Influxdb数据库
1、简介与使用场景
简介
InfluxDB是一个由InfluxData开发的开源时序型数据库,专注于海量时序数据的高性能读、高性能写、高效存储与实时分析等,在DB-Engines Ranking时序型数据库排行榜上排名第一: InfluxDB广泛应用于DevOps监控、IoT监控、实时分析等场景。除了具有成本优势的高性能读、高性能写、高存储率,InfluxDB还具有如下特点:
InfluxDB广泛应用于DevOps监控、IoT监控、实时分析等场景。除了具有成本优势的高性能读、高性能写、高存储率,InfluxDB还具有如下特点:
- 无系统环境依赖,部署方便。
- 无结构化(SchemaLess)的数据模型,灵活强大。
- 原生HTTP管理接口,免插件配置和免第三方依赖。
- 强大的类SQL查询语句的操作接口,学习成本低,上手快。
- 丰富的权限管理功能,精细到“表”级别。
- 丰富的时效管理功能,自动删除过期数据,自定义删除指标数据。
- 低成本存储,采样时序数据,压缩存储。
- 丰富的聚合函数,支持AVG、SUM、MAX、MIN等聚合函数。
使用场景
时序数据以时间作为主要的查询纬度,通常会将连续的多个时序数据绘制成线,制作基于时间的多纬度报表,用于揭示数据背后的趋势、规律、异常,进行实时在线预测和预警,时序数据普遍存在于IT基础设施、运维监控系统和物联网中。如:监控数据统计。每毫秒记录一下电脑内存的使用情况,然后就可以根据统计的数据,利用图形化界面(InfluxDB V1一般配合Grafana)制作内存使用情况的折线图;可以理解为按时间记录一些数据(常用的监控数据、埋点统计数据等),然后制作图表做统计。
2、安装
2.1、传统安装
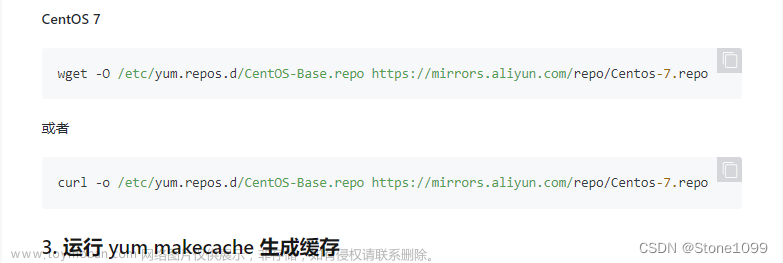
- 下载Linux的安装包:https://dl.influxdata.com/influxdb/releases/influxdb-1.8.0_linux_amd64.tar.gz,或者直接执行
wget https://dl.influxdata.com/influxdb/releases/influxdb-1.8.0_linux_amd64.tar.gz
-
推送到Linux系统上
-
解压缩
tar -zxf influxdb-1.8.0_linux_amd64.tar.gz
- 查看目录结构
[root@bogon temp]# cd influxdb-1.8.0-1/
[root@bogon influxdb-1.8.0-1]# ll
drwxr-xr-x. 4 root root 41 4月 12 2020 etc
drwxr-xr-x. 5 root root 41 4月 12 2020 usr
drwxr-xr-x. 4 root root 28 4月 12 2020 var
- etc 主要用来存储 influxdb 的系统配置信息
- usr 主要用来存储 influxdb 的操作相关脚本文件
- var 主要用来存储 influxdb 的运行日志、产生数据和依赖库文件
- 启动influxdb
[root@bogon influxdb-1.8.0-1]# cd usr/bin/
[root@bogon bin]# ls
influx influxd influx_inspect influx_stress influx_tsm
[root@bogon bin]# ./influxd
- 验证启动成功
# 新开一个终端
[root@bogon ~]# cd /root/temp/influxdb-1.8.0-1/usr/bin/
[root@bogon bin]# ./influx -host 127.0.0.1 -port 8086
Connected to http://127.0.0.1:8086 version 1.8.0
InfluxDB shell version: 1.8.0
# 连接格式
influx -database '数据库名' -host '主机名' -port '端口号' -username 用户名 -password 密码
2.2、Docker安装
需要有Docker前置知识
可以看这篇文章:https://blog.csdn.net/qq_56517253/article/details/127281571
- 编写docker-compose.yml
# 这里的版本号要对应自己的docker版本
version: "3"
volumes:
influxdb:
services:
influxdb:
image: influxdb:1.7.8
ports:
- '8086:8086'
volumes:
- influxdb:/root/influxdb/data
#- $PWD/influxdb.conf:/root/influxdb/influxdb.conf
environment:
- INFLUXDB_ADMIN_USER=root
- INFLUXDB_ADMIN_PASSWORD=root
- INFLUXDB_DB=history
restart: always
- 执行yml
# 本系统为centos7
# 1.更新依赖
[root@bogon influxdb]# yum install -y epel-release
# 2.安装docker-compose
[root@bogon influxdb]# yum install docker-compose
# 3.执行文件
[root@bogon influxdb]# docker-compose up
- 验证是否启动成功
[root@bogon bin]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
c1f8b1988283 influxdb:1.7.8 "/entrypoint.sh infl…" 50 seconds ago Up 48 seconds 0.0.0.0:8086->8086/tcp, :::8086->8086/tcp influxdb_influxdb_1
[root@bogon bin]# docker exec -it influxdb_influxdb_1 bash
root@c1f8b1988283:/# influx
Connected to http://localhost:8086 version 1.7.8
InfluxDB shell version: 1.7.8
>
3、客户端工具
DBeaver
4、相关概念
概念
- database:数据库,针对不同应用的数据进行隔离
- measurement:数据库中的表
- points:表里的一行数据
- Influxdb中独有的一些概念:Point由时间戳(time)、数据(field)和标签(tags)组成
库 database
表 measurement
数据 point = time(主键) + field(普通字段、存储数据) + tags(索引:加快查询速度)
time:主键,类似PrimaryKey
field:不经常查询的数据,可以直接存为 field
tags:索引字段
与Mysql对比
| 概念 | Mysql | Influxdb |
|---|---|---|
| 数据库(同) | database | database |
| 表(不同) | table | measurement |
| 列(不同) | column | tag(带索引,非必须)、field(不带索引)、timestamp(唯一主键) |
Point相当于传统数据库里的一行数据,如下表:
| Point属性 | 传统数据库中的概念 |
|---|---|
| time(时间戳) | 每个数据的记录时间,是数据库中的主索引(自动生成) |
| fields(字段、数据) | 各种记录值(没有索引的属性):温度、湿度… |
| tags(标签) | 各种有索引的属性:地区、海拔… |
注意:在influxdb中,字段必须存在。因为字段是没有索引的。如果使用字段作为查询条件,会扫描符合查询条件的所有字段值,性能不及tag。类比一下, fields相当于SQL的没有索引的列。tags是可选的,但是强烈建议你用上它,因为tag是有索引的,tags相当于SQL中的有索引的列。tag value只能是string类型。
类型说明
- tag类型
- tag都是
string类型
- tag都是
- field类型
- 支持四种类型:
int、float、string、boolean
- 支持四种类型:
| 类型 | 使用方式 | 实例 |
|---|---|---|
| float | 数字 | id=21 |
| int | 数字i | age=18i |
| boolean | true/false | buy=true |
| string | “” | ‘’ | email=“876606658@qq.com” |
5、基本操作
5.1、库 database
# 显示所有库
show databases
# 创建库
create database <name>
# 选中库
user <database-name>
# 删除库
drop database <name>
# 清空当前上下文的库
clear database|db # 取消当前选中的库
5.2、表 mesaurement
# 显示所有表
show measurements
# 删除表
drop measurement <name>
5.3、数据操作
插入数据
# 基本语法
insert <retention policy> measurement, tagKey=tagValue fieldKey=fieldValue timestamp
1. insert + measurement + "," + tag=value,tag=value + " " + field=value,field=value
2. tag与tag之间用逗号隔开,field与field之间用逗号隔开
3. tag与field之间用空格隔开
4. tag都是string类型,不需要引号
5. field如果是string类型,需要用引号
# 举例
> insert user,name=bby,phone=13066586501 age=20i,'email'="876606658@qq.com"
> show measurements
name: measurements
name
----
user # 多了user表
注意:Influxdb是不允许手动删除数据的,只能根据保留策略自己删除文章来源:https://www.toymoban.com/news/detail-660407.html
查询数据文章来源地址https://www.toymoban.com/news/detail-660407.html
# 测试数据
insert test,id=1 age=23,name="bby",address="shenyang"
insert test,id=2 age=24,name="zqj",address="changyuan"
insert test,id=3 age=20,name="zwj",address="zhoukou"
insert test,id=4 age=20,name="ctx",address="yanan"
insert test,id=5 age=21,name="zh",address="hanzhong"
insert test,id=6 age=22,name="zxd",address="ningbo"
insert test,id=7 age=22,name="zqx",address="zhengzhou"
insert test,id=8 age=23,name="dyz",address="nanyang"
insert test,id=9 age=24,name="hnb",address="taizhou"
- 普通查询
# 查询所有数据
> select * from test
name: test
time address age id name
---- ------- --- -- ----
1692521949440454412 shenyang 23 1 bby
1692521971727361412 changyuan 24 2 zqj
1692521993268148981 zhoukou 20 3 zwj
1692522010600707668 yanan 20 4 ctx
1692522032293330114 hanzhong 21 5 zh
1692522050213472795 ningbo 22 6 zxd
1692522066004959288 zhengzhou 22 7 zqx
1692522086233138642 nanyang 23 8 dyz
1692522104458762739 taizhou 24 9 hnb
# 根据tag查询
> select * from test where id='5'
name: test
time address age id name
---- ------- --- -- ----
1692522032293330114 hanzhong 21 5 zh
# 根据field查询
> select * from test where "name"='zwj' # 注意:name是保留字,需要+“”区分
name: test
time address age id name
---- ------- --- -- ----
1692521993268148981 zhoukou 20 3 zwj
# 从单个measurement中查询所有的field,不查tag
> select *::field from test;
name: test
time address age name
---- ------- --- ----
1692521949440454412 shenyang 23 bby
1692521971727361412 changyuan 24 zqj
1692521993268148981 zhoukou 20 zwj
1692522010600707668 yanan 20 ctx
1692522032293330114 hanzhong 21 zh
1692522050213472795 ningbo 22 zxd
1692522066004959288 zhengzhou 22 zqx
1692522086233138642 nanyang 23 dyz
1692522104458762739 taizhou 24 hnb
# 查询时不能只查tag,至少要有一个field项
> select *::tag,age from test;
name: test
time id age
---- -- ---
1692521949440454412 1 23
1692521971727361412 2 24
1692521993268148981 3 20
1692522010600707668 4 20
1692522032293330114 5 21
1692522050213472795 6 22
1692522066004959288 7 22
1692522086233138642 8 23
1692522104458762739 9 24
# 查询多张表 (没什么用,两个表依然是单独的数据)
> select * from "user",test
name: test
time 'email' address age id name name_1 phone
---- ------- ------- --- -- ---- ------ -----
1692521949440454412 shenyang 23 1 bby
1692521971727361412 changyuan 24 2 zqj
1692521993268148981 zhoukou 20 3 zwj
1692522010600707668 yanan 20 4 ctx
1692522032293330114 hanzhong 21 5 zh
1692522050213472795 ningbo 22 6 zxd
1692522066004959288 zhengzhou 22 7 zqx
1692522086233138642 nanyang 23 8 dyz
1692522104458762739 taizhou 24 9 hnb
name: user
time 'email' address age id name name_1 phone
---- ------- ------- --- -- ---- ------ -----
1692518226057415102 876606658@qq.com 20 bby 13066586531
# 模糊查询
# 前缀匹配 like 'z%'
> select * from test where "name"=~/^z/
name: test
time address age id name
---- ------- --- -- ----
1692521971727361412 changyuan 24 2 zqj
1692521993268148981 zhoukou 20 3 zwj
1692522032293330114 hanzhong 21 5 zh
1692522050213472795 ningbo 22 6 zxd
1692522066004959288 zhengzhou 22 7 zqx
# 后缀匹配 like '%j'
> select * from test where "name"=~/j$/
name: test
time address age id name
---- ------- --- -- ----
1692521971727361412 changyuan 24 2 zqj
1692521993268148981 zhoukou 20 3 zwj
# 前后匹配 like '%q%'
> select * from test where "name"=~/q/
name: test
time address age id name
---- ------- --- -- ----
1692521971727361412 changyuan 24 2 zqj
1692522066004959288 zhengzhou 22 7 zqx
- 聚合查询(
聚合查询只能对field字段进行操作,不能对tag字段操作)
# 非要对tag操作的话,子查询
> select distinct(id) from (select * from test)
name: test
time distinct
---- --------
0 1
0 2
0 3
0 4
0 5
0 6
0 7
0 8
0 9
# count() 统计某个 field 非空值的数量
> select count(age) from test
name: test
time count
---- -----
0 9
# distinct 去重
> select distinct(age) from test
name: test
time distinct
---- --------
0 23
0 24
0 20
0 21
0 22
# median() 求中位数
> select median(age) from test
name: test
time median
---- ------
0 22
# spread() 返回字段最小值与最大值的差值
select spread(age) from test
name: test
time spread
---- ------
0 4
# sum() 求和,字段必须是 int 或 float
> select sum(age) from test
name: test
time sum
---- ---
0 199
# bottom() 返回一个字段中最小的N个值
> select bottom(age,3) from test
name: test
time bottom
---- ------
1692521993268148981 20
1692522010600707668 20
1692522032293330114 21
# first() 返回一个字段中时间最早的值
> select first(age) from test
name: test
time first
---- -----
1692521949440454412 23
# last() 返回一个字段中时间最晚的值
> select last(age) from test
name: test
time last
---- ----
1692522104458762739 24
# max() 求最大值
> select max(age) from test
name: test
time max
---- ---
1692521971727361412 24
- 分组聚合
5.4、保留策略
6、权限配置
到了这里,关于Influxdb数据库(centos7)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!