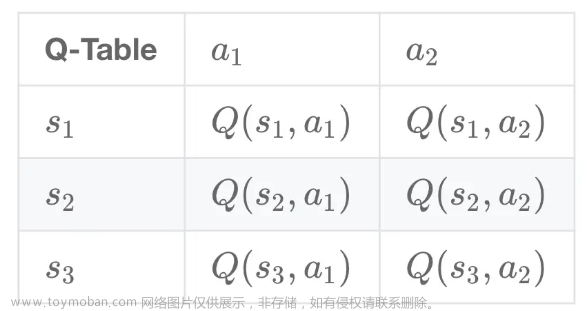
一、介绍
强化学习(RL)是一个令人兴奋的研究领域,它使机器能够通过与环境的交互来学习。在这篇博客中,我们将深入到RL的世界,并探索如何使用Python训练一个简单的机器人。在本文结束时,您将对 RL 概念有基本的了解,并能够实现自己的 RL 代理。文章来源:https://www.toymoban.com/news/detail-662277.html
设置环境:首先,让我们为机器人设置一个简单的环境。我们将创建一个2D网格世界,机器人需要从起始位置导航到目标位置,同时避开障碍物。文章来源地址https://www.toymoban.com/news/detail-662277.html
# Define the environment
gr到了这里,关于强化学习:用Python训练一个简单的机器人的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!