Kafka
概述
- 对比

- 选择

- 介绍

- producer: 发布消息的对象称之为主题生产者 (Kafka topic producer)
- topic: Kafka将消息分门别类,每一类的消息称之为一个主题 (Topic)
- consumer:订阅消息并处理发布的消息的对象称之为主题消费者 (consumers)
- broker:已发布的消息保存在一组服务器中,称之为Kafka集群,集群中的每一个服务器都是一个代理(Broker)。消费者可以订阅个或多个主题 (topic),并从Broker拉数据,从而消费这些已发布的消息
安装配置
- 安装zookeeper
// 下载zookeeper镜像 docker pull zookeeper:3.4.14 // 创建容器 docker run -d --name zookeeper -p 2181:2181 zookeeper:3.4.14 - 安装kafka
// 下载kafka镜像 docker pull wurstmeister/kafka:2.12-2.3.1 // 创建容器 docker run -d --name kafka \ --env KAFKA_ADVERTISED_HOST_NAME=192.168.174.133 \ --env KAFKA_ZOOKEEPER_CONNECT=192.168.174.133:2181 \ --env KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.174.133:9092 \ --env KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 \ --env KAFKA_HEAP_OPTS="-Xmx256M -Xms256M" \ --net=host wurstmeister/kafka:2.12-2.3.1 // 解释 --net=host,直接使用容器宿主机的网络命名空间,即没有独立的网络环境。它使用宿主机的ip和端口(云主机会不好使)
kafka入门
- 依赖
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> </dependency> - Producer
public class ProducerQuickStart { public static void main(String[] args) { // 1. kafka链接配置信息 Properties prop = new Properties(); // 1.1 kafka链接地址 prop.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.174.133:9092"); // 1.2 key和value的序列化 prop.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); prop.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); // 2. 创建kafka生产者对象 KafkaProducer<String, String> producer = new KafkaProducer<>(prop); // 3. 发送信息 // 参数列表: topic, key, value ProducerRecord<String, String> record = new ProducerRecord<>("topic-first", "key1", "Hello Kafka!"); producer.send(record); // 4. 关闭消息通道 // 必须关闭, 否则消息发送bucg producer.close(); } } - Consumer
public class ConsumerQuickStart { public static void main(String[] args) { // 1. kafka的配置信息 Properties prop = new Properties(); // 1.1 链接地址 prop.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.174.133:9092"); // 1.2 key和value的反序列化器 prop.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer"); prop.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer"); // 1.3 设置消费者组 prop.put(ConsumerConfig.GROUP_ID_CONFIG, "group1"); // 2. 创建消费者对象 KafkaConsumer<String, String> consumer = new KafkaConsumer<>(prop); // 3. 订阅主题 consumer.subscribe(Collections.singleton("topic-first")); // 4. 拉取信息 while(true) { ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000)); for (ConsumerRecord<String, String> record : records) { System.out.println(record.key()); System.out.println(record.value()); } } } } - 总结
- 同一组只有一个消费者能够接收到消息, 如果需要所有消费者都能接收到消息, 需要消费者在不同的组
kafka高可用方案
-
集群

-
备份

kafka定义了两类副本:- 领导者副本
- 追随者副本
数据在领导者副本存储后, 会同步到追随者副本

同步方式
leader失效后, 选择leader的原则- 优先从ISR中选取, 因为ISR的数据和leader是同步的.
- ISR中的follower都不行了, 就从其他的follower中选取.
- 当所有的follower都失效了, 第一种是等待ISR中的follower活过来, 数据可靠, 但等待时间不确定, 第二种是等待任意follower活过来, 最快速度恢复可用性, 但数据不一定完整.
kafka详解
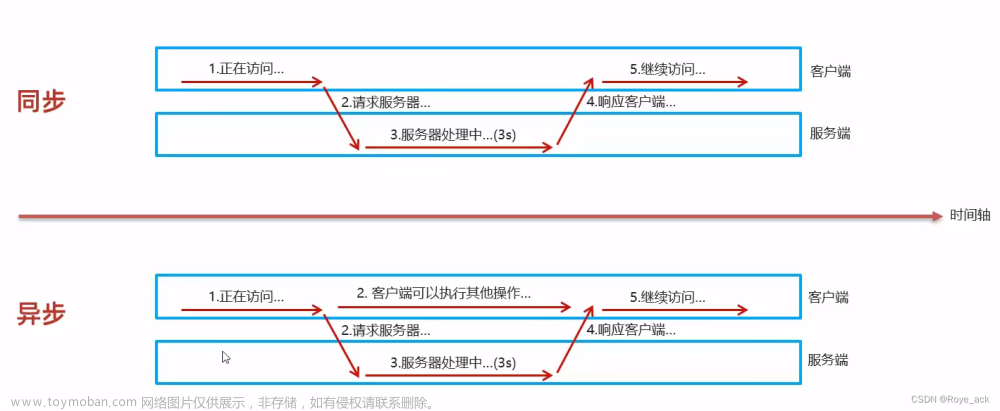
生产者同步异步发送消息
// 同步发送
RecordMetadata metadata = producer.send(record).get();
System.out.println(metadata.offset());
// 异步发送
producer.send(record, new Callback(){
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if(e != null) {
System.out.println("记录异常信息到日志表中");
}
System.out.println(recordMetadata.offset());
}
});
生产者参数配置
- 消息确认
确认机制 说明 acks=0 生产者在成功写入消息之前不会等待任何来自服务器的响应,消息有丢失的风险,但是速度最快 acks=1(默认值) 只要集群首领节点收到消息,生产者就会收到一个来自服务器的成功响应 acks=all 只有当所有参与赋值的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应 prop.put(ProducerConfig.ACKS_CONFIG, "all"); - 消息重传
设置消息重传次数, 默认每次重试之间等待100msprop.put(ProducerConfig.RETRIES_CONFIG, 10); - 消息压缩
默认情况, 消息发送不会压缩
使用压缩可以降低网络传输开销和存储开销, 而这往往是向kafka发送消息的瓶颈所在压缩算法 说明 snappy 占用较少的 CPU,却能提供较好的性能和相当可观的压缩比,如果看重性能和网络带宽,建议采用 lz4 占用较少的 CPU,压缩和解压缩速度较快,压缩比也很客观 gzip 占用较多的CPU,但会提供更高的压缩比,网络带宽有限,可以使用这种算法 prop.put(ProducerConfig.COMPRESSION_TYPE_CONFIG, "snappy");
消费者同步异步提交偏移量
// 同步提交偏移量
consumer.commitSync();
// 异步提交偏移量
consumer.commitAsync(new OffsetCommitCallback(){
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> map, Exception e) {
if(e!=null){
System.out.println("记录错误的提交偏移量"+map+", 异常信息为"+e);
}
}
});
// 同步异步提交
try {
while(true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.key());
System.out.println(record.value());
System.out.println(record.partition());
System.out.println(record.offset());
}
// 异步提交偏移量
consumer.commitAsync();
}
} catch (Exception e) {
e.printStackTrace();
System.out.println("记录错误的信息:"+e);
}finally {
// 同步
consumer.commitSync();
}
SpringBoot集成kafka
- 依赖
<dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> </dependency> - 配置
server: port: 9991 spring: application: name: kafka-demo kafka: bootstrap-servers: 192.168.174.133:9092 producer: retries: 10 key-serializer: org.apache.kafka.common.serialization.StringSerializer value-serializer: org.apache.kafka.common.serialization.StringSerializer consumer: group-id: ${spring.application.name}-test key-deserializer: org.apache.kafka.common.serialization.StringDeserializer value-deserializer: org.apache.kafka.common.serialization.StringDeserializer - Producer
@RestController public class HelloController { @Autowired private KafkaTemplate<String, String> kafkaTemplate; @GetMapping("/hello") public String hello() { kafkaTemplate.send("itcast-topic", "黑马程序员"); return "ok"; } } - Consumer
@Component public class HelloListener { @KafkaListener(topics = "itcast-topic") public void onMessage(String message) { if(!StringUtils.isEmpty(message)){ System.out.println(message); } } } - 传递对象
// Producer User user = new User(); user.setName("tom"); user.setAge(18); kafkaTemplate.send("itcast-topic", JSON.toJSONString(user)); // Consumer System.out.println(JSON.parseObject(message, User.class));
自媒体文章上下架
实现思路

具体实现
- Producer
public ResponseResult downOrUp(WmNewsDto dto) { // 1. 检验参数 // 1.0 检查文章dto是否为空 if(dto == null){ return ResponseResult.errorRe(AppHttpCodeEnum.PARAM_INVALID, "不可缺少"); } // 1.1 检查文章上架参数是否合法 if(dto.getEnable() != 0 && dto.getEnabl!= 1){ // 默认上架 dto.setEnable((short) 1); } // 2. 查询文章 WmNews news = getById(dto.getId()); if(news == null){ return ResponseResult.errorRe(AppHttpCodeEnum.DATA_NOT_EXIST, 存在"); } // 3. 查询文章状态 if(news.getStatus() != WmNews.StaPUBLISHED.getCode()){ return ResponseResult.errorRe(AppHttpCodeEnum.PARAM_INVALID, 章不是发布状态, 不能上下架"); } // 4. 上下架 news.setEnable(dto.getEnable()); updateById(new // 5. 发送消息, 通知article修改文章的配置 if(news.getArticleId() != null){ HashMap<String, Object> map = HashMap<>(); map.put("articleId", news.getArtic()); map.put("enable", news.getEnable()); kafkaTemplate.(WmNewsMessageConstaWM_NEWS_UP_OR_DOWN_TOPIC, JtoJSONString(map)); return ResponseResult.okRe(AppHttpCodeEnum.SUCCESS); } - Consumer
// Listener
@KafkaListener(topics = WmNewsMessageConstants.WM_NEWS_UP_OR_DOWN_TOPIC)
public void onMessage(String message)
{
if(StringUtils.isNotBlank(message)){
Map map = JSON.parseObject(message, Map.class);
apArticleConfigService.updateByMap(map);
}
}
// Service
public void updateByMap(Map map) {
// 0 下架, 1 上架
Object enable = map.get("enable");
boolean isDown = true;
if(enable.equals(1)){
isDown = false;
}
// 修改文章
update(Wrappers.<ApArticleConfig>lambdaUpdate().eq(ApArticleConfig::getArticleId, map.get("articleId")).
set(ApArticleConfig::getIsDown, isDown));
}
来源
黑马程序员. 黑马头条文章来源:https://www.toymoban.com/news/detail-661665.html
Gitee
https://gitee.com/yu-ba-ba-ba/leadnews文章来源地址https://www.toymoban.com/news/detail-661665.html
到了这里,关于JavaWeb_LeadNews_Day6-Kafka的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!