一、scala抽象类和java的有何不同?
在org/apache/spark/util/collection/SortDataFormat.scala中有以下抽象类
private[spark] abstract class SortDataFormat[K, Buffer] {...}
然后在org/apache/spark/graphx/Edge.scala中,直接调用了xxx = new SortDataFormat[Edge[ED], Array[Edge[ED]]] {...}
为啥可以直接new一个抽象类呢??scala的抽象类和java的确实有区别。scala中不需要像java那样必须继承抽象类得到子类,而是直接new,然后在{}内override所有抽象方法,即给出抽象方法的具体实现即可!!!本质上是创建了匿名子类!!!属于语法糖
参考 https://qa.1r1g.com/sf/ask/683363691/ (scala:抽象类实例化?)
二、scala泛型类、泛型函数和java的有何不同?
没太大区别,主要是符号的不同,从<x,y>变为[x,y]。
比如Map[String,Int]、Graph[Int, ED]就是泛型类。
比如org/apache/spark/graphx/lib/TriangleCount.scala中的
def run[VD: ClassTag, ED: ClassTag](graph: Graph[VD, ED]): Graph[Int, ED] = { 以及
def runPreCanonicalized[VD: ClassTag, ED: ClassTag](graph: Graph[VD, ED]): Graph[Int, ED] = {
都是泛型函数。[x,y]加在方法名后面!!!
三、scala的class和object可以在同一文件?
可以,无论case class、普通class、abstract class,都可以;
一个scala文件可以有多个class和多个object!scala默认就是public(即class前面不加东西,就表示public)对外的是哪个class和哪个object??都是(不像java只能有一个public)。比如SVM.scala就包括SVMModel的class和object,以及SVMWithSGD的class和object
提示:scala文件名也没有要求和某个class或object名字一样!?当然,也不可能一样,因为它可以包含多个class和object,和谁一样呢?这点也和java不同!!!
四、scala抽象类可以继承java接口?
如org/apache/spark/broadcast/Broadcast.scala中的
abstract class Broadcast[T: ClassTag](val id: Long) extends Serializable with Logging {
其中Serializable是java的接口。。其实是混入特质(Serializable with Logging),即java的接口被直接当做scala的特质!!!
五、柯里化和类型约束
org/apache/spark/graphx/Graph.scala中有如下代码:
def outerJoinVertices[U: ClassTag, VD2: ClassTag](other: RDD[(VertexId, U)])
(mapFunc: (VertexId, VD, Option[U]) => VD2)(implicit eq: VD =:= VD2 = null)
: Graph[VD2, ED]
这里涉及到两个知识点:柯里化和 =:=
其中=:=是类型约束,VD =:= VD2表示测试VD是否是VD2
注意:implicit eq: VD =:= VD2 = null 不是outerJoinVertices方法的第三个参数,而是类型证明对象,它证明VD的类型和VD2一样,是恒等函数,表示一个约束,也叫做自动隐式转换(注意:implicit后面只能有一个隐式值,比如这里是eq)
六、传名参数
在scala/Predef.scala中有以下代码:
@inline final def require(requirement: Boolean, message: => Any) {
问:message: => Any用到了啥语法?传名参数。另外,这个require方法类似于assert
传名参数的另一个例子是Option的getOrElse方法:
@inline final def getOrElse[B >: A](default: => B): B =
if (isEmpty) default else this.get
default: => B如何解读?default是变量,=> B是类型(具体是函数),而这个函数的输入为空(即省略了()),输出为B !
提示:其中的@inline用于建议编译器对方法做内联,而@noinline不要内联
七、包对象
org/apache/spark/graphx/package.scala中有如下代码:
package object graphx {
这是一个包对象!!!注意:package.scala事实上是graphx.scala
每个包都可以有一个包对象,即package object XXX
在幕后,包对象被编译为带有静态方法和字段的jvm类,如package.class
包对象的内容(如函数和变量)用于直接被包中定义的类等使用
(见快学scala 7.5节)
八、scala特质能否扩展抽象类
可以,比如scala/annotation/Annotation.scala是abstract class;
而scala/annotation/StaticAnnotation.scala是trait,具体是trait StaticAnnotation extends Annotation;可见特质比接口更强大
九、注解的使用
@param @field @getter @setter @beanGetter @beanSetter这些注解都定义在scala/annotation/meta/中,它们的一个用处是修饰org/apache/spark/annotation/Since.scala (定义在common/tags中),而@Since("1.1.0")可用来修饰class SVMModel等
十、this.type是什么
def setThreshold(threshold: Double): this.type = {
this.threshold = Some(threshold)
this
}//来自SVMModel
以上方法返回值为this.type,它表示当前类或对象的类型??是的,比如SVMModel
不写也许可以,但可能得到父类的类型,导致不能串接,见快学scala 18.1节(所以必须加)
思考:为啥Int和String无法调用.type?比如String.type得到error: identifier expected but 'type' found. 要加上type t=str.type前面的type t=才行!!!可以直接在REPL执行type T=Title.type,但不能直接Title.type !也不能用val或var!
十一、None和Some
scala的None是Option定义的,而非通用的,这点和python不同;
具体是case object None extends Option[Nothing];即None是Option的子类(或者说样例对象)
None和Some都可以给Option赋值。
提示:final case class Some[+A](@deprecatedName('x, "2.12.0") value: A) extends Option[A] {
即Some也是Option的子类
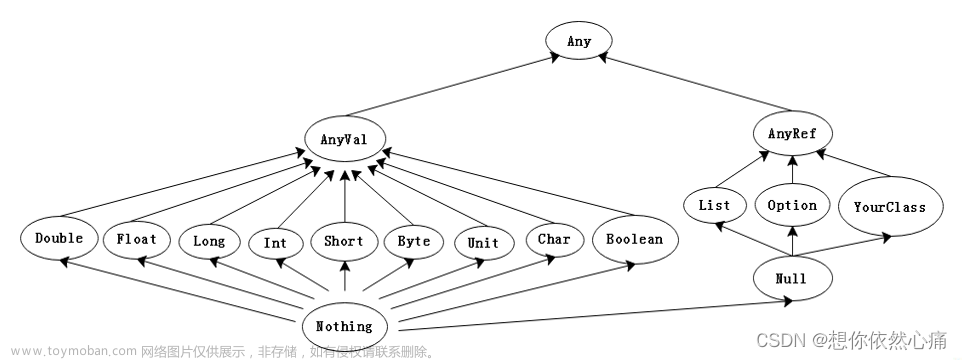
十二、scala中None、Null、null、Nil、Unit、()、Nothing区别
Nothing是所有类型的子类型。它没有实例。表示不正常的终止,被throw使用。(Nothing看不了源码,无法跳转!!)
Null是所有引用类型的子类型。Null的唯一实例是null。(Null和null也看不了源码,无法跳转!!)可以将null赋值给任何引用,但不能给值类型,比如Int设为null是错误的。
Nil是空列表。和List一起使用。具体是:case object Nil extends List[Nothing]
Unit等价于java的void。且它只有一个值,就是()。Unit没有子类!因为是final!!(但稍有区别,void是无值,Unit是有一个表示“无值”的值。)
思考1:Nothing是所有类型的子类型??那它也是Unit/Null的子类型??是的,不冲突,Nothing也是Int的子类型
思考2:scala有Void/void吗??没有,但可以直接用java.lang.Void !
十三、<:<和类型证明对象
@inline final def orNull[A1 >: A](implicit ev: Null <:< A1): A1 = this getOrElse ev(null)
这句如何解读?
1)<:<也是定义在Predef.scala中的sealed abstract class,具体含义是:
* An instance of `A <:< B` witnesses that `A` is a subtype of `B`.
* Requiring an implicit argument of the type `A <:< B` encodes
* the generalized constraint `A <: B`.
简单说,=:=, <:<, <%< 都是带有隐式值的类;都是类型证明对象!!!
为了检验一个泛型的隐式对象是否存在,可在REPL中调用如下,比如
implicitly[String<:<AnyRef] (得到<:<[String,AnyRef] = <function1>)
implicitly[Null<:<AnyRef] (得到<:<[Null,AnyRef] = <function1>)
=:=也定义在Predef.scala中!!也是一个sealed abstract class!
具体含义是:/** An instance of `A =:= B` witnesses that the types `A` and `B` are equal.
但似乎<%<不存在于Predef.scala!!!
注意一点:=:=, <:<, <%< 都不是scala语言的特性,而是scala库的特性!!!
(因此Predef.scala不属于scala语言而是scala库!?)
2)另外,this getOrElse ev(null)如何解读?和this.getOrElse(ev(null))等价!!!
十四、类型证明对象和隐式转换(深层含义)
再举一个例子
def firstLast[A,C](it:C)(implicit ev: C<:<Iterable[A]) = (it.head, it.last)
以上代码有两层含义:文章来源:https://www.toymoban.com/news/detail-659907.html
1. 在相应的伴生对象中,一定存在一个对象,可以被当做C<:<Iterable[A]的实例,它的存在证明了一个事实,即C是Iterable[A]的子类型(如果不存在,会编译报错!即@implicitNotFound(msg = "Cannot prove th文章来源地址https://www.toymoban.com/news/detail-659907.html
到了这里,关于spark源码的scala解析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!