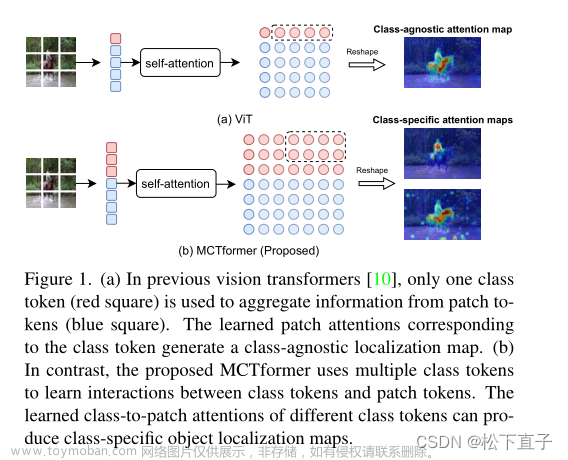
语义分割中的Transformer
Transformer 在语义分割中的使用主要有两种方式:
- patch-based Transoformer
- query-based Transformer
1 Patch-based Transformer
Transformer最初应用于NLP领域,在NLP中称每个单词为token,而在CV中就是将图像切割成不重叠的Patch序列(其实就是token)。Patch-basedTransformer实际上是模仿NLP任务,将语义分割任务视为了一个Seq2Seq的问题。
自FCN(全卷积网络)之后,语义分割模型大多数都是基于带有Encoder-Decoder结构的FCN进行设计:Encoder用于特征表示学习,Decoder用于对特征表示进行像素级分类。核心是Encoder部分:其由大量卷积层堆叠而成,在堆叠过程中考虑到计算量,会逐渐降低feature maps的空间分辨率,同时增大了后续像素点的感受野,也因此使得Encoder可以学到更为抽象的特征表示。这种设计有两个优点:
①平移等变性:给定一对空间点( i , j) ,相应的卷积权重w_i-j只关心二者的相对偏移,即i − j,而不是 i 或 j 的具体数值。这可以在有限的数据集上提升模型的泛化能力。
②局部性:通过参数共享降低了模型复杂度。
然而,CNNs难以学习长距离依赖关系,而这种关系对语义分割至关重要。
相较于传统CNN 需要很多的 decoder 堆叠来扩大感受野,进而得到高层特征,patch-based Transformer 是对全局特征的建模,将输入图像看成一个 Patch 序列,然后输入 encoder 中,自始至终保持了全局语义依赖,有效提升了分割任务的效果。
很多工作开始研究将 patch-based Transformer 和不同的Decoder进行结合。
1.1 SETR
SETR 使用 Transformer encoder 完全替代 CNN backbone,舍弃了卷积和下采样过程,将分割任务作为序列-序列的预测任务。与现有基于FCN的模型利用空洞卷积和注意力模块来增大感受野的方式不同,SETR使用transformer作为encoder,在encoder的每层中都进行全局上下文建模,完美去掉了对FCN中卷积的依赖。设计了三种不同复杂度的Decoder解决语义分割问题,来对自注意力进行深入研究:①朴素上采样 (Naive) ②渐进上采样 (PUP) ③多级特征融合 (MLA)。
但是,SETR完全采用ViT-large作为encoder有以下几个缺点:
(1) ViT-large 参数和计算量非常大,有300M+参数,这对于移动端模型是无法承受的;
(2) ViT的结构不太适合做语义分割,因为ViT是柱状结构,全程只能输出固定分辨率的feature map, 比如1/16, 这么低的分辨率对于语义分割不太友好,尤其是对轮廓等细节要求比较精细的场景。
(3) ViT的柱状结构意味着一旦增大输入图片或者缩小patch大小,计算量都会成平方级提高,对显存的负担非常大。
(4) 位置编码,ViT 用的是固定分辨率的positional embedding, 但是语义分割在测试的时候往往图片的分辨率不是固定的,这时要么对positional embedding做双线性插值,这会损害性能;要么做固定分辨率的滑动窗口测试,这样效率很低而且很不灵活。
1.2 Segformer
Segformer 使用一系列简单和有效的方法来提升 Transformer 在语义分割的效果。
重新设计了Transformer encoder:(1)对patch设计成有重叠的,保证局部连续性。(2)使用Mix FFN替代Position Embeding,解决固定分辨率的positional embeding在测试时效率低且不够灵活的问题
设计轻量级的 decoder(只包含4层 MLP):decoder的计算量和参数量可以非常非常小,从而使得整个方法运行的非常高效。
2 Query-Based Transformer
self-attention是Transformer中很关键的部分:利用输入样本自身的关系构建注意力模型。self-attention中有三个非常重要的元素:Query、Key和Value。query、key & value 的概念其实来源于推荐系统。基本原理是:给定一个 query,计算query 与 key 的相关性,然后根据query 与 key 的相关性去找到最合适的 Value。在Self-Attention 中,这里 key 和 value 都是输入序列本身的一个变换,但是 self-attention 不是为了 query 去找 value,而是根据当前 query 获取 value 的加权和。这是 self-attention 的任务使然,想要为当前输入找到一个更好的加权输出,该输出要包含所有可见的输入序列信息,而注意力就是通过权重来控制。
Query embeding是从图像输入逐渐学习的一组临时语义表示,与patch embeding不同,Query可以更“公平”地整合来自特征的信息,并自然地与集合预测损失相结合以进行后处理消除。
Query-Based Transformer可分为两个类别:
- 由检测和分割任务驱动(称为Object Queries)
- 仅由分割任务来驱动(称为Mask Embeddings)

2.1 Transformer with Object Queries
- 基于 DETR 在检测任务上预训练,再针对分割任务进行微调(图a):Panoptic DETR
- 不使用多阶段串行训练方式,并行进行检测和分割任务。常见于端到端的网络(图b):Cell-DETR & VisTR
- 混合级联网络 ,根据检测器预测的粗略区域,生成细粒度掩码,以实现精准分割(图c):QueryInst
2.2 Transformer with Mask Embeddings
一系列基于query的Transformer直接预测掩码。不同于object query,mask embeding仅由分割任务监督。如图(d)所示,两个不相交的query集并行用于不同的任务,并将box学习视为辅助损失以进一步提升预测结果准确性(ISTR、SOLQ)。对于语义分割和无框实例分割,一系列基于query的transformer直接预测掩码,而不需要box分支的帮助,如图(e)所示(Max-DeepLab、Segmenter)。
与传统的在像素级预测掩码的语义分割方法不同,Maskformer将语义分割任务重新定义为掩码预测问题,并将此输出格式启用到基于Query的Transformer。与MaxDeepLab不同,Maskformer利用了一个简单的Transformer解码器,没有多余的连接,以及一个用于重叠二进制掩码选择的sigmoid激活。它不仅在大类语义分割数据集上优于目前的每像素分类SOTA,并且还在全景分割任务中刷新了SOTA。
3. 思考
1. Transformer模型如何跨越语言和视觉的鸿沟
Transformer最初是为机器翻译任务设计的。句子中的每个单词都可以看作高级语义信息的基本单位,这些词可以嵌入到地位向量空间的表示中。对于视觉任务,图像中的像素不能携带语义信息,所以在视觉任务中使用Transformer的关键是建立图像到向量的转换,并有效地保持图像的特征。
例如,ViT将图像的低维信息直接转换为patch embeding,而CoAtNet使用卷积来提取高维特征并减少了冗余。
2. Transformer,自注意力和卷积神经网络之间的关系
从CNN的角度来看,其归纳偏置主要表现为局部性、平移不变性、权重共享、稀疏连接等。这种简单的卷积核可以在低层语义处理中有效地执行模板匹配,但由于过度偏置,其上界低于Transformers。(“归纳偏置”可理解为贝叶斯学习中的先验概率)
从自注意力机制的角度来看,当采用足够数量的头时,它们理论上可以表达任何卷积层。这种全注意力操作可以结合局部级别和全局级别的注意力,并根据特征关系动态生成注意力权重。但是,由于精度低,计算成本高,它的实用性比 SOTA CNN 低。
从Transformer的角度看,当在没有残差连接或FFN的深层训练时,自注意力层表现出对“令牌均匀性(token uniformity)”很强的归纳偏置。得出的结论是,**Transformer 由两个关键组件组成:一个 self-attention 层聚合了 token 的关系,一个 position-wise FFN(前馈神经网络) 提取了输入的特征。**尽管 Transformer 具有强大的全局建模能力,但是卷积可以有效处理低级特征,增强 Transformer 的局部性,并通过填充附加位置特征。
3. 针对性的Encoder和Decoder
(1)对于语义分割,特征提取非常重要,Transformer已经在分类上证明了比CNN更强大的特征提取能力。但是分类和分割还是有一定的GAP, 因此如何设计对分割友好的更好的Transformer结构,还可以继续研究。文章来源:https://www.toymoban.com/news/detail-662398.html
(2)有了很好的特征,decoder该如何设计才能进一步提高性能?
在CNN encoder中相对复杂的decoder很重要且很有意义。但是,在Segformer中仅用了一个很简单的MLP decoder就取得了不错的效果,为什么呢?
有效感受野:在卷积计算时,实际有效的感受野区域。一般而言,特征点有效感受野要小于实际感受野。其有效性,类高斯分布向边缘递减,且不同的激活函数对有效感受野影响不同。
**对于语义分割来说最重要的问题就是如何增大感受野。**之前无数的工作也都是在研究这方面。首先对于CNN encoder来说,有效感受野是比较小且局部的,所以需要一些decoder 的设计来增大有效感受野,比如ASPP (Atrous Spatial Pyramid Pooling, 空洞空间卷积池化金字塔)利用了不同大小的空洞卷积来实现这一目的。
但是对于Transformer encoder来说,由于 self-attention有效感受野变得非常大,因此decoder 不需要更多操作来提高感受野。但是较大的感受野需要非常多的计算量,这就限制了它的应用范围。因此,未来如何针对性的设计更好的decoder也比较值得探索。文章来源地址https://www.toymoban.com/news/detail-662398.html
4. 下一步计划
- 通过阅读相关论文进一步理解query-based
- 代码复现patch-based和query-based经典模型,从细节上深入理解
- 追踪Transformer在伪装目标语义分割中的应用。比较在伪装目标上进行语义分割时与通用目标分割的异同
到了这里,关于语义分割任务中的Transformer的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!