前言
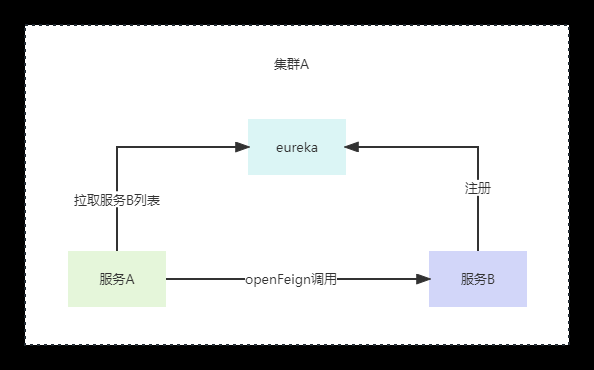
之前有发过一篇文章聊聊如何利用redis实现多级缓存同步。有个读者就给我留言说,因为他项目的redis版本不是6.0+版本,因此他使用我文章介绍通过MQ来实现本地缓存同步,他的同步流程大概如下图

他原来的业务流程是每天凌晨开启定时器去爬取第三方的数据,并持久化到redis,后边因为redis发生过宕机事故,他碰巧看了我文章,就觉得可以用使用多级缓存的策略,用来做个兜底。他的业务流程就如上图,即每天凌晨开启定时器去爬取第三方数据,持久化到redis和其中一台服务的本地缓存,然后将爬取到的业务数据发送到kafka,其他业务服务通过订阅kafka,将业务数据保存到本地缓存。
他改造完,某天突然发现在集群环境中,只要其中一台服务消费了kafka数据,其他就消费不到。今天就借这个话题,来聊聊集群环境中本地缓存如何进行同步
前置知识
kafka消费topic-partitions模式分为subscribe模式和assign模式。subscribe模式需要指定group.id,该模式会为consumer自动分配partition,且同一个group.id下的不同consumer不会消费同样的分区。assign模式需要为consumer手动、显示的指定需要消费的topic-partitions,不受group.id限制,相当与指定的group.id无效。通俗一点讲就是assign模式下,所有消费者都可以订阅指定分区
我们要通过消息队列实现本地缓存同步,本质上就是需要利用消息队列提供广播能力,而kafka默认不具备。不过我们可以根据kafka提供的消费模式进行定制,从而是kafka也具备广播能力
集群本地缓存同步方案
方案一:利用MQ广播能力
因为读者项目是使用kafka,且项目是使用spring-kafka,我们也就以此为例
1、subscribe模式
通过前置知识,我们了解到在subscribe模式下,同一个group.id下的不同consumer不会消费同样的分区,这就意味我们可以通过指定不同group.id来消费同样分区达到广播的效果
那如何在同个集群服务实现不同的group.id?
此时Spring EL 表达式就派上用场了,我们通过 Spring EL 表达式,在每个消费者分组的名字上配合 UUID 生成其后缀。这样,就能保证每个项目启动的消费者分组不同,从而达到广播消费的目的
示例
@KafkaListener(topics = "${userCache.topic}",groupId = "${userCache.topic}_group_" + "#{T(java.util.UUID).randomUUID()})")
public void receive(Acknowledgment ack, String data){
System.out.println(String.format("serverPort:【%s】,接收到数据:【%s】",serverPort,data));
ack.acknowledge();
}
如果我们决定UUID不直观,我们也可以使用IP作为标识,只要能保证同个集群服务的group.id是唯一即可
不过如果要改成ip,我们得做一定的改造。改造步骤如下
a、 获取ip地址信息,并放入environment
public class ServerAddrEnvironmentPostProcessor implements EnvironmentPostProcessor{
private String SERVER_ADDRESS = "server.addr";
@Override
@SneakyThrows
public void postProcessEnvironment(ConfigurableEnvironment environment, SpringApplication application) {
MutablePropertySources propertySources = environment.getPropertySources();
Map<String, Object> source = new HashMap<>();
String serverAddr = InetAddress.getLocalHost().getHostAddress();
source.put(SERVER_ADDRESS,serverAddr);
MapPropertySource mapPropertySource = new MapPropertySource("serverAddrProperties",source);
propertySources.addFirst(mapPropertySource);
}
}
b、 配置spi
在src/main/resource目录下配置META-INF/spring.factories,配置内容如下
org.springframework.boot.env.EnvironmentPostProcessor=\
com.github.lybgeek.comsumer.ip.ServerAddrEnvironmentPostProcessor
c、 @KafkaListener配置如下内容
@KafkaListener(topics = "${userCache.topic}",groupId = "${userCache.topic}_group_" + "${server.addr}" + "_${server.port}")
小结
该方式的实现优点是比较简单,但如果需要对服务进行运维监控统计,那就不怎么友好了,虽然指定IP会比随机UUID好点,但如果是容器化部署,每次部署其IP也是会变化,这样跟随机指定UUID,差别也不大了。其次如果是使用云产品,比如阿里云对comsume group是有数量上限,且消费者组需要提前创建,这种情况使用该方案就不是很合适了
assign模式
通过assign模式手动消费对应的分区
示例
@KafkaListener(topicPartitions =
{@TopicPartition(topic = "${userCache.topic}", partitions = "0")})
public void receive(Acknowledgment ack, ConsumerRecord record){
System.out.println(String.format("serverPort:【%s】,接收到数据:【%s】",serverPort,record));
ack.acknowledge();
}
小结
该方式实现也是很简单,如果我们不需要动态创建新的分区,用该方案实现广播,会是一个不错的选择。不过该方式的缺点很明显,因为是手动指定分区,当该分区有问题,也挺麻烦的
方案二:通过定时器触发
该方案主要基于读者目前的同步进行改造,改造后如下图

核心就是根据读者业务的特性,因为他是定时每天晚上同步爬取,那就意味着他这个数据至少在当天基本不变,就可以让集群里的服务都定时执行,此时仅需将xxl-job的调度策略改成分片广播就行,这样就可以持久化到redis的同时,也持久化到本地缓存
小结
该方案改动量比较小,有个小缺点就是,因为集群内所有服务都执行调度,这样就会使redis重复持久化,不过问题也不大就是好。最后读者选择该方案
总结
本文主要阐述集群环境中本地缓存如何进行同步,之前还有读者问我说,使用了多级缓存,数据一致性要如何保证?以前我可能会从技术角度来回答,比如你可以延迟双删,或者如果你是mysql,你可以使用canal+mq,更甚者你可以使用分布式锁来保证。但现在我更多从业务角度来思考这件事情,你都考虑使用缓存,是不是意味着你在业务上是可以容忍一定不一致性,既然可以容忍,是不是最终可以通过一些补偿方案来解决这个不一致性
没有完美的方案,你此时感觉的完美方案,可能是当时在那个业务场景下,做了一个贴合业务的权衡文章来源:https://www.toymoban.com/news/detail-660784.html
demo链接
https://github.com/lyb-geek/springboot-learning/tree/master/springboot-kafka-broadcast文章来源地址https://www.toymoban.com/news/detail-660784.html
到了这里,关于聊聊在集群环境中本地缓存如何进行同步的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!