比赛:https://marketing.csdn.net/p/f3e44fbfe46c465f4d9d6c23e38e0517
Intel® DevCloud for oneAPI:https://devcloud.intel.com/oneapi/get_started/aiAnalyticsToolkitSamples/
Intel® Optimization for PyTorch
在本次实验中,我们利用PyTorch和Intel® Optimization for PyTorch的强大功能,对PyTorch进行了精心的优化和扩展。这些优化举措极大地增强了PyTorch在各种任务中的性能,尤其是在英特尔硬件上的表现更加突出。通过这些优化策略,我们的模型在训练和推断过程中变得更加敏捷和高效,显著地减少了计算时间,提高了整体效能。我们通过深度融合硬件和软件的精巧设计,成功地释放了硬件潜力,使得模型的训练和应用变得更加快速和高效。这一系列优化举措为人工智能应用开辟了新的前景,带来了全新的可能性。![[oneAPI] 使用Bert进行中文文本分类,python杂记,oneapi,bert,分类](https://imgs.yssmx.com/Uploads/2023/08/661538-1.png)
基于BERT的文本分类模型
基于BERT的文本分类模型就是在原始的BERT模型后再加上一个分类层即可,同时,对于分类层的输入(也就是原始BERT的输出),默认情况下取BERT输出结果中[CLS]位置对于的向量即可,当然也可以修改为其它方式,例如所有位置向量的均值等。因此,对于基于BERT的文本分类模型来说其输入就是BERT的输入,输出则是每个类别对应的logits值。
数据预处理
在构建数据集之前,我们首先需要知道的是模型到底应该接收什么样的输入,然后才能构建出正确的数据形式。在上面我们说到,基于BERT的文本分类模型的输入就等价于BERT模型的输入,同时BERT模型的输入如图1所示:![[oneAPI] 使用Bert进行中文文本分类,python杂记,oneapi,bert,分类](https://imgs.yssmx.com/Uploads/2023/08/661538-2.png)
数据集
在这里,我们使用到的数据集是今日头条开放的一个新闻分类数据集(https://github.com/aceimnorstuvwxz/toutiao-text-classfication-dataset),一共包含有382688条数据,15个类别,经过处理后数据集格式为:
千万不要乱申请网贷,否则后果很严重_!_4
10年前的今天,纪念5.12汶川大地震10周年_!_11
怎么看待杨毅在一NBA直播比赛中说詹姆斯的球场统治力已经超过乔丹、伯德和科比?_!_3
戴安娜王妃的车祸有什么谜团?_!_2
其中_!_左边为新闻标题,也就是后面需要用到的分类文本,右边为类别标签。
定义tokenize
将输入进来的文本序列tokenize到字符级别。对于中文语料来说就是将每个字和标点符号都给切分开。在这里,我们可以借用transformers包中的BertTokenizer方法来完成,如下所示:
1 if __name__ == '__main__':
2 model_config = ModelConfig()
3 tokenizer = BertTokenizer.from_pretrained(model_config.pretrained_model_dir).tokenize
4 print(tokenizer("青山不改,绿水长流,我们月来客栈见!"))
5 print(tokenizer("10年前的今天,纪念5.12汶川大地震10周年"))
6
7 # ['青', '山', '不', '改', ',', '绿', '水', '长', '流', ',', '我', '们', '月', '来', '客', '栈', '见', '!']
8 # ['10', '年', '前', '的', '今', '天', ',', '纪', '念', '5', '.', '12', '汶', '川', '大', '地', '震', '10', '周', '年']
建立词表
将vocab.txt中的内容读取进来形成一个词表即可
1 class Vocab:
2 UNK = '[UNK]'
3 def __init__(self, vocab_path):
4 self.stoi = {}
5 self.itos = []
6 with open(vocab_path, 'r', encoding='utf-8') as f:
7 for i, word in enumerate(f):
8 w = word.strip('\n')
9 self.stoi[w] = i
10 self.itos.append(w)
11
12 def __getitem__(self, token):
13 return self.stoi.get(token, self.stoi.get(Vocab.UNK))
14
15 def __len__(self):
16 return len(self.itos)
转换为Token序列
在得到构建的字典后,便可以通过如下函数来将训练集、验证集和测试集转换成Token序列:
1 def data_process(self, filepath):
2 raw_iter = open(filepath, encoding="utf8").readlines()
3 data = []
4 max_len = 0
5 for raw in tqdm(raw_iter, ncols=80):
6 line = raw.rstrip("\n").split(self.split_sep)
7 s, l = line[0], line[1]
8 tmp = [self.CLS_IDX] + [self.vocab[token] for token in self.tokenizer(s)]
9 if len(tmp) > self.max_position_embeddings - 1:
10 tmp = tmp[:self.max_position_embeddings - 1] # BERT预训练模型只取前512个字符
11 tmp += [self.SEP_IDX]
12 tensor_ = torch.tensor(tmp, dtype=torch.long)
13 l = torch.tensor(int(l), dtype=torch.long)
14 max_len = max(max_len, tensor_.size(0))
15 data.append((tensor_, l))
16 return data, max_len
padding处理与mask
对原始文本序列tokenize转换为Token ID后还需要对其进行padding处理。对于这一处理过程可以通过如下代码来完成:
1 def pad_sequence(sequences, batch_first=False, max_len=None, padding_value=0):
2 if max_len is None:
3 max_len = max([s.size(0) for s in sequences])
4 out_tensors = []
5 for tensor in sequences:
6 if tensor.size(0) < max_len:
7 tensor = torch.cat([tensor, torch.tensor(
8 [padding_value] * (max_len - tensor.size(0)))], dim=0)
9 else:
10 tensor = tensor[:max_len]
11 out_tensors.append(tensor)
12 out_tensors = torch.stack(out_tensors, dim=1)
13 if batch_first:
14 return out_tensors.transpose(0, 1)
15 return out_tensors
模型
class BertModel(nn.Module):
"""
"""
def __init__(self, config):
super().__init__()
self.bert_embeddings = BertEmbeddings(config)
self.bert_encoder = BertEncoder(config)
self.bert_pooler = BertPooler(config)
self.config = config
self._reset_parameters()
def forward(self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None):
"""
***** 一定要注意,attention_mask中,被mask的Token用1(True)表示,没有mask的用0(false)表示
这一点一定一定要注意
:param input_ids: [src_len, batch_size]
:param attention_mask: [batch_size, src_len] mask掉padding部分的内容
:param token_type_ids: [src_len, batch_size] # 如果输入模型的只有一个序列,那么这个参数也不用传值
:param position_ids: [1,src_len] # 在实际建模时这个参数其实可以不用传值
:return:
"""
embedding_output = self.bert_embeddings(input_ids=input_ids,
position_ids=position_ids,
token_type_ids=token_type_ids)
# embedding_output: [src_len, batch_size, hidden_size]
all_encoder_outputs = self.bert_encoder(embedding_output,
attention_mask=attention_mask)
# all_encoder_outputs 为一个包含有num_hidden_layers个层的输出
sequence_output = all_encoder_outputs[-1] # 取最后一层
# sequence_output: [src_len, batch_size, hidden_size]
pooled_output = self.bert_pooler(sequence_output)
# 默认是最后一层的first token 即[cls]位置经dense + tanh 后的结果
# pooled_output: [batch_size, hidden_size]
return pooled_output, all_encoder_outputs
def _reset_parameters(self):
r"""Initiate parameters in the transformer model."""
"""
初始化
"""
for p in self.parameters():
if p.dim() > 1:
normal_(p, mean=0.0, std=self.config.initializer_range)
@classmethod
def from_pretrained(cls, config, pretrained_model_dir=None):
model = cls(config) # 初始化模型,cls为未实例化的对象,即一个未实例化的BertModel对象
pretrained_model_path = os.path.join(pretrained_model_dir, "pytorch_model.bin")
if not os.path.exists(pretrained_model_path):
raise ValueError(f"<路径:{pretrained_model_path} 中的模型不存在,请仔细检查!>\n"
f"中文模型下载地址:https://huggingface.co/bert-base-chinese/tree/main\n"
f"英文模型下载地址:https://huggingface.co/bert-base-uncased/tree/main\n")
loaded_paras = torch.load(pretrained_model_path)
state_dict = deepcopy(model.state_dict())
loaded_paras_names = list(loaded_paras.keys())[:-8]
model_paras_names = list(state_dict.keys())[1:]
if 'use_torch_multi_head' in config.__dict__ and config.use_torch_multi_head:
torch_paras = format_paras_for_torch(loaded_paras_names, loaded_paras)
for i in range(len(model_paras_names)):
logging.debug(f"## 成功赋值参数:{model_paras_names[i]},形状为: {torch_paras[i].size()}")
if "position_embeddings" in model_paras_names[i]:
# 这部分代码用来消除预训练模型只能输入小于512个字符的限制
if config.max_position_embeddings > 512:
new_embedding = replace_512_position(state_dict[model_paras_names[i]],
loaded_paras[loaded_paras_names[i]])
state_dict[model_paras_names[i]] = new_embedding
continue
state_dict[model_paras_names[i]] = torch_paras[i]
logging.info(f"## 注意,正在使用torch框架中的MultiHeadAttention实现")
else:
for i in range(len(loaded_paras_names)):
logging.debug(f"## 成功将参数:{loaded_paras_names[i]}赋值给{model_paras_names[i]},"
f"参数形状为:{state_dict[model_paras_names[i]].size()}")
if "position_embeddings" in model_paras_names[i]:
# 这部分代码用来消除预训练模型只能输入小于512个字符的限制
if config.max_position_embeddings > 512:
new_embedding = replace_512_position(state_dict[model_paras_names[i]],
loaded_paras[loaded_paras_names[i]])
state_dict[model_paras_names[i]] = new_embedding
continue
state_dict[model_paras_names[i]] = loaded_paras[loaded_paras_names[i]]
logging.info(f"## 注意,正在使用本地MyTransformer中的MyMultiHeadAttention实现,"
f"如需使用torch框架中的MultiHeadAttention模块可通过config.__dict__['use_torch_multi_head'] = True实现")
model.load_state_dict(state_dict)
return model
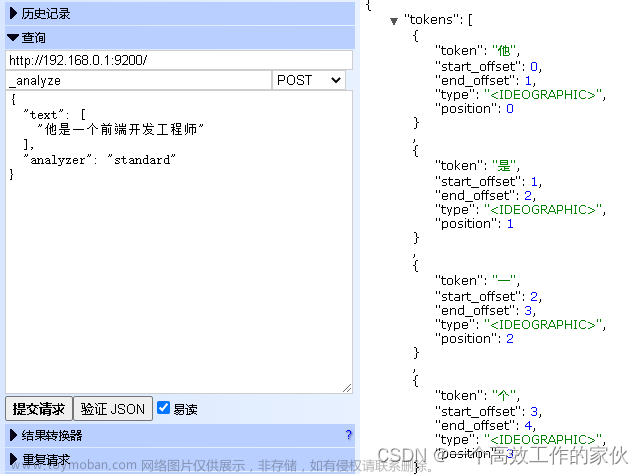
结果
![[oneAPI] 使用Bert进行中文文本分类,python杂记,oneapi,bert,分类](https://imgs.yssmx.com/Uploads/2023/08/661538-3.png) 文章来源:https://www.toymoban.com/news/detail-661538.html
文章来源:https://www.toymoban.com/news/detail-661538.html
OneAPI
import intel_extension_for_pytorch as ipex
model = model.to(config.device)
optimizer = torch.optim.Adam(model.parameters(), lr=5e-5)
'''
Apply Intel Extension for PyTorch optimization against the model object and optimizer object.
'''
model, optimizer = ipex.optimize(model, optimizer=optimizer)
参考资料
基于BERT预训练模型的中文文本分类任务: https://www.ylkz.life/deeplearning/p10979382/文章来源地址https://www.toymoban.com/news/detail-661538.html
到了这里,关于[oneAPI] 使用Bert进行中文文本分类的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![[oneAPI] 基于BERT预训练模型的英文文本蕴含任务](https://imgs.yssmx.com/Uploads/2024/02/666282-1.png)








