消费方式
我们直到在性能设计中异步模式,一般要么是采用pull,要么采用push。而两种方式各有优缺点。
- pull :说白了就是通过消费端进行主动拉去数据,会根据自身系统处理能力去获取消息,上有Broker系统无需关注消费端的消费能力。kafka采用pull模式
- push : Broker主动推送消息到消费端,但是由于各个消费端吞吐量能力不同,可能推送相同的消息,不同的consumer处理能力不能,造成消息堆积。并且也需要下游系统的服务情况,以及当下游系统进行扩容或者宕机的时候都需要及时获取,这在设计难度上比较高。

消费者总体流程

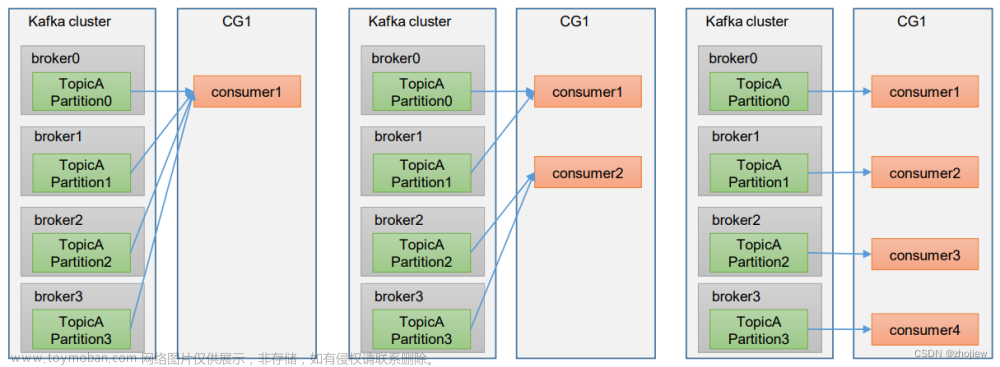
消费者组
Consumer Group 是 Kafka 提供的可扩展且具有容错性的消费者机制
- 消费者组有一个或多个消费者实例
- Group Id 标识一个消费者组 是唯一值,不同的Group 消费互相不影响
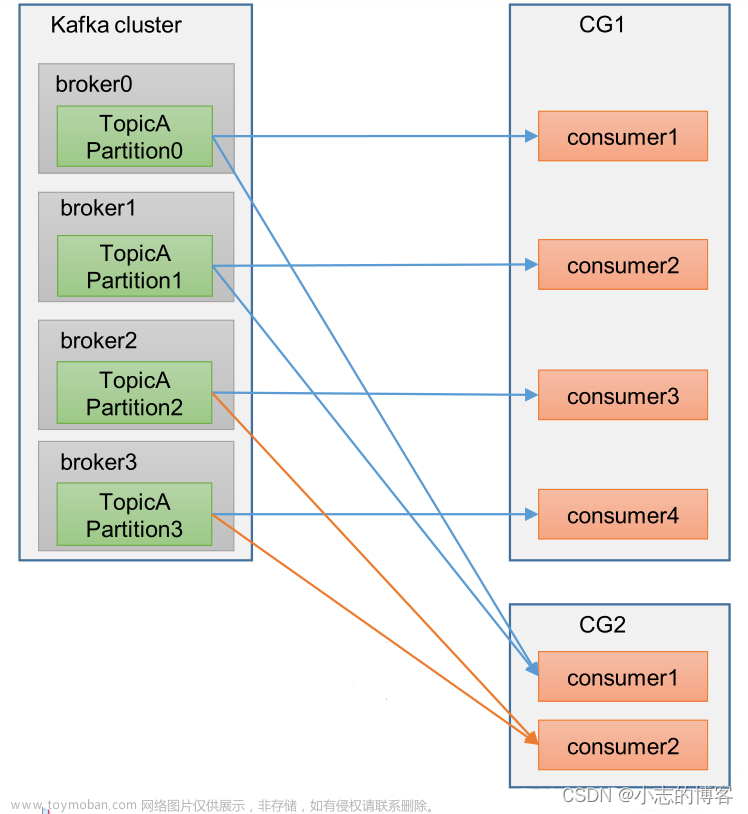
- Consumer Group 下所有实例订阅的主题的单个分区,只能分配给组内的某个 Consumer 实例消费。这个分区当然也可以被其他的 Group 消费
设置多少个消费者?
理想情况下,Consumer 实例的数量应该等于该 Group 订阅主题的分区总数。假设Group 订阅了3个主题,每个主题有3个分区,那么设置9个消费者最好,


消费组初始化过程

消费者组详细消费过程

分区的分配
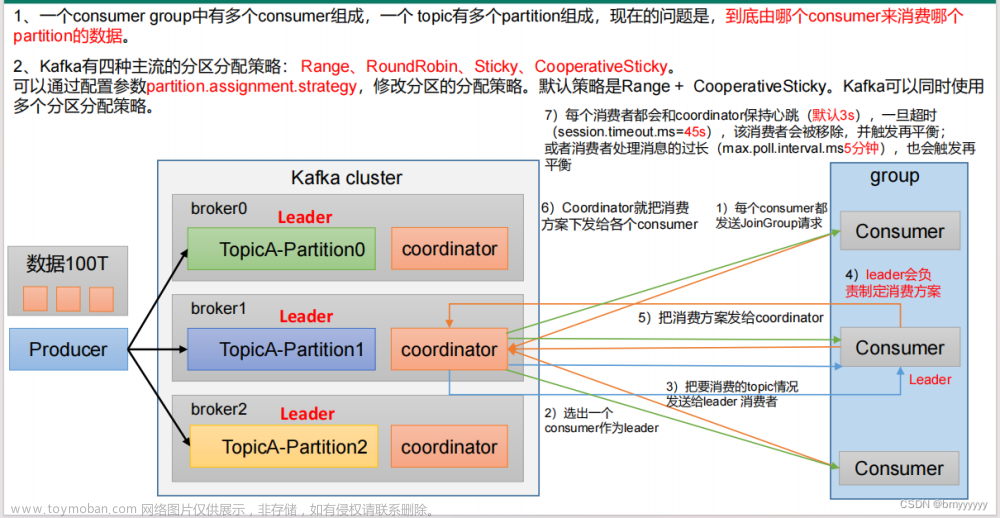
分区的分配: 首先说一下什么是分区的分配,通俗一点的话就是,我们直到一个Topic下可能存在多个分区,而同时可能存在多个Topic,也就是多Topic+多分区,而消费者这边为了提升消费能力,也会设置多个消费者组,每个消费者组都包含多个消费者,而如何将分区的消息对应到具体的消费者组下的消费者就是分区的分配。
如上图所示,具体会根据流程来进行分区的分配。
- 1.每个consumer发送Join Group请求到Broker的leader
- 2.选择出一个consumer作为一个Leader。
- 3.coordinator 把要消费的topic情况发送给Leader消费者
- 4.Consumer Leader会负责指定消费方案
- 5.把消费方案发给coordinator
- 6.coordinator把消费方案发给各个consumer
- 7.每个消费者和coordinator保持心跳,超时或者处理时间过长会触发在平衡。
1而在分区分配的时候有对应的分区策略具体就是如下三种方式
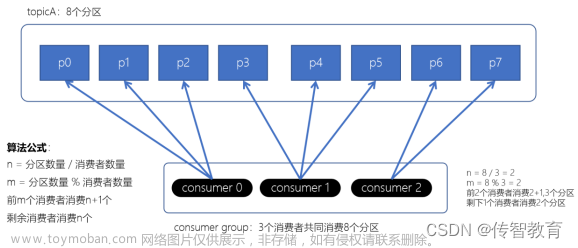
Range分区策略原理

总体思想就是将topic的分区和消费者进行排序,分区数/消费者个数。将对于出来的交给消费者排名考前的消费者,图中是7个分区,3个消费者。7/3 余 1,C0消费3个,C1和C2消费2个。
缺点:如果针对的topic和分区多,那么靠前的消费者可能会承担较多的消费。
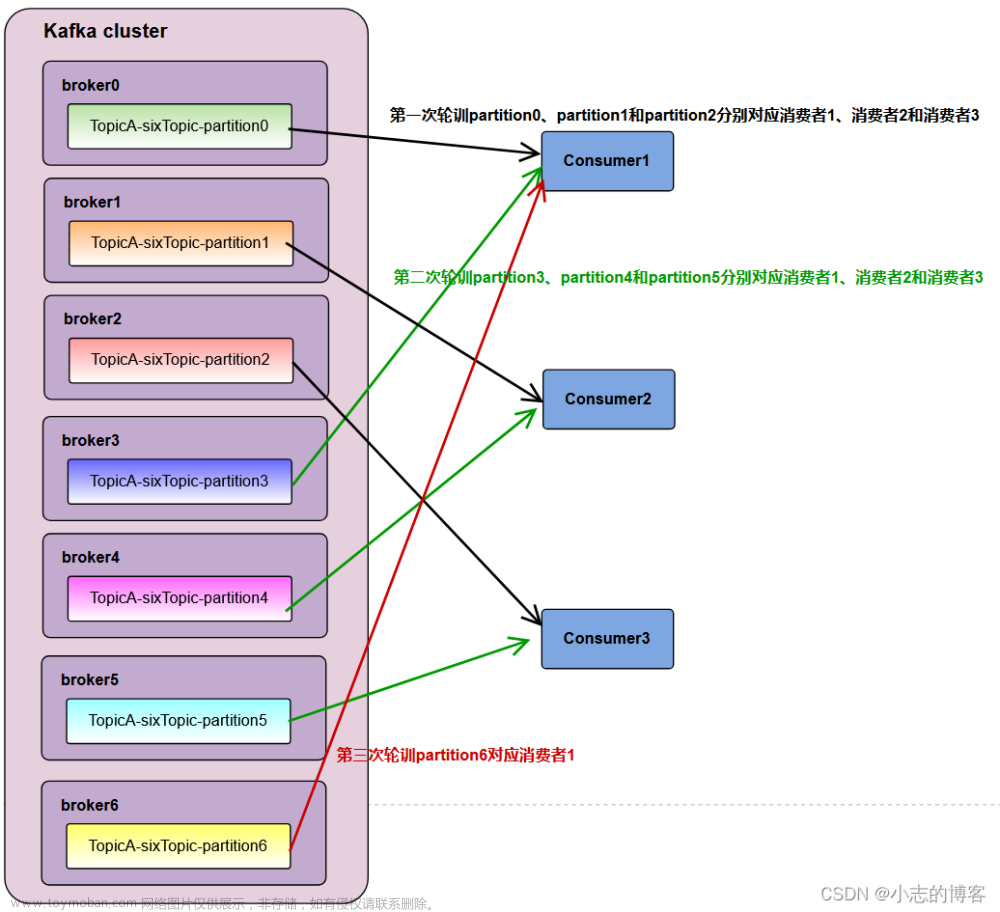
RoundRobin以及再平衡

直接就是按照分区进行hash,排序,比如7个分区,分别C0负责0,3,6,C1负责1,4,C2负责2,5
Sticky以及再平衡
粘性分区的出现主要是避免分区的变动,节省开销。
首先会尽量均衡的放置分区到消费者上面,在出现同一消费者组内消费者出现问题的时候,会尽量保持原有分配的分区不变化。
重平衡
重平衡:首先大家看到重平衡有点懵逼,说白了,就是在上述分区分配的过程中,如果出现消费者组中消费者退出或者新加入消费者的时候,需要将消费者组内对所消费的Topic的分区达成共识的过程。这个共识说白了就是AConsumer消费那个分区,BConsumer消费那个分区的过程。
协调者:在分区分配的过程中引入了一个协调者的概念,而这个针对的级别是每个Broker都有自己各自的Coordinator组件,比如你部署了三台Broker集群,那么就有三个Coordinator。作用主要是负责为Consumer Group服务,提供Rebalance以及位移管理和组成员管理的。
kafka确定consumer group的Coordinator的过程
- 确定位移主题的那个分区保存Group:partitionId=Math.abs(groupId.hashCode() % offsetsTopicPartitionCount)。
- 找出该分区的Leader副本所在的Broker,该Broker就是对应的Coordinator。
我们举一个案例来描述一下,假设我们的GroupId 是test,hash值是15,对应的分区是12个,15%12 = 3,那么分区3就是存储Group信息的分区,而通过这个分区3在找到对应的Leader副本,就可以确定在哪个Broker了。进一步找到对应的Coordinator。
如何避免重平衡
为什么要避免重平衡
- 在Rebalance过程中影响消费者的TPS,这个期间Consumer会停下手上所有的事情。
- Rebalance过程是比较慢的,会影响实时在线业务
发生Rebalance的时机
- 组成员数量发生变化
- 订阅主题数量发送变化
- 订阅主题的分区数发生变化
后两个其实是主动操作,是不可避免的。而大多数的Rebalance都是由于consumer成员发生变动导致的,一个是增加,增加消费者本身是为了提升系统消费者的吞吐量,这个不在控制范围,而减少就是重中之重的避免rebalance。
从上图我们直到,consumer会定期的向协调者Coordinator发送心跳检测,如果不能在固定时间内
session.timeout.ms 默认10S 发送心跳,Coordinator会认为consumer死亡,从而发生rebalance。
heartbeat.interval.ms 是发送心跳的频率,一般来说越高频发送心跳检测,那么消耗的带宽资源就越多。
max.poll.interval.ms consumer端两次调用poll的最大时间间隔,默认是5分钟,如果5分钟没有消费poll方法返回的消息,那么会主动发起离开组的请求,开启新的一轮rebalance。
如何避免文章来源:https://www.toymoban.com/news/detail-661193.html
-
避免rebalance未能及时发送心跳而导致触发Rebalance。需要合理设置参数值
- 设置 session.timeout.ms = 6s。
- 设置 heartbeat.interval.ms = 2s。
- 要保证 Consumer 实例在被判定为“dead”之前,能够发送至少 3 轮的心跳请求,即 session.timeout.ms >= 3 * heartbeat.interval.ms。
- Rebalance 是 Consumer 消费时间过长导致的,根据业务处理时间设置 max.poll.interval.ms的值。如果业务处理50S,那么就设置55S
小结
本篇从消费者角度描述了一下 消费者组和消费者的关系,以及消费者组和分区的关联流程,而从中引出了重平衡的话题,而在实际的生产环境中我们需要避免重平衡的发生。文章来源地址https://www.toymoban.com/news/detail-661193.html
到了这里,关于【消息队列】细说Kafka消费者的分区分配和重平衡的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!