作者前言
🎂 ✨✨✨✨✨✨🍧🍧🍧🍧🍧🍧🍧🎂
🎂 作者介绍: 🎂🎂
🎂 🎉🎉🎉🎉🎉🎉🎉 🎂
🎂作者id:老秦包你会, 🎂
简单介绍:🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂
喜欢学习C语言和python等编程语言,是一位爱分享的博主,有兴趣的小可爱可以来互讨 🎂🎂🎂🎂🎂🎂🎂🎂
🎂个人主页::小小页面🎂
🎂gitee页面:秦大大🎂
🎂🎂🎂🎂🎂🎂🎂🎂
🎂 一个爱分享的小博主 欢迎小可爱们前来借鉴🎂
插播小知识
1.python导入sys ,sys,path.append(文件路径)的效果跟import的效果相似都可以导入python脚本文件
2.to_csv(文件名称)保存到csv文件, to_excel(文件名称)保存到xlsx文件中
SQL优化
这里的SQL优化主要是针对于数据量十分巨大时候的处理。在具体的环境,我们是需要逐步调试SQL语句,以保证运行的性能。
查询
星号(*)
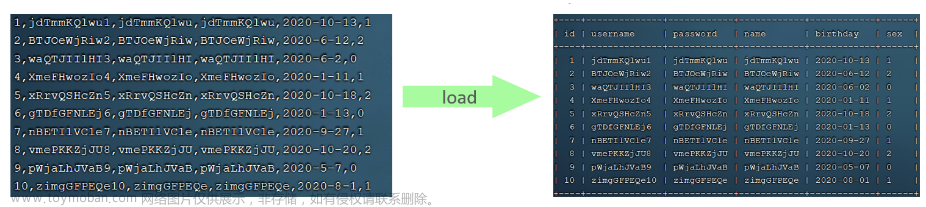
尽量避免使用select * 进行全字段的查询,为啥这么说呢?,前面我们用这个命令查询是因为数据量少,数据量很大的话一使用这个就会看不清楚,满屏的数值,想想就很可怕,所以我们尽量使用写字段的方法
select a.id,a.`name`,a.age from 学生表格1 As a;
使用*还会降低性能,我们可以理解一下,当判断出所有字段后,还要再往后判断一次是否这个表还有字段,而直接写出字段就不会判断,节省了资源,如果不理解,我们可以想象一下,数据非常大,每多做出一次判断都会影响MySQL的性能
这样写既可以让我们知道表格里面有哪些字段,
去重(尽量使用group by)
select count(1) from employees where first_name='Georgi';
select
count(1) as 剩下的Georgi数量
from
(
select
DISTINCT first_name as first_name
from
employees
where first_name='Georgi'
) as a
where
a.first_name='Georgi';
上面代码就是使用distinct去重
而我们使用group by时
select
first_name
,count(1)
from
employees
where first_name='Georgi'
group by first_name;

最终结果是一样的
如果使用python的逻辑去理解的话,distinct 是判断是否存在,
上面每个方框和下面数据对应一下
如果全为1则说明这两条数据相同,distinct 就是要一一比较然后再判断,而group by就是只要方框内的内容只要不相同就会停止判断
使用 distinct * 进行去重,如果数据量过大,会导致数据库运行效率很慢。
在SQL语句的查询中,中心点在于进一步缩小查询范围,然后找到满足条件的数据。所以在很多时
候,我们可以用冗长的SQL语句来节省数据库的运行时间。
select
id
,name
,age
from table_name
where age = 50
or age = 60
select
id
,name
,age
from table_name
where age = 50
union all
select
id
,name
,age
from table_name
where age = 60
简单理解就是我们来计算,计算机执行,我们花费时间写更多的代码来换取更多的内存空间,运行效率就会得到提升
关联查询 join
# 正常SQL数据查询获取
sql = '''
select
a.emp_no
,a.age
,a.gender
,b.dept_no
from new_employees a
join dept_emp b
on a.emp_no = b.emp_no
and b.dept_no = 'd001'
'''
Data_Dw().mysql_to_df(sql)
这里的意思就是new_employees和dept_emp通过a.emp_no = b.emp_no进行关联,关联出b.dept_no = ‘d001’
如果我们先从dept_emp表格里获取20条数据,获取主键值,再从表employees找出,
每次找出5条
sql_1 = """
select
emp_no
from
dept_emp
limit 20
"""
retur = Data_Dw().mysql_to_df(sql_1)
print(type(retur))
print(list(retur))
print(len(retur))
retur
print(retur['emp_no'])
print(list(retur['emp_no']))
NPB = 5
retur_list = list(retur['emp_no'])
retur_list
while 1:
if len(retur_list) <= NPB:
#获取表头
d_type = tuple(retur)[0]
#获取内容
sql_2 = f"""select * from employees where {d_type} in{tuple(retur_list)}"""
data = Data_Dw().mysql_to_df(sql_2)
print(data)
break
else:
# 获取表头
d_type = tuple(retur)[0]
# 获取5个数据 并输出
pop_list = list()
while len(retur_list) > 0:
if len( pop_list)< NPB:
pop_list.append(retur_list.pop())
else:
pop_tuple = tuple( pop_list)
sql_3 = f"""select * from employees where {d_type} in {pop_tuple} """
data = Data_Dw().mysql_to_df(sql_3)
print(data)
break

第一框代码是使用join的,原理相当于是一次性从许多数据 找出一部分数据,
而第二框是先在ept_emp表格里获取需要的数据,然后拆分成许多小块,然后每个小块在表employees找出,
这样写的好处是啥呢?我们想一想,我们进会场,一次进1000人,现场就会管理很好,如果一下子全部人进入,就会很混乱
在mysql里如果一下子查询许多数据就会给内存增加很大的压力。
通过python实现两张表格的关联查询
原理就是使用sql语句分别查出需要关联的内容,然后通过python关联在一起,这样可以节约mysql内存
sql_4 = """
select
emp_no
,dept_no
from
dept_emp
limit 20
"""
data_1 = Data_Dw().mysql_to_df(sql_4)
data_1
sql_4 = """
select
emp_no
,birth_date
from
employees
limit 20
"""
data_2 = Data_Dw().mysql_to_df(sql_4)
data_2
result=data_1.merge(data_2,how='inner',on='emp_no')
result["birth_date"].head(1)
merge函数构成:
参数介绍:
left:参与合并的左侧DataFrame;
right:参与合并的右侧DataFrame;
how:连接方式,有inner、left、right、outer,默认为inner;
on:指的是用于连接的列索引名称,必须存在于左右两个DataFrame中,如果没有指定且其他参数也没有指定,则以两个DataFrame列名交集作为连接键;
left_on:左侧DataFrame中用于连接键的列名,这个参数左右列名不同但代表的含义相同时非常的有 用;
right_on:右侧DataFrame中用于连接键的列名;
left_index:使用左侧DataFrame中的行索引作为连接键;
right_index:使用右侧DataFrame中的行索引作为连接键;
sort:默认为True,将合并的数据进行排序,设置为False可以提高性能;
suffixes:字符串值组成的元组,用于指定当左右DataFrame存在相同列名时在列名后面附加的后缀名称,默认为(‘_x’, ‘_y’);
copy:默认为True,总是将数据复制到数据结构中,设置为False可以提高性能;
indicator:显示合并数据中数据的来源情况。
result[“birth_date”].head(1) #查看前1条数据
删除 delete
delete from table_name where 条件
这是我们删除语句,但是这种往往不适合删除数据量很大的数据,由于服务器的运行性能的限制,我们就要考虑分段删除了,我们可以通过python语句来操控删除,
方法1
sql_5 = """
select
name
from 数据库1.学生表格1
where
name = '大佬'
"""
data_2 = Data_Dw().mysql_to_df(sql_5)
len(data_2)
while 1;
#判断是否还有数据
if len(data_2) == 0:
break
else:
sql_6 = """
delete from
数据库1.学生表格1;
where
name = '大佬'
"""
data_3 = Data_Dw().mysql_to_df(sql_5)
data_3
这个方法缺点就是每次查询都是在数据库里面进行的,很大程度上让数据库的负担加重了,如果数据量小还行,如果数据量大那就不适合了
方法2
sql_6= """
select
name
from 数据库1.学生表格1
where
name = '大佬'
"""
data_3 = Data_Dw().mysql_to_df(sql_6)
data_3["name"]
# # 获取表头
# list(data_3)
# data_list = list(data_3["name"])
# sa_tuple = list()
# CNB = 10
# while 1:
# if (len(list(data_3["name"]))) < CNB:
# sql_7 = f""" delete from 数据库1.学生表格1 where {list(data_3)[0]} in {tuple(data_3["name"])}"""
# print(Data_Dw().mysql_to_df(sql_7))
# break
# else:
# while 1:
# if len(sa_tuple) < CNB:
# sa_tuple.append(data_list.pop())
# else:
# sql_8 = f""" delete from 数据库1.学生表格1 where {list(data_3)[0]} in {tuple(sa_tuple)}"""
# print(Data_Dw().mysql_to_df(sql_8))
# break
对比以上两个方法:
方法一:
通过多次查询数据库,先确定是否存在需要删除的数据,然后进行删除。主要适用于服务器或者数据库硬件性能不足,但是本身使用频繁较低的情况。
方法二:
先圈选需要删除的数据,然后通过循环进行数据的删除。减少了数据库查询的次数,将更多的运算逻辑运用于python中。主要适用于服务器性能充沛,但是数据库已经被其他任务过多占用的情况。
这两种方法都比直接一次性删除全部数据要快很多
数据库的分表
这里的优化仅以mysql为例,不同的数据库可能会有出入
垂直分表
原理:
MySQL底层实际是将数据分页,保存在每一个16k(1.6万)的数据页上。每一次读取数据时,每一行数据都会有磁盘的IO操作。当进行数据的拆分时,每一行数据的列数会变少,表示单个数据页可以保存更多行的数据,关于磁盘的IO读写操作时间也会更少。
磁盘的IO操作是十分消耗性能的
简单理解就是通过把一张表的所有字段拆分成多个字段表,然后通过join 链接
with a as
(
select
emp_no
,birth_date
,first_name
from
employees
limit 20
),
b as
(
select
emp_no
,last_name
,hire_date
from
employees
limit 20
)
select
a.emp_no
,a.birth_date
,a.first_name
,b.last_name
,b.hire_date
from
a
join
b
on a.emp_no=b.emp_no;
这里我创建了临时表,让大家更好的知道
水平分表
无论是什么形式的水平分表,本质上都是将数据保存在结构相同但名称相似的表中,
原本的20条数据,可以将它横向拆分为两张表格保存,每一张小表格中只保存整体的一部分数据。
(在mysql中,这样的分表一般是保证每一张表的数据在500万至2000万的数据条数)
那怎么分表呢,上面的图片只是让大家明白分表的意思
ID取模分表
根据id进行简单的分表,分两张表, %2 ;分3张,%3、、、、
select * from employees where MOD(emp_no,2)=1 limit 10;
select * from employees where MOD(emp_no,2)=0 limit 10;

到这里一些小可爱就会觉得为啥不直接跟第一图的一样呢?,原因是表的数据会增加,如果直接规定前10条数据存第一张表,后10条存第二章表,那新增的数据往哪存呢,有些小可爱就会觉得再创建一张,这个做法就很麻烦,每新增数据就创建表,这样很浪费时间,
但是上面这种方法也有缺点,就是一张表存储的数据量是有限的,如果超出了容量,就得创建表,这样也很麻烦,如果一下子就创建许多张分表,又有可能会造成性能(存储性能和读取性能)浪费
ID范围分表
简单根据数据的条数进行分表。例如每一张表只保存200万条数据,每次数据的写入都先判断表格
里数据是否已经达到限制。即为当table_1中的数据已经有200万时,则向table_2中写入数据,依次类
推。当需要读取数据时,先判断emp_no的范围,小于200万则选择table_1,在200万至400万选择
table_2,在400万至600万选择table_3。
但这样的缺点在于,可能会存在某一时刻,某一张表的IO过于频繁。因为当大量数据涌入时,对于
读写操作只会作用于最新的那张表格(这里要根据具体的业务逻辑进行判断),而其他的表格只是简单
的数据读取,同样是影响数据的操作。
结合取模和范围的分表
如果ID分表要根据一张表里面数据量有多少进行分表,范围分表是给定范围进行分表,两种结合起来,一可以减少id分表带来的表不够用的情况解决了,也在一定程度上把范围分表的某个IO操作频繁的进行了分担了,
临时表不会写入数据库中不会参与计算
1、对于原始数据的处理。先采取范围分表的形式,设定每张表的数据量为200万,当一条数据进行写入
时,先判 断表格数据是否已经写满。如果已经达到数据保存上限,则新建表格。
2、如果数据没有达到储存上限,则进入下一步,对字段进行取模分表。仍然可以通过对ID进行是否能被
2整除的 操作,简单判断应该将实际数据保存在那一张表格中。
如果反过来先id分表,在范围分表也是可以的
读扩散
在分表后,如果我们想查询一些数据,是不知道id,只知道名字或者某些字段,就会把所有的表读一遍,找出这些数据,不管这些表里面有没有都要读一遍

实际的数据查询是会遍历每一张表可能存在对应数据的表。如果分表过多,有些表中即使不存在需要的数据,仍然会被检索查询。同样会导致数据库的性能损失。
为了能够减少这样的性能损失,我们可以通过一张中间表来进行过渡。
这样就可以知道哪张表有该字段,哪张表没有该字段,
注意一下,一般适用于很频繁的数据查询的表文章来源:https://www.toymoban.com/news/detail-661792.html
优点:
通过事先读取table_temp,可以获取到哪些表中存在需要的Jame数据,可以省去对多余分表的查询,提高了数据的读取速度
缺点:
加大了程序员的工作量。每次数据写入,都需要至少同步更新两张表格,加大了维护成本。而且这样的中间表只是对于特殊字段的查询处理,意味着如果这样的处理过多,同样会导致相同类型的中间表也会过多。文章来源地址https://www.toymoban.com/news/detail-661792.html
到了这里,关于MySQL数据库第十四课--------sql优化---------层层递进的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!