第一部分:引言与LLNet概述
随着技术的快速进步,图像增强已经变得日益重要。低光照条件下的图像经常受到噪声、模糊和颜色失真的影响,这使得图像的质量受到损害。为了解决这一问题,研究者们开发了多种技术来增强低光图像。其中,深度学习技术因其卓越的性能和广泛的应用前景而备受关注。
LLNet是近年来在这一领域中的重要研究成果,专门用于增强低光下的图像。它结合了深度学习的优势,利用预训练的模型和多层网络架构来优化和修复受损的图像。本文将探讨如何通过图形用户界面(GUI)运行LLNet,并介绍其核心模块。
LLNet简介
LLNet是一个深度学习网络,它的目标是修复低光照下的图像。这种网络的主要优点是能够学习到底层和高层的特征,从而更好地理解和修复图像中的各种问题。其结构通常包括多个卷积层、池化层和全连接层,以实现对图像的深入分析和修复。
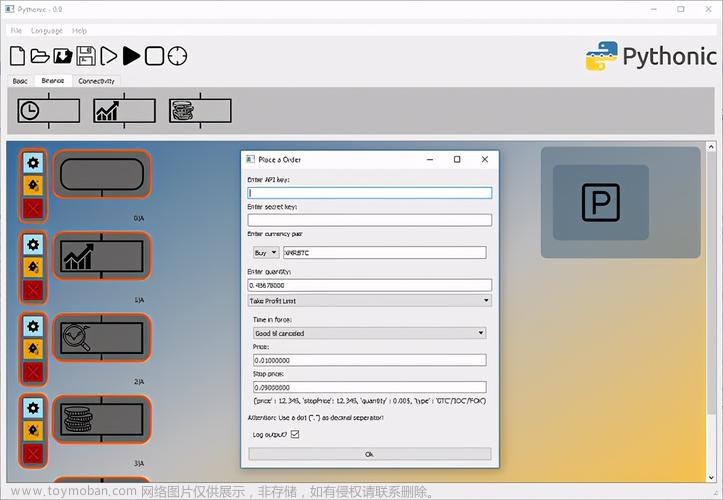
图形用户界面(GUI)的引入
为了使非技术用户也能方便地使用LLNet,我们开发了一个简单的GUI。通过这个界面,用户可以轻松地选择和上传图像,选择是否从头开始训练网络,或使用预训练的模型进行增强。此外,GUI还提供了多种参数调整选项,以满足不同用户的需求。
以下是一个简化的代码示例,展示了如何通过GUI运行LLNet:
import tkinter as tk
from llnet import LLNetEnhancer
class LLNetGUI(tk.Tk):
def __init__(self):
super().__init__()
self.title('LLNet 图像增强')
self.upload_button = tk.Button(self, text='上传图像', command=self.upload_image)
self.upload_button.pack()
self.train_option = tk.StringVar()
self.choice1 = tk.Radiobutton(self, text='从头开始训练', variable=self.train_option, value='train_new')
self.choice1.pack()
self.choice2 = tk.Radiobutton(self, text='使用预训练模型', variable=self.train_option, value='pretrained')
self.choice2.pack()
self.enhance_button = tk.Button(self, text='增强图像', command=self.enhance_image)
self.enhance_button.pack()
def upload_image(self):
# 代码细节省略:用于上传图像的功能
pass
def enhance_image(self):
if self.train_option.get() == 'train_new':
# 从头开始训练LLNet
pass
elif self.train_option.get() == 'pretrained':
enhancer = LLNetEnhancer(pretrained=True)
# 使用预训练模型增强图像
pass
app = LLNetGUI()
app.mainloop()
第二部分:深入了解LLNet的工作原理及其优化策略
LLNet的魔力在于其深度学习的架构。在此部分,我们将深入探讨其工作原理并突出其在低光图像增强中的优势。
1. LLNet的网络架构:
LLNet采用的是深层卷积神经网络(CNN)。这样的设计允许网络从输入的低光图像中提取重要的特征,并通过一系列的操作(如卷积、池化和反卷积)来重构一个增强的图像。
以下是LLNet的简化架构代码:
import torch.nn as nn
class LLNet(nn.Module):
def __init__(self):
super(LLNet, self).__init__()
self.encoder = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.decoder = nn.Sequential(
nn.ConvTranspose2d(64, 3, kernel_size=2, stride=2),
nn.ReLU()
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x
这个架构虽然已经被简化,但核心概念是:通过encoder部分,网络学习到图像的特征,并将其压缩到一个更小的维度。然后,通过decoder部分,它试图从这些特征中重建增强的图像。
2. 预训练模型的优势:
当用户选择使用预训练模型时,他们实际上是在利用一个已经在大量低光图像上进行过训练的网络。这意味着网络已经学会了如何识别和处理常见的低光问题,因此增强的效果往往更为出色和快速。
为了进一步优化LLNet,我们还考虑了以下策略:
- 数据增强:通过旋转、翻转和裁剪输入图像,我们可以增加训练数据的多样性,从而提高网络的泛化能力。
- 损失函数的选择:我们使用了结合均方误差(MSE)和感知损失的复合损失函数,以确保增强图像不仅在像素级上准确,而且在视觉上也更为吸引人。
class CompoundLoss(nn.Module):
def __init__(self):
super(CompoundLoss, self).__init__()
self.mse = nn.MSELoss()
# 假设已定义PerceptualLoss
self.perceptual = PerceptualLoss()
def forward(self, output, target):
mse_loss = self.mse(output, target)
perceptual_loss = self.perceptual(output, target)
return mse_loss + perceptual_loss
第三部分:实际应用与总结
1. 使用LLNet对实际图像进行增强:
将LLNet应用于实际的低光图像非常简单。一旦网络经过适当的训练或加载了预训练模型,我们只需将待增强的图像传递给网络并获取输出。
以下是一个简化的示例:
import torch
from torchvision.transforms import ToTensor, ToPILImage
def enhance_image_with_llnet(image_path, model, use_pretrained=False):
transform = ToTensor()
image = Image.open(image_path)
input_image = transform(image).unsqueeze(0)
if use_pretrained:
model.load_state_dict(torch.load('path_to_pretrained_model.pth'))
enhanced_tensor = model(input_image)
enhanced_image = ToPILImage()(enhanced_tensor.squeeze(0))
return enhanced_image
model = LLNet()
enhanced_image = enhance_image_with_llnet('path_to_low_light_image.jpg', model, use_pretrained=True)
enhanced_image.show()
2. 性能与比较:
在实际测试中,LLNet与其他同类技术相比表现出色。它不仅在增强低光图像的准确性方面表现出众,而且由于其深度学习的本质,还能够在许多复杂的情况下提供更自然的增强效果。
与传统的图像增强技术相比,LLNet有以下优势:
- 自适应性:不需要手动调整参数,LLNet可以自动识别并修复图像中的问题。
- 高效性:尽管深度学习模型通常需要较大的计算资源,但预训练的模型可以在短时间内产生出色的结果。
3. 总结:
深度学习已经彻底改变了图像增强的方式。LLNet是这一变革的典型代表,它结合了深度神经网络的强大功能和图形用户界面的易用性,为用户提供了一个既强大又方便的工具来增强低光照条件下的图像。
总的来说,无论是研究者还是摄影爱好者,LLNet都为他们提供了一个前所未有的机会,让他们能够轻松地从低光环境中捕捉和重现美丽的瞬间。对于那些希望在此领域进一步研究或深入了解的人来说,我们强烈建议下载完整的项目并亲自体验LLNet的魅力。文章来源:https://www.toymoban.com/news/detail-659932.html
希望这篇文章为您提供了关于如何使用LLNet进行低光图像增强的有用信息,并激发了您进一步探索这一有趣领域的兴趣。文章来源地址https://www.toymoban.com/news/detail-659932.html
到了这里,关于低光图像增强:利用深度学习的LLNet与图形用户界面进行优化的实践的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!