提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
目录
文章目录
前言
一、Jsoup是什么?
二、使用步骤
1.引入库
2.读入数据
总结
前言
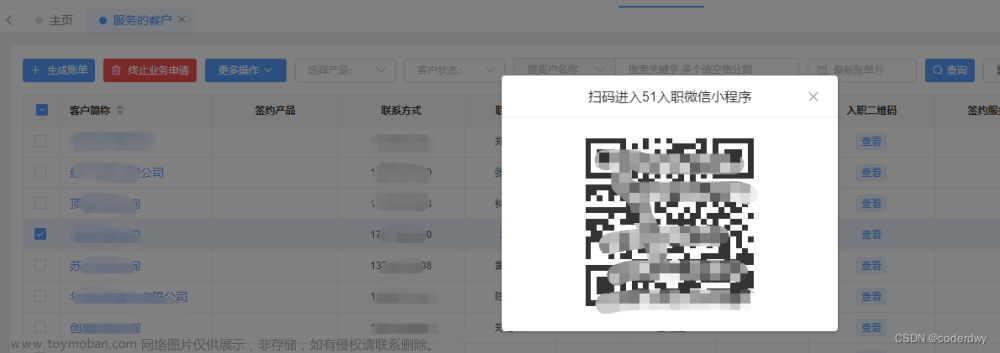
vx开发小程序使用扫一扫时不同二维码展示的东西不一样,需要进行解析
提示:以下是本篇文章正文内容,下面案例可供参考
一、Jsoup是什么?
Jsoup是一款用于解析和操作HTML文档的Java库。它提供了一组简单且强大的API,使得在Java中处理HTML文档变得非常容易。
使用Jsoup,您可以执行以下操作:
- 解析HTML文档:使用
Jsoup.parse()方法可以将HTML文档解析成一个Document对象,方便后续的操作。 -
String html = "<html><body><h1>Hello, Jsoup!</h1></body></html>"; Document doc = Jsoup.parse(html); - 选择器操作:Jsoup支持类似于CSS选择器的语法,可以通过选择器来选取具体的HTML元素。
-
Elements elements = doc.select("h1"); // 选择所有<h1>元素 Element element = doc.selectFirst("h1"); // 选择第一个<h1>元素 - 获取元素内容:可以通过
Element对象获取元素的文本内容、属性值等。 -
String text = element.text(); // 获取元素的文本内容 String attrValue = element.attr("src"); // 获取元素的属性值 - 遍历元素:可以使用循环遍历
Elements对象中的多个元素。 -
for (Element element : elements) { // 处理每个元素 } - 修改元素:可以通过
Element对象修改元素的文本内容、属性值等。 -
element.text("New Text"); // 修改元素的文本内容 element.attr("src", "new_image.jpg"); // 修改元素的属性值以上只是Jsoup的一些基本用法示例,Jsoup还提供了更多功能,如处理表单、处理URL、处理CSS样式等。您可以参考Jsoup的官方文档或其他教程来学习更多关于Jsoup的用法和功能。
二、使用步骤
1.引入库
代码如下(示例):
<!--爬取页面-->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.14.2</version>
</dependency>
2.读入数据
代码如下(示例):
public static void main(String[] args) throws IOException, InterruptedException { try { URL url = new URL("http://teshexxx"); // 设置连接超时时间 URLConnection connection = url.openConnection(); connection.setConnectTimeout(5000); // 设置读取超时时间 connection.setReadTimeout(5000); InputStream inputStream = connection.getInputStream(); BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream)); StringBuilder content = new StringBuilder(); String line; while ((line = reader.readLine()) != null) { content.append(line); } String data = parseData(content.toString()); String gasCode = extractGasCode(data); System.out.println("钢瓶编码: " + data); System.out.println("气瓶编号: " + gasCode); } catch (SocketTimeoutException e) { System.out.println("连接超时,请检查网络连接或增加超时时间"); } catch (IOException e) { e.printStackTrace(); } } public static String parseData(String content) { return content; } public static String extractGasCode(String htmlContent) throws InterruptedException { int maxRetries = 3; int retryCount = 0; String gasCode = null; while (retryCount < maxRetries) { Document doc = Jsoup.parse(htmlContent); Elements spans = doc.select("span"); if (spans.isEmpty()) { Elements trs = doc.select("tr"); for (Element tr : trs) { Elements tds = tr.select("td"); for (int i = 0; i < tds.size() - 1; i++) { Element td = tds.get(i); if (td.text().equals("气瓶编号")) { gasCode = tds.get(i + 1).text(); break; } } if (gasCode != null) { break; } } } else { for (Element span : spans) { if (span.text().equals("气瓶编号")) { gasCode = span.nextElementSibling().text(); break; } } } break; } return gasCode; }以上是可以直接在jvav代码中能获取到数据的可以使用; 下面这种则需要对url发起请求方能获取数据try { // 创建URL对象 URL url = new URL("http://mai.xxxx"); // 打开连接 HttpURLConnection conn = (HttpURLConnection) url.openConnection(); // 设置请求方法为POST conn.setRequestMethod("POST"); // 启用输入输出 conn.setDoInput(true); conn.setDoOutput(true); // 设置请求头 conn.setRequestProperty("Content-Type", "application/x-www-form-urlencoded"); // 构建请求参数 String params = "code=ASZNL2&tenant=dlh"; // 发送请求参数 byte[] postData = params.getBytes(StandardCharsets.UTF_8); conn.setRequestProperty("Content-Length", String.valueOf(postData.length)); try (DataOutputStream wr = new DataOutputStream(conn.getOutputStream())) { wr.write(postData); } // 获取响应代码 // int responseCode = conn.getResponseCode(); // System.out.println("Response Code: " + responseCode); // 读取响应内容 BufferedReader reader = new BufferedReader(new InputStreamReader(conn.getInputStream())); String line; StringBuilder response = new StringBuilder(); while ((line = reader.readLine()) != null) { response.append(line); } reader.close(); // 将StringBuilder对象转换为字符串类型 String jsonString = response.toString(); // 解析JSON JSONObject jsonObject = new JSONObject(jsonString); // 获取data字段的值 JSONObject data = jsonObject.getJSONObject("data"); // 获取gpbm字段的值 String gpbm = data.getString("gpbm"); System.out.println("gpbm: " + gpbm); // 关闭连接 conn.disconnect(); } catch (Exception e) { e.printStackTrace(); }
该处使用的url网络请求的数据。文章来源:https://www.toymoban.com/news/detail-661995.html
总结
以上就是我根据查阅资料和实际情况结合总结出来,希望对其他人有所帮助文章来源地址https://www.toymoban.com/news/detail-661995.html
到了这里,关于小程序扫描二维码获取网址,通过Jsoup进行解析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!