论文基础信息如下

- https://arxiv.org/pdf/2305.03048.pdf
- https://github.com/ZrrSkywalker/Personalize-SAM
Abstract
通过大数据预训练驱动,分段任意模型(Segment Anything Model,SAM)已被证明是一个强大且可提示的框架,革新了分割模型。尽管其具有普遍性,但在没有人力提示的情况下,定制SAM以适应特定的视觉概念仍未得到充分探索,例如自动在不同的图像中分割您的宠物狗。在本文中,我们提出了一种无需训练的个性化方法,称为PerSAM,用于SAM。只给定一张带有参考掩码的单张图像,PerSAM首先通过位置先验定位目标概念,并通过三种技术在其他图像或视频中对其进行分割:目标引导的注意力、目标语义提示和级联后处理。通过这种方式,我们有效地适应了SAM的个人使用,而无需进行任何训练。为了进一步减轻掩码的歧义性,我们提出了一种高效的单次微调变体PerSAM-F。冻结整个SAM,我们引入了两个可学习的权重用于多尺度掩码,仅在10秒内训练2个参数以提高性能。为了证明我们的有效性,我们构建了一个新的分割数据集PerSeg,用于个性化评估,并在具有竞争性能的视频对象分割上测试了我们的方法。此外,我们的方法还可以增强DreamBooth,以个性化稳定扩散用于文本到图像生成,从而消除背景干扰以获得更好的目标外观学习。代码已在 https://github.com/ZrrSkywalker/Personalize-SAM 上发布。
1. Introduction
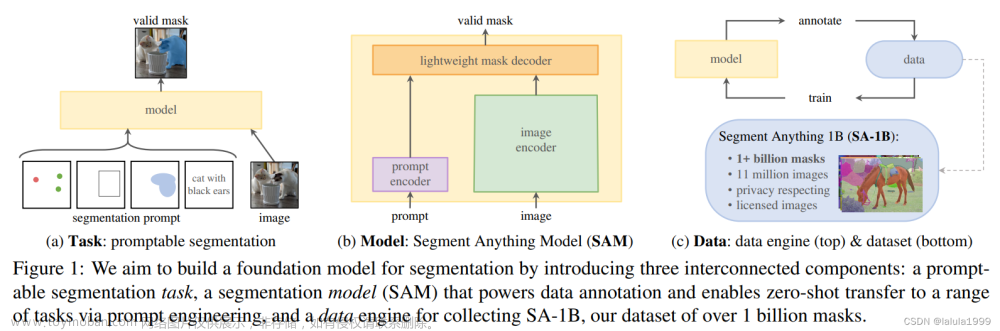
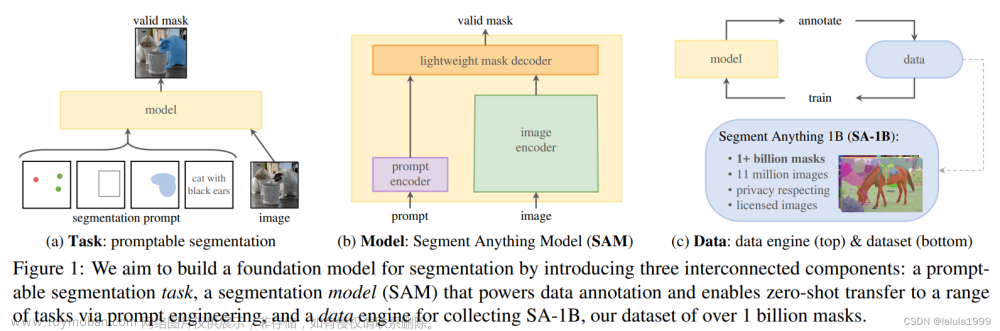
基于视觉[11, 30, 51, 63]、语言[4, 10, 43, 50]和多模态[21, 31, 41]的基础模型在预训练数据和计算资源的大量可用性的支持下,获得了前所未有的普及。它们展示了在零-shot场景下的非凡泛化能力,并融入了人类反馈的多功能互动性。受大型语言模型的成就启发,Segment Anything(SAM)[27]开发了一个精细的数据引擎,用于收集1100万个图像-掩膜数据,并随后训练了一个强大的分割基础模型,称为SAM。它首先定义了一种新颖的可提示的分割范式,即以手工设计的提示为输入,并返回期望的掩膜。SAM的可接受提示足够通用,包括点、框、掩膜和自由形式的文本,这允许在视觉环境中对任何内容进行分割。
然而,SAM本质上失去了分割特定视觉概念的能力。想象一下,你想从相册中裁剪出你可爱的宠物狗,或者从你卧室的照片中找到丢失的时钟。使用普通的SAM模型既费力又耗时。对于每张图像,你需要在不同的姿势或环境中定位目标对象,然后使用精确的提示激活SAM进行分割。因此,我们提出了一个问题:我们能否个性化SAM以简单高效地自动分割独特的视觉概念?

为此,我们提出了PerSAM,一种对Segment Anything Model(SAM)进行个性化改进的无需训练的方法。如图1所示,我们的方法仅使用一次性数据(即用户提供的图像和粗糙的掩码,用于指定个人概念),就能高效地定制SAM。具体来说,我们首先利用SAM的图像编码器和给定的掩码来编码参考图像中目标对象的嵌入。然后,在新的测试图像上计算目标对象与所有像素之间的特征相似性。在此基础上,我们选择两个点作为正负对,将其编码为提示符令牌,并作为SAM的位置先验进行使用。在处理测试图像的SAM解码器中,我们引入了三种技术来释放其个性化潜力,而无需进行参数调整。
-
面向目标的注意力。我们通过计算的特征相似度来引导SAM解码器中的每个令牌-图像交叉注意力层。这迫使提示令牌主要集中在前景目标区域上,以实现有效的特征交互。
-
目标语义提示。为了更好地提供SAM高级目标语义,我们将原始的低级提示令牌与目标对象的嵌入进行融合,为解码器提供更充足的视觉线索,以实现个性化分割。
-
级联后细化。为了获得更精细的分割结果,我们采用了两步后细化策略。我们利用SAM逐步改进其生成的掩码。这个过程只需要额外100毫秒的时间。
通过上述设计,PerSAM在各种姿势或情境下为独特的主体提供了良好的个性化分割性能,如图2所示。然而,偶尔会出现失败的情况,其中主体由层次结构组成,例如一个帽子放在一只泰迪熊上面,一个机器人玩具的头部,或者一个罐子的顶部。这种模糊性对于PerSAM来说构成了一个挑战,它需要确定适当的掩模尺度作为分割输出,因为从像素级别来看,局部部分和整体形状都可以被SAM视为有效的掩模。
为了减轻这个问题,我们进一步引入了我们方法的微调变体PerSAM-F。我们冻结整个SAM以保留其预训练的知识,并且仅在10秒内微调2个参数。具体而言,我们使SAM能够产生具有不同掩模尺度的多个分割结果。为了自适应地选择不同对象的最佳尺度,我们为每个尺度使用可学习的相对权重,并进行加权求和作为最终的掩模输出。通过这种高效的一次训练,PerSAM-T在分割准确性方面展现出更好的表现,如图2(右侧)所示。 与使用prompt tuning [29]或适配器 [19]不同,模糊性问题可以通过有效地加权多尺度掩模来有效地抑制。

此外,我们观察到我们的方法还可以帮助DreamBooth [45]更好地微调Stable Diffusion [44],用于个性化文本到图像生成,如图3所示。给定一些包含特定视觉概念的图像,例如你的宠物猫,DreamBooth及其其他作品[28]将这些图像转换为一个在词嵌入空间中的标识符[V],然后利用该标识符来表示句子中的目标对象。然而,该标识符同时包含给定图像中的背景视觉信息,例如楼梯。这不仅会覆盖生成图像中的新背景,还会干扰目标对象的表示学习。因此,我们建议利用我们的PerSAM高效地分割目标对象,并且仅通过少量图像中的前景区域来监督Stable Diffusion,以实现更多样化和更高保真度的合成。

我们将本文的贡献总结如下:
1.个性化分割任务。我们从一个新的角度出发,研究如何以最小的开销将分割基础模型定制为个性化场景,即从通用到私人目的。
-
SAM的高效适应。我们首次研究了将SAM适应到下游应用中,只通过微调2个参数,并提出了两种轻量级的解决方案:PerSAM和PerSAM-F。
-
个性化评估。我们标注了一个新的分割数据集PerSeg,其中包含不同背景下的各种类别。我们还在视频对象分割上进行了测试,并取得了有竞争力的结果。 • 更好的稳定扩散个性化。通过在少样本图像中对目标对象进行分割,我们减轻了背景的干扰,提高了DreamBooth的个性化生成效果。
2. Related Work
图像分割。 是计算机视觉中的一项基本任务,它要求对给定图像进行像素级理解。已经探索了多种与分割相关的任务,例如语义分割,它将每个像素分类到预定义的类别集合中;实例分割,专注于识别每个物体实例;全景分割,通过同时分配类别标签和实例标识来结合语义和实例分割任务;以及交互式分割,涉及在分割过程中进行人工干预以进行细化。最近,Segment Anything Model (SAM)设计了一个可提示的分割任务,并在许多图像分布上实现了强大的零样本泛化。同时,SegGPT和SEEM也提出了通用的框架,适用于各种分割场景。在这项研究中,我们引入了一项新任务,称为个性化分割,旨在分割用户提供的任意未见姿势或场景中的对象。我们提出了两种方法,PerSAM和PerSAM-F,以有效地定制SAM进行个性化分割。
基础模型。 具有强大的泛化能力,预训练的基础模型能够适应各种下游任务,并具有良好的性能。 在自然语言处理领域,BERT [10, 38],GPT系列 [4, 39, 42, 43],和LLaMA [58]展现了出色的上下文学习能力。这些模型可以在新的语言任务中进行迁移,无需训练,仅需在推理过程中提供几个任务特定的提示。类似地,CLIP [41]和ALIGN [21]通过对比损失在大规模图像-文本对上训练,展现了在零样本视觉学习任务中出色的性能。Painter [51]引入了一个视觉模型,通过统一架构和提示来自动完成多样化的视觉任务,无需特定的任务头。CaFo [59]串联不同的基础模型并协作利用它们的预训练知识进行零样本图像分类。SAM [27]提出了第一个用于图像分割的基础模型,它在10亿个掩码上进行了预训练,并在各种输入提示(如点、边界框、掩码和文本)的条件下进行了预训练。从另一个角度来看,我们提出了将基础分割模型(即SAM)个性化为特定视觉概念的方法,这将一个通才转化为只需一次试验的专家。我们的方法还可以协助个性化文本到图像的基础模型,即Stable Diffusion [44]和Imagen [46],通过将目标对象从背景区域分割出来来提高生成质量。
参数高效的微调。 直接在下游任务上微调整个基础模型可能会消耗大量计算资源和内存,给资源有限的应用带来挑战。为了解决这个问题,最近的研究聚焦于开发参数高效的方法来冻结基础模型的权重,并附加小规模模块进行微调。Prompt Tuning提议在冻结模型的同时使用可学习的软提示来执行特定的下游任务,相比于全模型微调,其在规模和鲁棒领域转移方面能够实现更有竞争力的性能。Low-Rank Adaption (LoRA)则在每个预训练权重同时注入可训练的秩分解矩阵,大幅减少了下游任务所需的可学习参数数量。而Adapters则设计为插入在原始Transformer的层之间,引入轻量级的多层感知机进行微调。LLaMAAdapter则提出了一种零初始化注意力的方法,逐步将新知识融入基础模型,稳定了早期的训练。与现有方法不同,我们采用了一种更高效的适应方法来进行SAM,可以通过无需训练的PerSAM或者仅微调2个参数的PerSAM-F来实现。这有效地避免了在一次性数据上的过拟合,并获得了令人满意的性能。
3. Method
在第3.1节中,我们首先回顾了Segment Anything Model(SAM)[27],并介绍了个性化分割的任务定义。然后,在第3.2节和第3.3节中,我们分别介绍了我们训练免费的PerSAM和其微调变体PerSAM-F的方法论。最后,在第3.4节中,我们利用我们的方法来帮助DreamBooth [45]更好地个性化Stable Diffusion [44]用于文本到图像生成。
3.1. Preliminary
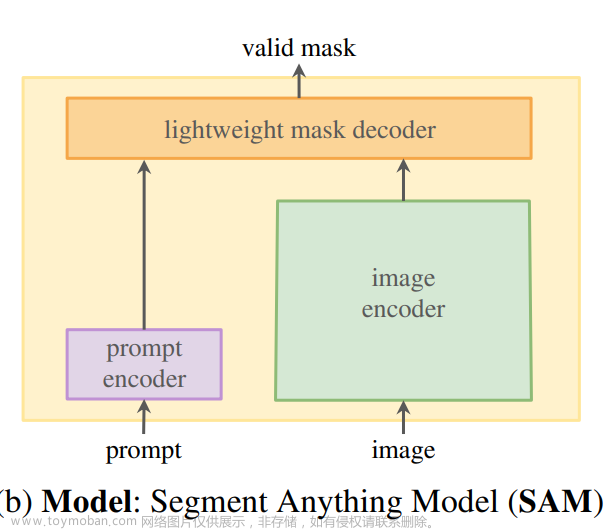
重新审视Segment Anything。 SAM定义了一个新的可提示的分割任务,其目标是为任何给定的提示返回一个分割蒙版。使用具有模型在环注释的数据引擎,SAM在1100万个图像上通过10亿个蒙版进行了完全的预训练,具有强大的泛化能力。SAM由三个主要组件组成,即提示编码器,图像编码器和轻量级蒙版解码器,分别表示为EncP,EncI和DecM。作为一个可提示的框架,SAM将图像I和一组提示P作为输入,例如前景或背景点,边界框或待精化的粗糙蒙版。SAM首先利用EncI获得输入图像特征,并使用EncP将人工给定的提示编码为c维度的标记,如下所示:

其中FI ∈ Rh×w×c和TP ∈ Rk×c,h,w表示图像特征的分辨率,k表示提示长度。之后,编码的图像和提示被输入到解码器DecM进行基于注意力的特征交互。SAM通过将几个可学习的标记TM作为前缀连接到提示标记之前来构建解码器的输入标记。这些蒙版标记负责生成最终的蒙版输出。我们将解码过程定义为:

其中M表示SAM的零-shot蒙版预测。
个性化分割任务。 尽管SAM可以通用地对用户提出的任何内容进行分割,但它缺乏对特定主体实例的分割能力。为了达到这个目的,我们定义了一个新的个性化分割任务。用户只需要提供一张参考图像,以及一个指示目标视觉概念的掩码。给定的掩码可以是准确的分割,也可以是用户在线绘制的简略草图。我们的目标是定制SAM以在新的图像或视频中对指定的主体进行分割,而无需人工提示。为了对模型进行评估,我们为个性化分割创建了一个新的数据集,名为PerSeg。原始图像来源于主体驱动扩散模型的作品[12, 28, 45],包含不同姿势或场景的各种视觉概念。在本文中,我们提出了两种高效的解决方案,PerSAM和PerSAM-F,具体如下所示。
3.2. Training-free PerSAM
正负位置先验。 图4展示了我们的无需训练的PerSAM的整体流程。首先,根据用户提供的图像IR和掩码MR,PerSAM使用SAM在新的测试图像I上获取目标对象的位置先验。具体地说,如图5所示,我们将SAM的预训练图像编码器应用于提取I和IR的视觉特征,即



在这段文本中,FI和FR是属于实数集R的变量。h、w、c分别表示高度、宽度和通道数。接下来,我们使用参考掩码MR(属于实数集R的变量)从FR中获取目标视觉概念内像素的特征,并采用平均池化来聚合其全局视觉嵌入TR(属于实数集R的变量),如下所示:

其中◦表示空间乘法。通过目标嵌入TR,我们可以通过计算测试图像特征FI与TR之间的余弦相似度S来获得位置置信度图:

在这之后,为了为测试图像提供SAM的位置先验信息,FI和TR会进行像素智能L2归一化处理。我们从S中选择两个相似度最高和最低的像素坐标,分别记为Ph和Pl。前者表示目标对象最可能处于的前景位置,而后者则相反地表示背景。然后,它们被视为正负点对,并作为提示编码器的输入,表示为
其中,TP ∈ R 2×c 作为SAM解码器的提示标记。以这种方式,SAM倾向于分割正样本点周围的连续区域,同时舍弃测试图像上的负样本点。
目标导向的注意力。 尽管已经使用了正负优先级,但我们进一步提出了对SAM解码器中的交叉注意机制进行更明确的指导,以在前景目标区域内集中特征聚合。如图6所示,方程5中计算得到的相似度图S可以清楚地指示测试图像上目标视觉概念的像素。因此,我们利用S来调节每个令牌到图像交叉注意层中的注意力图。我们将经过Softmax函数的注意力图表示为A ∈ R h×w,并通过以下方式引导其分布:

α表示平衡因子。通过注意偏向,令令牌被迫捕捉与目标主体相关的更多视觉语义,而不是不重要的背景。这有助于在注意力层中实现更有效的特征交互,并以一种无需训练的方式提高PerSAM的最终分割准确率。
目标语义提示。 普通的SAM仅接收携带低级位置信息的提示,例如点或框的坐标。为了融入更多个性化线索,我们提议额外利用目标概念的视觉嵌入TR作为PerSAM的高级语义提示。具体而言,在将其输入到图6所示的每个解码器块之前,我们将目标嵌入与方程式2中的所有输入令牌逐元素相加,表示为

在Repeat操作沿着令牌维度执行。借助简单的令牌合并,PerSAM不仅受到低级位置先验的推动,还通过辅助视觉线索得到高级目标语义的启发。
级联后处理。 通过以上技术,我们从SAM的解码器获得测试图像上的初始分割掩膜,然而,该掩膜可能在背景中包含一些粗糙的边缘和孤立的噪声。为了进一步改进,我们将掩膜迭代地反馈到SAM的解码器进行两步后处理。在第一步中,我们使用初始掩膜和先前的正负位置先验来提示SAM的解码器。然后,在第二步中,我们根据第一步的掩膜计算一个边界框,并额外使用这个框来提示解码器以获得更准确的物体定位。由于我们只需要进行轻量级解码器进行迭代改进而不需要大规模图像编码器,因此后处理效率高,只需要额外100毫秒的时间。
3.3. Fine-tuning of PerSAM-F
遮罩尺度的模糊性。 无需训练的PerSAM可以处理大多数情况,并具有令人满意的分割准确性。然而,一些目标对象包含层次结构,这导致需要分割不同尺度的多个遮罩。如图7所示,位于平台顶部的茶壶由两部分组成:盖子和身体。如果正先验(用绿色星号表示)位于身体上,而负先验(用红色星号表示)没有排除类似颜色的平台,则PerSAM在分割时会产生模糊性。这个问题也在SAM [27]中讨论过,它提出了一个替代方案,可以同时生成三个尺度的多个遮罩,分别对应于一个对象的整体、部分和子部分。然后,用户需要手动从三个遮罩中选择一个,这是有效的,但会耗费额外的人力。相比之下,我们的个性化任务旨在为SAM定制自动对象分割,而无需人工提示。这促使我们开发了一种针对尺度感知个性化的SAM方法,可以通过高效地微调仅有的几个参数来实现。

可学习的比例权重。 为了实现适应性分割,我们引入了一种微调变体PerSAM-F,并采用适当的掩膜比例。与只生成一个掩膜的无需训练的模型不同,PerSAM-F首先参考SAM的解决方案输出三个比例的掩膜,分别表示为M1、M2和M3。此外,我们采用两个可学习的掩膜权重w1和w2,并通过加权求和计算最终的掩膜输出:

w1、w2都被初始化为1/3。为了学习最佳权重,我们对参考图像进行一次性的微调,并将给定的掩码视为真实结果。需要注意的是,我们保留整个SAM模型以保留其预训练的知识,并且只在10秒内微调w1、w2的2个参数。我们不采用任何可学习的提示或适配器模块,以避免对一次性数据进行过拟合。通过这种方式,我们的PerSAM-F可以高效地学习不同视觉概念的最佳掩码比例,并展现出比无训练的PerSAM更强的分割性能。
3.4. Better Personalization of Stable Diffusion
DreamBooth是一种重新思考的方法。 类似于个性化分割,文本反转[12]、DreamBooth[45]和后续研究[28]对预训练的文本-图像模型进行微调,例如Stable Diffusion[44]和Imagen[46],以合成用户指定的特定视觉概念的图像。举个例子,给定3到5张猫的真实照片,DreamBooth进行少样本训练,并学习通过以文本提示“a [V] cat”作为输入生成该猫。其中,[V]作为唯一标识符在词嵌入空间中表示特定的猫。训练后,个性化的DreamBooth能够在不同场景中合成新的猫的版本,例如“a [V] cat on a beach.”或“a [V] cat in the Grand Canyon.”然而,DreamBooth计算整个重建图像与真实照片之间的L2损失。正如图3所示,这将使得少样本图像中多余的背景信息注入到标识符[V]中,覆盖了新生成的背景,并干扰了目标对象的表示学习。
PerSAM辅助的DreamBooth。 在图8中,我们介绍了一种减轻DreamBooth背景干扰的策略。如果用户还提供了少样本图像的对象掩码,我们可以利用我们的PerSAM或PerSAM-F将所有前景目标进行分割,并丢弃背景区域内像素的梯度反传。然后,仅对稳定扩散进行微调,以记忆目标物体的视觉外观,并且不对背景施加任何监督来保持其多样性。在此之后,PerSAM辅助的DreamBooth不仅能够更好地合成具有视觉对应性的主体实例,还能够增加根据文本提示引导的新上下文的多样性。
4. Experiment
首先,我们在第4.1节中评估了我们个性化分割的方法,并在第4.2节中报告了视频对象分割的结果。然后,在第4.3节中,我们展示了借助我们的背景掩码改进的DreamBooth [45]的文本到图像生成。最后,在第4.4节中,我们进行了消融研究,以调查我们的每个组件的有效性。
4.1. Personalized Evaluation
PerSeg数据集。 为了测试个性化容量,我们构建了一个新的分割数据集,称为PerSeg。原始图像收集自主题驱动扩散模型DreamBooth [45]、Textual Inversion [12]和Custom Diffusion [28]的训练数据。PerSeg总共包含了40个不同类别的物体,包括日常用品、动物和建筑物。每个物体在不同的姿势或场景中被标注了5-7张图像和我们的注释掩膜。默认情况下,我们将第一张图像视为用户提供的一次性数据,并通过平均交并比(mIoU)评估模型。
实验细节。 我们使用预训练的SAM [27]和ViT-H [11]图像编码器作为分割基础模型。对于PerSAM,我们将目标引导注意力和目标语义提示应用于SAM解码器中的所有三个Transformer块,即两个常规块和一个最终块。方程式7中的平衡因子α被设置为1。对于PerSAM-F,我们进行了一次性训练,共进行了1000个epochs,批量大小为1。我们将初始学习率设置为10−3,并使用带余弦调度器的AdamW [37]优化器。值得注意的是,我们在PerSAM-F中不应用目标引导注意力和目标语义提示,以更好地显示微调的有效性。在训练过程中没有使用数据增强技术。

绩效。 在表1中,我们报告了我们的方法和其他现有方法在PerSeg数据集上的分割结果。如图所示,经过微调的PerSAM-F取得了最佳绩效,并通过总体平均交并比(mIoU)提高了PerSAM的大部分视觉概念的+6.01%。Visual Prompting [2]、Painter [51]和SegGPT [53]是基于上下文的学习器,根据给定的提示图像对任意对象进行分割。与SAM类似,最近的SEEM [63]是一个具有更强交互性和组合性的大规模基于提示的模型。它们也可以通过将一次性数据视为提示来用于个性化分割。我们无需训练的PerSAM可以以显著的优势胜过Painter、Visual Prompting和SEEM。虽然SegGPT的结果与PerSAM-F相当,但它包含大量参数,并且是经过广泛数据训练的,具备个性化能力。相比之下,PerSAM-F仅微调了2个可学习权重,以高效地定制现成的SAM进行私人使用。更多可视化结果请参见图11。


4.2. Video Object Segmentation
实验细节。 除了仅有一个物体的图像外,PerSAM和PerSAM-F也可以扩展到对视频帧中的多个物体进行分割。给定第一帧及其物体掩码,我们的方法可以个性化地同时分割和跟踪视频中的多个物体。我们选择了流行的DAVIS 2017 [40]数据集进行评估,并采用官方的J和F分数作为评价指标。对于 PerSAM,我们将相似度最高的两个点视为正面的位置先验,并额外利用上一帧的边界框及其中心点来提示解码器。这为物体跟踪和分割提供了更充分的时间线索。对于 PerSAM-F,我们对第一帧进行了单次微调,共进行了800个时期,学习速率为4-4。对于其他配置,我们遵循个性化实验的方法。

性能表现。 在DAVIS 2017验证集上,视频分割结果如表2所示。与没有视频数据的方法相比,无需训练的PerSAM在J&F分数上大幅超过Painter [51] +25.7%,而PerSAMF在没有集成策略的情况下比SegGPT [53]的性能提高了+1.9%。 值得注意的是,我们的微调方法甚至可以在J&F分数上胜过AGSS [33]和AGAME [25],分别比它们高出4.5%和1.9%。这两个模型都是通过大量视频数据进行完全训练的。这些结果充分说明了我们对多个视觉概念的时间视频数据具有强大的泛化能力。我们在图9中展示了PerSAM-F在三个视频帧上的分割结果,我们的方法在多目标跟踪和分割方面表现出了良好的性能。
4.3. PerSAM-assisted DreamBooth
实验细节。 我们使用预训练的稳定扩散[44]作为基础文本到图像模型。我们遵循DreamBooth[45]中的大多数模型超参数和训练配置,包括10^-6的学习率、批大小为1和一个包含200个图像的正则化数据集。我们在单个NVIDIA A100 GPU上对DreamBooth进行了1,000次迭代的微调,耗时5分钟。为了获得更好的准确性,我们采用了PerSAM-F来分割目标对象,它通过给定的图像-掩码对进行一次性微调。需要注意的是,无需训练的PerSAM也可以达到类似的结果,我们之所以称之为“PerSAM辅助”,只是为了简单起见。
性能。 除了图3之外,我们还在图10中展示了PerSAM辅助的DreamBooth的更多结果。对于躺在灰色沙发上的狗,DreamBooth生成的“丛林”和“雪地”仍然是带有绿色和白色装饰的沙发。在 PerSAM-F 的协助下,新生成的背景与沙发完全解耦,并且与文本提示相吻合。对于其他两个主体,PerSAM-F 也减轻了谷仓后面的山脉背景干扰以及桌子旁边的沙发干扰。DreamBooth 在最后一行出现的“橙色桌子”错误也表明,PerSAM-F 可以提高目标的视觉外观学习,从而更好地个性化文本到图像模型。
4.4. Ablation Study
在表3中,我们对PerSAM和PerSAM-F在PerSeg数据集上的提出的组件的有效性进行了研究。如图所示,我们首先从一个基准模型开始,该模型的mIoU为69.11%,其中仅利用了正位置先验来自动提示SAM。然后,我们分别添加了负位置先验和级联后校正,分别将分割精度提高了+3.63%和+11.44%。这构建了一个具有83.91%的竞争模型,已经比预训练良好的Painter [51]和SEEM [63]更强大。除此之外,我们还将目标对象的高层语义引入SAM的解码器中,以指导交叉注意力和提示机制。+1.91%和+3.50%的mIoU改善完全表明了我们设计的重要性。最后,通过高效的一次性微调,PerSAM-F将分数提升了+6.01%,达到了95.33%的mIoU,展示了卓越的个性化能力。



5. Discussion
SegGPT和PerSAM之间的区别是什么?
Painter [51]和随后的SegGPT [53]都采用了上下文学习框架,将传统的分割任务重新定义为图像着色问题。
在给定的一次性提示下,它们也可以实现类似于PerSAM的个性化分割,如表1所示进行比较。然而,它们包含了3.54亿个可学习的参数,并统一了各种分割数据进行大规模训练。相比之下,我们的方法要么是免费训练,要么是在10秒钟内仅微调2个参数。我们的目标是以最低成本将现成的基础模型(即SAM)定制为私人使用的更高效方式。
PerSAM能处理多目标场景吗? 可以。如图9所示,表2中的视频对象分割任务需要在帧之间分割和跟踪多个对象,例如一个人和他的自行车。对于多个视觉概念,我们分别编码和存储它们的目标嵌入在第一帧中。然后,对于后续的帧,我们只运行图像编码器一次来提取视觉特征,并独立地为不同的对象提示掩码解码器。通过这种方式,我们的PerSAM和PerSAM-F可以高效地个性化地分割用户指定的多个视觉概念。

针对一次性遮罩质量的稳健性? 为了更稳健地与人类进行互动,我们研究了在给定低质量的一次性遮罩的情况下,PerSAM和PerSAM-F的表现如何。在表4中,我们分别缩小和扩大参考遮罩的区域,并在PerSeg数据集上比较分割结果。当遮罩小于目标对象的尺寸(缩小)时,经过微调的PerSAM-F在与SegGPT和PerSAM进行比较时表现出更强的稳健性。 这是因为围绕物体中心的内部点无法全面地代表其所有的视觉特征,这会损害得到的目标嵌入,削弱目标引导的注意力和目标语义提示的有效性。当掩模大于物体时(放大),不准确的掩模大小会误导PerSAM-F的一次性训练。相反,尽管存在一些背景噪声,目标嵌入可以包含物体的完整视觉外观,这对于PerSAM中的无训练技术几乎没有影响。总体而言,我们的PerSAM-F对于给定掩模的质量具有更好的鲁棒性,优于SegGPT。
6. Conclusion
在本文中,我们提出了一种只使用一次数据对特定视觉概念进行个性化的Segment Anything Model(SAM)。首先,我们引入了一种无需训练的方法,PerSAM,它在测试图像上计算位置先验,并采用了三种个性化技术:目标引导的注意力、目标语义提示和级联后期优化。在此基础上,我们进一步提出了一种10秒微调变体,PerSAM-F。通过仅使用2个可学习参数,PerSAM-F有效地减轻了遮罩尺度的歧义,并在我们的注释PerSeg数据集上取得了领先的性能。此外,我们还在视频对象分割上评估了我们的方法,并验证了它在辅助DreamBooth细调文本到图像扩散模型方面的有效性。我们希望我们的工作可以激励未来通过参数高效的方法个性化分割基础模型的研究工作。文章来源:https://www.toymoban.com/news/detail-660114.html
📙 预祝各位 前途似锦、可摘星辰
- 🎉 作为全网 AI 领域 干货最多的博主之一,❤️ 不负光阴不负卿 ❤️
- ❤️ 过去的每一天、想必你也都有努力、祝你披荆斩棘、未来可期
- 🍊 深度学习模型训练推理——基础环境搭建推荐博文查阅顺序【基础安装—认真帮大家整理了】
- 🍊 计算机视觉:硕博士,交流、敬请查阅
- 🍊 点赞 👍 收藏 ⭐留言 📝 都是博主坚持写作、更新高质量博文的最大动力!
 文章来源地址https://www.toymoban.com/news/detail-660114.html
文章来源地址https://www.toymoban.com/news/detail-660114.html
到了这里,关于Personalize Segment Anything Model with One Shot【论文翻译】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!