore=docstore,
index_to_docstore_id=index_to_docstore_id,
normalize_L2=normalize_L2)
# 初始化分数阈值
self.score_threshold=VECTOR_SEARCH_SCORE_THRESHOLD
# 初始化块大小
self.chunk_size = CHUNK_SIZE
# 初始化块内容
self.chunk_conent = False3.8.2 seperate_list:将一个列表分解成多个子列表
# 定义函数seperate_list,将一个列表分解成多个子列表,每个子列表中的元素在原列表中是连续的
def seperate_list(self, ls: List[int]) -> List[List[int]]:
# TODO: 增加是否属于同一文档的判断
lists = []
ls1 = [ls[0]]
for i in range(1, len(ls)):
if ls[i - 1] + 1 == ls[i]:
ls1.append(ls[i])
else:
lists.append(ls1)
ls1 = [ls[i]]
lists.append(ls1)
return lists3.8.3 similarity_search_with_score_by_vector,根据输入的向量,查找最接近的k个文本
similarity_search_with_score_by_vector 函数用于通过向量进行相似度搜索,返回与给定嵌入向量最相似的文本和对应的分数
不过,这个函数考虑的细节比较多,所以代码长度比较长,为方便大家更好的理解,我把这个函数拆分成5段逐一解释说明
- 定义相似度搜索的函数,其接受一个向量embedding和一个整数k作为参数,之后导入faiss库,从而调用faiss库的search函数(对该search函数的细致分析及具体代码层面的实现,详见上文的3.7.1节),查找与输入向量最接近的k个向量,并返回他们的分数和索引
并初始化文档列表docs、文档ID:id_set,方便后面索引找ID、ID找文本# 定义函数similarity_search_with_score_by_vector,根据输入的向量,查找最接近的k个文本 def similarity_search_with_score_by_vector( self, embedding: List[float], k: int = 4 ) -> List[Document]: # 调用dependable_faiss_import函数,导入faiss库 faiss = dependable_faiss_import() # 将输入的列表转换为numpy数组,并设置数据类型为float32 vector = np.array([embedding], dtype=np.float32) # 如果需要进行L2归一化,则调用faiss.normalize_L2函数进行归一化 if self._normalize_L2: faiss.normalize_L2(vector) # 调用faiss库的search函数,查找与输入向量最接近的k个向量,并返回他们的分数和索引 scores, indices = self.index.search(vector, k) # 初始化一个空列表,用于存储找到的文本 docs = [] # 初始化一个空集合,用于存储文本的id id_set = set() # 获取文本库中文本的数量 store_len = len(self.index_to_docstore_id) # 初始化一个布尔变量,表示是否需要重新排列id列表 rearrange_id_list = False - 通过遍历上面得到的索引indices和分数scores,以验证是否满足要求
即,索引和分数需要满足一定的条件:比如索引不为-1、分数得大于给定的阈值等
如果满足,则获取索引 i 对应的文本ID:_id = self.index_to_docstore_id[i]
最终从文本库中找到对应ID的文本(相当于索引到ID、ID到文本):doc = self.docstore.search(_id)# 遍历找到的索引和分数 for j, i in enumerate(indices[0]): # 如果索引为-1,或者分数小于阈值,则跳过这个索引 if i == -1 or 0 < self.score_threshold < scores[0][j]: # This happens when not enough docs are returned. continue # 如果索引存在于index_to_docstore_id字典中,则获取对应的文本id if i in self.index_to_docstore_id: _id = self.index_to_docstore_id[i] # 如果索引不存在于index_to_docstore_id字典中,则跳过这个索引 else: continue # 从文本库中搜索对应id的文本 doc = self.docstore.search(_id) - 对上面得到的文档做进一步的处理,比如检查是否为Document类型,如果是,则
# 将文本添加到docs列表中
docs.append(doc)
continue# 将文本id添加到id_set集合中,相当于更新文本id列表了
再之后,根据doc.metadata决定是否需要扩展搜索到的文本内容:根据context_expand_method的取值决定是向前扩展,还是向后扩展,或向前向后同时扩展(这样的操作通常用于搜索或检索任务中,当希望除了当前的匹配结果外,还获取其前后的一些相关内容)
id_set.add(i)# 如果不需要拆分块内容,或者文档的元数据中没有context_expand字段,或者context_expand字段的值为false,则执行以下代码 if (not self.chunk_conent) or ("context_expand" in doc.metadata and not doc.metadata["context_expand"]): # 匹配出的文本如果不需要扩展上下文则执行如下代码 # 如果搜索到的文本不是Document类型,则抛出异常 if not isinstance(doc, Document): raise ValueError(f"Could not find document for id {_id}, got {doc}") # 在文本的元数据中添加score字段,其值为找到的分数 doc.metadata["score"] = int(scores[0][j]) # 将文本添加到docs列表中 docs.append(doc) continue # 将文本id添加到id_set集合中 id_set.add(i) # 获取文本的长度 docs_len = len(doc.page_content) # 遍历范围在1到i和store_len - i之间的数字k for k in range(1, max(i, store_len - i)): # 初始化一个布尔变量,表示是否需要跳出循环 break_flag = False # 如果文本的元数据中有context_expand_method字段,并且其值为"forward",则扩展范围设置为[i + k] if "context_expand_method" in doc.metadata and doc.metadata["context_expand_method"] == "forward": expand_range = [i + k] # 如果文本的元数据中有context_expand_method字段,并且其值为"backward",则扩展范围设置为[i - k] elif "context_expand_method" in doc.metadata and doc.metadata["context_expand_method"] == "backward": expand_range = [i - k] # 如果文本的元数据中没有context_expand_method字段,或者context_expand_method字段的值不是"forward"也不是"backward",则扩展范围设置为[i + k, i - k] else: expand_range = [i + k, i - k] - 对扩展内容的处理
对于需要扩展其内容的文档,代码将其内容与前后的文档内容合并,直到满足一定的条件(例如,总长度最好不要超过chunk_size,或者合并的文档来源尽可能相同)# 遍历扩展范围 for l in expand_range: # 如果l不在id_set集合中,并且l在0到len(self.index_to_docstore_id)之间,则执行以下代码 if l not in id_set and 0 <= l < len(self.index_to_docstore_id): # 获取l对应的文本id _id0 = self.index_to_docstore_id[l] # 从文本库中搜索对应id的文本 doc0 = self.docstore.search(_id0) # 如果文本长度加上新文档的长度大于块大小,或者新文本的源不等于当前文本的源,则设置break_flag为true,跳出循环 if docs_len + len(doc0.page_content) > self.chunk_size or doc0.metadata["source"] != \ doc.metadata["source"]: break_flag = True break # 如果新文本的源等于当前文本的源,则将新文本的长度添加到文本长度上,将l添加到id_set集合中,设置rearrange_id_list为true elif doc0.metadata["source"] == doc.metadata["source"]: docs_len += len(doc0.page_content) id_set.add(l) rearrange_id_list = True # 如果break_flag为true,则跳出循环 if break_flag: break - 如果对文档内容进行了扩展,则需要重新整理ID列表
然后对扩展内容文本的ID到index_to_docstore_id中查询
如果在,则从文档库中搜索到对应ID的文本,然后深度拷贝出来
否则,则从文本库中搜索对应id的文档,将新文本的内容添加到当前文本的内容后面# 如果不需要拆分块内容,或者不需要重新排列id列表,则返回docs列表 if (not self.chunk_conent) or (not rearrange_id_list): return docs # 如果id_set集合的长度为0,并且分数阈值大于0,则返回空列表 if len(id_set) == 0 and self.score_threshold > 0: return [] # 对id_set集合中的元素进行排序,并转换为列表 id_list = sorted(list(id_set)) # 调用seperate_list函数,将id_list分解成多个子列表 id_lists = self.seperate_list(id_list) # 遍历id_lists中的每一个id序列 for id_seq in id_lists: # 遍历id序列中的每一个id for id in id_seq: # 如果id等于id序列的第一个元素,则从文档库中搜索对应id的文本,并深度拷贝这个文本 if id == id_seq[0]: _id = self.index_to_docstore_id[id] # doc = self.docstore.search(_id) doc = copy.deepcopy(self.docstore.search(_id)) # 如果id不等于id序列的第一个元素,则从文本库中搜索对应id的文档,将新文本的内容添加到当前文本的内容后面 else: _id0 = self.index_to_docstore_id[id] doc0 = self.docstore.search(_id0) doc.page_content += " " + doc0.page_content # 如果搜索到的文本不是Document类型,则抛出异常 if not isinstance(doc, Document): raise ValueError(f"Could not find document for id {_id}, got {doc}") # 计算文本的分数,分数等于id序列中的每一个id在分数列表中对应的分数的最小值 doc_score = min([scores[0][id] for id in [indices[0].tolist().index(i) for i in id_seq if i in indices[0]]]) # 在文本的元数据中添加score字段,其值为文档的分数 doc.metadata["score"] = int(doc_score) # 将文本添加到docs列表中 docs.append(doc) # 返回docs列表 return docs
3.8.4 delete_doc方法:删除文本库中指定来源的文本
#定义了一个名为 delete_doc 的方法,这个方法用于删除文本库中指定来源的文本
def delete_doc(self, source: str or List[str]):
# 使用 try-except 结构捕获可能出现的异常
try:
# 如果 source 是字符串类型
if isinstance(source, str):
# 找出文本库中所有来源等于 source 的文本的id
ids = [k for k, v in self.docstore._dict.items() if v.metadata["source"] == source]
# 获取向量存储的路径
vs_path = os.path.join(os.path.split(os.path.split(source)[0])[0], "vector_store")
# 如果 source 是列表类型
else:
# 找出文本库中所有来源在 source 列表中的文本的id
ids = [k for k, v in self.docstore._dict.items() if v.metadata["source"] in source]
# 获取向量存储的路径
vs_path = os.path.join(os.path.split(os.path.split(source[0])[0])[0], "vector_store")
# 如果没有找到要删除的文本,返回失败信息
if len(ids) == 0:
return f"docs delete fail"
# 如果找到了要删除的文本
else:
# 遍历所有要删除的文本id
for id in ids:
# 获取该id在索引中的位置
index = list(self.index_to_docstore_id.keys())[list(self.index_to_docstore_id.values()).index(id)]
# 从索引中删除该id
self.index_to_docstore_id.pop(index)
# 从文本库中删除该id对应的文本
self.docstore._dict.pop(id)
# TODO: 从 self.index 中删除对应id,这是一个未完成的任务
# self.index.reset()
# 保存当前状态到本地
self.save_local(vs_path)
# 返回删除成功的信息
return f"docs delete success"
# 捕获异常
except Exception as e:
# 打印异常信息
print(e)
# 返回删除失败的信息
return f"docs delete fail"3.8.5 update_doc和lists_doc
# 定义了一个名为 update_doc 的方法,这个方法用于更新文档库中的文档
def update_doc(self, source, new_docs):
# 使用 try-except 结构捕获可能出现的异常
try:
# 删除旧的文档
delete_len = self.delete_doc(source)
# 添加新的文档
ls = self.add_documents(new_docs)
# 返回更新成功的信息
return f"docs update success"
# 捕获异常
except Exception as e:
# 打印异常信息
print(e)
# 返回更新失败的信息
return f"docs update fail"
# 定义了一个名为 list_docs 的方法,这个方法用于列出文档库中所有文档的来源
def list_docs(self):
# 遍历文档库中的所有文档,取出每个文档的来源,转换为集合,再转换为列表,最后返回这个列表
return list(set(v.metadata["source"] for v in self.docstore._dict.values()))第四部分 23年9月升级版Langchain-Chatchat的源码解析
23年9月,原项目LangChain + ChatGLM-6B做了升级,变成如今的Langchain-Chatchat项目
其主要更新体现在增加了一个sever的文件夹,该文件夹包括
-
chat,包含
__init__.py
chat.py
knowledge_base_chat.py
openai_chat.py
search_engine_chat.py
utils.py -
db,包含
models
__init__.py
base.py
knowledge_base_model.py (即KnowledgeBaseModel的实现,下文4.2.1节阐述)
knowledge_file_model.py (即KnowledgeFile的实现,下文4.2.2节阐述)
repository
__init__.py
knowledge_base_repository.py (涉及add_kb_to_db的实现,下文4.3.1节阐述)
knowledge_file_repository.py (涉及add_flie_to_db/add_docs_to_db的实现,下文4.3.2节阐述) -
knowledge_base,包含
kb_cache
base.py (涉及KBServiceFactory的实现,下文4.1.2节阐述)
faiss_cache.py
kb_service
__init__.py
base.py
default_kb_service.py
faiss_kb_service.py
milvus_kb_service.py
pg_kb_service.py
__init__.py
kb_api.py
kb_doc_api.py (这个实现了多文档问答的最核心逻辑,下文4.1.1节阐述)
migrate.py
utils.py - model_workers
- static
等分文件夹
4.1 server/knowledge_base:基于批量文档的企业知识库问答
该项目的最新版中实现了基于批量文档的问答,比如
# 开始遍历自定义的文档集合(docs)
for file_name, v in docs.items():
try:
# 对于v中的每个条目,检查它是否已经是Document类型
# 如果不是,那么将其转换为Document对象
v = [x if isinstance(x, Document) else Document(**x) for x in v]
# 根据文件名和知识库名称创建KnowledgeFile对象
kb_file = KnowledgeFile(filename=file_name, knowledge_base_name=knowledge_base_name)
# 在知识库中更新该文件的文档
kb.update_doc(kb_file, docs=v, not_refresh_vs_cache=True)
# ...4.1.1 knowledge_base /kb_doc_api.py
以下是对该项目文件的逐行分析:Langchain-Chatchat/server/knowledge_base /kb_doc_api.py
-
导入模块:
- 导入了一些标准库,如
os和urllib,分别用于操作系统操作和URL解析 - 导入
fastapi相关的模块,这是一个现代、高速的 web 框架,用于构建 API - 导入自定义的模块和配置,如模型配置和知识库的工具函数
- 导入了一些标准库,如
-
DocumentWithScore类:
- 这是一个继承自
Document类的子类,增加了一个score字段。这很可能是在文档搜索时返回搜索相关度得分的一个数据结构
- 这是一个继承自
-
search_docs函数:
- 这个函数用于搜索知识库中的文档。
- 它接受查询字符串、知识库名称、最大返回文档数量和评分阈值作为参数。
- 使用
KBServiceFactory来获取对应的知识库服务,然后在该知识库中搜索文档。 - 返回搜索到的与查询相关的文档列表,每个文档都带有一个相关度得分
# 定义一个用于搜索文档的函数 def search_docs(query: str = Body(..., description="用户输入", examples=["你好"]), knowledge_base_name: str = Body(..., description="知识库名称", examples=["samples"]), top_k: int = Body(VECTOR_SEARCH_TOP_K, description="匹配向量数"), score_threshold: float = Body(SCORE_THRESHOLD, description="知识库匹配相关度阈值,取值范围在0-1之间,SCORE越小,相关度越高,取到1相当于不筛选,建议设置在0.5左右", ge=0, le=1), ) -> List[DocumentWithScore]: # 根据知识库名称获取相应的知识库服务实例 kb = KBServiceFactory.get_service_by_name(knowledge_base_name) # 如果没有找到对应的知识库服务实例,返回空列表 if kb is None: return [] # 调用知识库服务的search_docs方法来搜索与查询字符串匹配的文档 docs = kb.search_docs(query, top_k, score_threshold) # 将搜索到的文档转换为DocumentWithScore对象,包括文档内容和匹配分数 data = [DocumentWithScore(**x[0].dict(), score=x[1]) for x in docs] # 返回带分数的匹配文档列表 return data总之,这个search_docs函数是为了在给定的知识库中搜索与查询字符串匹配的文档,并返回最相关的top_k个文档及其匹配分数
-
list_files函数
- 用于列出指定知识库中的所有文件。
- 先进行知识库名称的验证,然后使用
KBServiceFactory来获取对应的知识库服务。 - 如果知识库存在,它将返回知识库中所有的文档名称。
-
_save_files_in_thread函数
- 这是一个私有函数,用于在后台线程中保存上传的文件到指定的知识库。
- 它的内部定义了一个
save_file函数,用于保存单个文件。 - 如果文件已存在,并且用户没有选择覆盖,它将检查文件大小并返回一个消息,说明文件已存在。
- 否则,它将写入文件内容。
- 在这个函数的结尾,使用
run_in_thread_pool方法在多线程环境中执行文件保存操作,并返回每个文件的保存结果
-
upload_docs 函数
- 目的:上传文档,并进行选择性的向量化。
- 输入:
- 一系列的文件、知识库名称、文件处理参数等。
- 主要功能:
- 验证知识库名称的有效性。
- 将上传的文件保存到磁盘。
- 对保存的文件进行向量化。
- 输出:一个基础响应,指示操作是否成功和失败文件的列表
下面也定义了一个upload_docs函数,区别在于,此处upload_docs是定义在类 KnowledgeBase 中
函数内部调用self.kb_service.upload_docs(docs),意味着它在某种程度上是一个代理方法,将上传任务交给kb_service来完成
相当于为了在KnowledgeBase类的上下文中提供一个简化的上传接口。它可能是为了在某种上下文或配置中使用kb_service来上传文档
而下面的第二个upload_docs函数可能是实际处理文档上传和向量化任务的函数。在实际的应用场景中,KnowledgeBase类的方法可能会调用下面的第二个upload_docs函数来执行实际的上传操作
-
delete_docs 函数
- 目的:从知识库中删除指定的文件。
- 输入:
- 知识库名称、待删除的文件名列表和其他处理参数。
- 主要功能:
- 验证知识库名称的有效性。
- 删除知识库中指定的文件。
- 输出:一个基础响应,指示操作是否成功和失败文件的列表。
-
update_docs函数- 目的:更新知识库中的文档。
- 输入:
- 知识库名称、待更新的文件名列表和其他处理参数。
- 主要功能:
- 从文件生成文档并进行向量化
- 更新知识库中的指定文件,即将文件添加到知识库文件列表中
- 输出:一个基础响应,指示操作是否成功和失败文件的列表
其中的KBServiceFactory和KnowledgeFile将分别在下文的:“4.1.2 KBServiceFactory的实现:knowledge_base/kb_service/base.py”和“4.2.2 KnowledgeFile的实现”中介绍
def update_docs( knowledge_base_name: str = Body(..., description="知识库名称", examples=["samples"]), file_names: List[str] = Body(..., description="文件名称,支持多文件", examples=["file_name"]), chunk_size: int = Body(CHUNK_SIZE, description="知识库中单段文本最大长度"), chunk_overlap: int = Body(OVERLAP_SIZE, description="知识库中相邻文本重合长度"), zh_title_enhance: bool = Body(ZH_TITLE_ENHANCE, description="是否开启中文标题加强"), override_custom_docs: bool = Body(False, description="是否覆盖之前自定义的docs"), docs: Json = Body({}, description="自定义的docs", examples=[{"test.txt": [Document(page_content="custom doc")]}]), not_refresh_vs_cache: bool = Body(False, description="暂不保存向量库(用于FAISS)") ) -> BaseResponse: ''' 更新知识库文档 ''' # 验证知识库名称 if not validate_kb_name(knowledge_base_name): return BaseResponse(code=403, msg="Don't attack me") # 获取知识库服务 kb = KBServiceFactory.get_service_by_name(knowledge_base_name) if kb is None: return BaseResponse(code=404, msg=f"未找到知识库 {knowledge_base_name}") failed_files = {} kb_files = [] # 生成需要加载docs的文件列表 for file_name in file_names: # 获取文件详情 file_detail = get_file_detail(kb_name=knowledge_base_name, filename=file_name) # 如果该文件之前使用了自定义docs,则根据参数决定略过或覆盖 if file_detail.get("custom_docs") and not override_custom_docs: continue if file_name not in docs: try: # 将文件名和知识库名组合为一个KnowledgeFile对象,并添加到kb_files列表中 kb_files.append(KnowledgeFile(filename=file_name, knowledge_base_name=knowledge_base_name)) except Exception as e: # 记录失败的文件和错误信息 msg = f"加载文档 {file_name} 时出错:{e}" logger.error(f'{e.__class__.__name__}: {msg}', exc_info=e if log_verbose else None) failed_files[file_name] = msg # 从文件生成docs,并进行向量化 for status, result in files2docs_in_thread(kb_files, chunk_size=chunk_size, chunk_overlap=chunk_overlap, zh_title_enhance=zh_title_enhance): if status: # 成功处理文件后,更新知识库中的文档 kb_name, file_name, new_docs = result kb_file = KnowledgeFile(filename=file_name, knowledge_base_name=knowledge_base_name) kb_file.splited_docs = new_docs kb.update_doc(kb_file, not_refresh_vs_cache=True) else: # 记录失败的文件和错误信息 kb_name, file_name, error = result failed_files[file_name] = error # 将自定义的docs进行向量化 for file_name, v in docs.items(): try: # 对于v中的每个条目,检查它是否已经是Document类型 # 如果不是,那么将其转换为Document对象 v = [x if isinstance(x, Document) else Document(**x) for x in v] # 根据文件名和知识库名称创建KnowledgeFile对象 kb_file = KnowledgeFile(filename=file_name, knowledge_base_name=knowledge_base_name) # 在知识库中更新该文件的文档 kb.update_doc(kb_file, docs=v, not_refresh_vs_cache=True) except Exception as e: # 当遇到异常时,构建一个错误消息并使用logger进行记录 msg = f"为 {file_name} 添加自定义docs时出错:{e}" logger.error(f'{e.__class__.__name__}: {msg}', exc_info=e if log_verbose else None) failed_files[file_name] = msg # 如果需要刷新向量库,则进行保存 if not not_refresh_vs_cache: kb.save_vector_store() # 返回响应,包括失败文件列表 return BaseResponse(code=200, msg=f"更新文档完成", data={"failed_files": failed_files})
-
download_doc 函数
- 目的:从知识库中下载指定的文档。
- 输入:
- 知识库名称、待下载的文件名和其他参数。
- 主要功能:
- 提供文件预览或下载功能。
- 输出:一个文件响应,允许用户下载或预览文件。
-
recreate_vector_store 函数
- 目的:从内容重建向量存储。
- 输入:
- 知识库名称、向量存储类型和其他处理参数。
- 主要功能:
- 清除现有的向量存储。
- 从文件夹中列出文件。
- 为每个文件生成文档并加入到知识库中。
- 输出:一个流响应,用于实时更新操作进度
总体来说,这段代码主要为知识库文档提供了CRUD操作(创建、读取、更新、删除)及相关的向量化处理
4.1.2 KBServiceFactory的实现:knowledge_base/kb_service/base.py
-
导入模块:
- 基本的Python库如os, operator。
- 用于数据操作和向量化的库如numpy, sklearn。
- 项目内部的模块如langchain.embeddings.base, langchain.docstore.document等。
-
SupportedVSType 类:
- 这是一个简单的类,用于定义支持的向量存储类型。例如:FAISS, MILVUS等。
-
KBService 类:
- 这是一个抽象基类,定义了知识库服务的基本功能和行为。
- 初始化函数:给定一个知识库名和嵌入模型名称,进行初始化。
- 提供了一系列方法,如
create_kb (创建知识库)其中的add_kb_to_db将在下文的“4.3.1 knowledge_base_repository.py:实现add_kb_to_db”中分析# 创建知识库方法 def create_kb(self): # 检查doc_path路径是否存在 if not os.path.exists(self.doc_path): # 如果不存在,创建该目录 os.makedirs(self.doc_path) # 调用子类中定义的do_create_kb方法来执行具体的知识库创建过程 self.do_create_kb() # 将新的知识库添加到数据库中,并返回操作状态 status = add_kb_to_db(self.kb_name, self.vs_type(), self.embed_model) # 返回操作状态 return status
add_doc (向知识库添加文件)其中add_file_to_db将在下文的“4.3.2 knowledge_file_repository.py:实现add_file_to_db/add_docs_to_db”中分析# 向知识库添加文件方法 def add_doc(self, kb_file: KnowledgeFile, docs: List[Document] = [], **kwargs): # 判断docs列表是否有内容 if docs: # 设置一个标志,表示这是自定义文档列表 custom_docs = True # 遍历传入的文档列表 for doc in docs: # 为每个文档的metadata设置默认的"source"属性,值为文件的路径 doc.metadata.setdefault("source", kb_file.filepath) else: # 如果没有提供docs,从kb_file中读取文档内容 docs = kb_file.file2text() # 设置一个标志,表示这不是自定义文档列表 custom_docs = False # 如果docs列表有内容 if docs: # 删除与kb_file相关联的现有文档 self.delete_doc(kb_file) # 调用子类中定义的do_add_doc方法来执行具体的文档添加过程,并返回文档信息 doc_infos = self.do_add_doc(docs, **kwargs) # 将新的文档信息添加到数据库中,并返回操作状态 status = add_file_to_db(kb_file, custom_docs=custom_docs, docs_count=len(docs), doc_infos=doc_infos) else: # 如果docs列表为空,则设置操作状态为False status = False # 返回操作状态 return status - 还有一些抽象方法,如do_create_kb、do_search等,子类必须实现这些方法
-
KBServiceFactory 类:
- 这是一个工厂类,根据提供的向量存储类型返回相应的知识库服务实例
- 使用静态方法获取不同的知识库服务实例
# 知识库服务工厂类 class KBServiceFactory: # 根据向量存储类型返回相应的知识库服务实例 @staticmethod def get_instance(vs_type: str, knowledge_base_name: str) -> KBService: if vs_type == SupportedVSType.FAISS: from server.knowledge_base.kb_faiss import KBServiceFaiss return KBServiceFaiss(knowledge_base_name) elif vs_type == SupportedVSType.MILVUS: from server.knowledge_base.kb_milvus import KBServiceMilvus return KBServiceMilvus(knowledge_base_name) else: raise ValueError(f"Unsupported VS type: {vs_type}")
-
get_kb_details 函数:
- 获取目录和数据库中的所有知识库的详细信息,并将这些信息合并
-
get_kb_file_details 函数:
- 为指定的知识库获取目录和数据库中的所有文件的详细信息,并将这些信息合并。
-
EmbeddingsFunAdapter 类:
- 这是一个适配器类,用于在Embeddings类上添加额外的功能。
- embed_documents 和 embed_query 方法对输入的文本进行嵌入,并将结果进行标准化。
- aembed_documents 和 aembed_query 是它们的异步版本。
-
score_threshold_process 函数:
- 这是一个简单的函数,用于在得分低于某个阈值的情况下筛选文档,并返回前k个文档
4.2 server/db/models文件夹的更新
4.2.1 KnowledgeBaseModel的实现
server/db/models/knowledge_base_model.py中实现了
from sqlalchemy import Column, Integer, String, DateTime, func
from server.db.base import Base
class KnowledgeBaseModel(Base):
"""
知识库模型
"""
__tablename__ = 'knowledge_base'
id = Column(Integer, primary_key=True, autoincrement=True, comment='知识库ID')
kb_name = Column(String(50), comment='知识库名称')
vs_type = Column(String(50), comment='向量库类型')
embed_model = Column(String(50), comment='嵌入模型名称')
file_count = Column(Integer, default=0, comment='文件数量')
create_time = Column(DateTime, default=func.now(), comment='创建时间')
def __repr__(self):
return f"<KnowledgeBase(id='{self.id}', kb_name='{self.kb_name}', vs_type='{self.vs_type}', embed_model='{self.embed_model}', file_count='{self.file_count}', create_time='{self.create_time}')>"4.2.2 KnowledgeFile的实现
经过仔细查找发现,在server/db/models /knowledge_file_model.py项目文件中实现了KnowledgeFile
# 导入sqlalchemy所需的模块和函数
from sqlalchemy import Column, Integer, String, DateTime, Float, Boolean, JSON, func
# 从server.db.base导入Base类,这通常用于ORM的基础模型
from server.db.base import Base
# 定义KnowledgeFileModel类,用于映射“知识文件”数据模型
class KnowledgeFileModel(Base):
"""
知识文件模型
"""
__tablename__ = 'knowledge_file'
id = Column(Integer, primary_key=True, autoincrement=True, comment='知识文件ID')
file_name = Column(String(255), comment='文件名')
file_ext = Column(String(10), comment='文件扩展名')
kb_name = Column(String(50), comment='所属知识库名称')
document_loader_name = Column(String(50), comment='文档加载器名称')
text_splitter_name = Column(String(50), comment='文本分割器名称')
file_version = Column(Integer, default=1, comment='文件版本')
file_mtime = Column(Float, default=0.0, comment="文件修改时间")
file_size = Column(Integer, default=0, comment="文件大小")
custom_docs = Column(Boolean, default=False, comment="是否自定义docs")
docs_count = Column(Integer, default=0, comment="切分文档数量")
create_time = Column(DateTime, default=func.now(), comment='创建时间')
# 定义对象的字符串表示形式
def __repr__(self):
return f"<KnowledgeFile(id='{self.id}', file_name='{self.file_name}',
file_ext='{self.file_ext}', kb_name='{self.kb_name}',
document_loader_name='{self.document_loader_name}',
text_splitter_name='{self.text_splitter_name}',
file_version='{self.file_version}', create_time='{self.create_time}')>"
# 定义FileDocModel类,用于映射“文件-向量库文档”数据模型
class FileDocModel(Base):
"""
文件-向量库文档模型
"""
# 定义表名为'file_doc'
__tablename__ = 'file_doc'
# 定义id字段为主键,并设置自动递增,并且附加注释
id = Column(Integer, primary_key=True, autoincrement=True, comment='ID')
# 定义知识库名称字段,并附加注释
kb_name = Column(String(50), comment='知识库名称')
# 定义文件名称字段,并附加注释
file_name = Column(String(255), comment='文件名称')
# 定义向量库文档ID字段,并附加注释
doc_id = Column(String(50), comment="向量库文档ID")
# 定义元数据字段,默认为一个空字典
meta_data = Column(JSON, default={})
# 定义对象的字符串表示形式
def __repr__(self):
return f"<FileDoc(id='{self.id}', kb_name='{self.kb_name}', file_name='{self.file_name}', doc_id='{self.doc_id}', metadata='{self.metadata}')>"
4.3 server/db/repository
4.3.1 knowledge_base_repository.py:实现add_kb_to_db
def add_kb_to_db(session, kb_name, vs_type, embed_model):
# 查询指定名称的知识库是否存在于数据库中
kb = session.query(KnowledgeBaseModel).filter_by(kb_name=kb_name).first()
# 如果指定的知识库不存在,则创建一个新的知识库实例
if not kb:
kb = KnowledgeBaseModel(kb_name=kb_name, vs_type=vs_type, embed_model=embed_model)
# 将新的知识库实例添加到session,这样可以在之后提交到数据库
session.add(kb)
else: # 如果知识库已经存在,则更新它的vs_type和embed_model
kb.vs_type = vs_type
kb.embed_model = embed_model
# 返回True,表示操作成功完成
return True至于其中的KnowledgeBaseModel方法,已经在上文的“4.2.1 KnowledgeBaseModel的实现”中分析了
4.3.2 knowledge_file_repository.py:实现add_file_to_db/add_docs_to_db
- add_file_to_db,将添加文件到数据库,最后会调用add_docs_to_db
- add_docs_to_db,将文档添加到数据库
# 定义向数据库添加文件的函数
def add_file_to_db(session, # 数据库会话对象
kb_file: KnowledgeFile, # 知识文件对象
docs_count: int = 0, # 文档数量,默认为0
custom_docs: bool = False, # 是否为自定义文档,默认为False
doc_infos: List[str] = [], # 文档信息列表,默认为空。形式为:[{"id": str, "metadata": dict}, ...]
):
# 从数据库中查询与知识库名相匹配的知识库记录
kb = session.query(KnowledgeBaseModel).filter_by(kb_name=kb_file.kb_name).first()
# 如果该知识库存在
if kb:
# 查询与文件名和知识库名相匹配的文件记录
existing_file: KnowledgeFileModel = (session.query(KnowledgeFileModel)
.filter_by(file_name=kb_file.filename,
kb_name=kb_file.kb_name)
.first())
# 获取文件的修改时间
mtime = kb_file.get_mtime()
# 获取文件的大小
size = kb_file.get_size()
# 如果该文件已存在
if existing_file:
# 更新文件的修改时间
existing_file.file_mtime = mtime
# 更新文件的大小
existing_file.file_size = size
# 更新文档数量
existing_file.docs_count = docs_count
# 更新自定义文档标志
existing_file.custom_docs = custom_docs
# 文件版本号自增
existing_file.file_version += 1
# 如果文件不存在
else:
# 创建一个新的文件记录对象
new_file = KnowledgeFileModel(
file_name=kb_file.filename,
file_ext=kb_file.ext,
kb_name=kb_file.kb_name,
document_loader_name=kb_file.document_loader_name,
text_splitter_name=kb_file.text_splitter_name or "SpacyTextSplitter",
file_mtime=mtime,
file_size=size,
docs_count = docs_count,
custom_docs=custom_docs,
)
# 知识库的文件计数增加
kb.file_count += 1
# 将新文件添加到数据库会话中
session.add(new_file)
# 添加文档到数据库
add_docs_to_db(kb_name=kb_file.kb_name, file_name=kb_file.filename, doc_infos=doc_infos)
# 返回True表示操作成功
return True通过查看上面的倒数第二行代码可知,add_file_to_db最后调用add_docs_to_db以实现添加文档到数据库
def add_docs_to_db(session,
kb_name: str,
file_name: str,
doc_infos: List[Dict]):
'''
将某知识库某文件对应的所有Document信息添加到数据库
doc_infos形式:[{"id": str, "metadata": dict}, ...]
'''
for d in doc_infos:
obj = FileDocModel(
kb_name=kb_name,
file_name=file_name,
doc_id=d["id"],
meta_data=d["metadata"],
)
session.add(obj)
return True更多暂先课上见:七月LLM与langchain/知识图谱/数据库的实战 [解决问题、实用为王],再之后继续更新本文
第五部分 langchain-chatchat的二次开发:商用时的典型问题及其改进方案
上述这个langchain-chatchat开源项目虽好,但真正落地商用时,会遇到各种工程问题,包括且不限于
- 如何解决检索出错:embedding算法是关键
- 如何解决检索对了但不根据知识库回答而是根据模型自有的预训练知识回答
- 如何针对结构化文档采取更好的chunk分割:基于规则
- 如何解决非结构化文档分割不够准确的问题:比如最好按照语义切分
- 如何确保召回结果的全面性与准确性:多路召回与最后的去重/精排
- 如何解决基于文档中表格的问答
- ..
以上内容,请详见《知识库问答Langchain-Chatchat的二次开发:商用时的典型问题及其改进方案》文章来源:https://www.toymoban.com/news/detail-659646.html
参考文献与推荐阅读
- langchain官网:LangChain、https://python.langchain.com/,API列表:https://api.python.langchain.com/en/latest/api_reference.html
langchain中文网(翻译暂不佳) - LangChain全景图
- 一文搞懂langchain(忽略本标题,因为单看此文还不够)
- How to Build a Smart Chatbot in 10 mins with LangChain
- 关于FAISS的几篇教程:Faiss入门及应用经验记录
- QLoRA:4-bit级别的量化+LoRA方法,用3090在DB-GPT上打造基于33B LLM的个人知识库
- 基于LangChain+LLM构建增强QA、用LangChain构建大语言模型应用、LangChain 是什么
- 深入剖析开源大模型+Langchain框架智能问答系统性能下降原因
- 七月LLM与langchain/知识图谱/数据库的实战 [解决问题、实用为王]
- 深入剖析开源大模型+Langchain框架智能问答系统性能下降原因
后记
本文经历了三个阶段文章来源地址https://www.toymoban.com/news/detail-659646.html
- 对langchain的梳理
langchain的组件很多,想理解透彻的话,需要一步步来
包括我自己刚开始看这个库的时候 真心是晕,无从下手,后来10天过后,可以直接一个文件一个文件的点开 直接看..
总之,凡事都是一个过程 - 对langchain-ChatGLM项目源码的解读
说实话,一开始也是挺晕的,因为各种项目文件又很多,好在后来历时一周总算梳理清楚了 - 开写新的:第四部分 23年9月升级版Langchain-Chatchat的源码解析
创作、修改、优化记录
- 7.5-7.9日,每天写一一部分
- 7.10,完善第一部分关于什么是langchain的介绍
- 7.11,根据langchain-ChatGLM项目的最新更新,整理已写内容
- 7.12 写完前3.8节,且根据项目流程调整各个文件夹的解读顺序
相当于历时近一周,总算把 “langchain-ChatGLM的整体代码架构” 梳理清楚了 - 7.15,补充langchain架构相关的内容,且为方便理解,把整个langchain库划分为三个大层:基础层、能力层、应用层
- 7.17,开始写第四部分,重点是4.2节:用知识图谱增强 LLM的预训练、推理、可解释性
- 7.26,续写第四部分,开始更新第五部分:LLM与数据库的结合
- 9.15,把原来的第四部分、第五部分抽取出来独立成一篇新的文章:知识图谱通俗导论:从什么是KG到LLM与KG/DB的结合实战
- 9.16,开写新的:第四部分 23年9月升级版Langchain-Chatchat的源码解析
- 10.26,补充针对“faiss库的search函数”的细致说明及代码实现,这点对理解查找K个相似的向量等相关流程很重要
- 11.8,因得知好几个大厂的AI部门在密切关注本文的更新进度,故更新了二次开发时遇到的几个问题作为示例
- 12.27,补充为何要进行切割的原因,以及补充一个 embedding 的 benchmark
到了这里,关于从LangChain+LLM的本地知识库问答到LLM与知识图谱、数据库的结合的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!