Python多线程与线程池
一、Python多线程
在进行复杂的计算或处理大量数据时,可以通过创建多个线程来同时执行多个任务,从而提高程序的执行效率。这种技术称为多线程编程。
1.1 线程简介
线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。
1.2 Python中的多线程
Python中的threading模块提供了对线程的支持。使用threading模块创建线程,直接从threading.Thread继承,然后重写__init__方法和run方法。
import threading
class MyThread(threading.Thread):
def __init__(self, n):
super(MyThread, self).__init__()
self.n = n
def run(self):
print('running task', self.n)
t1 = MyThread(1)
t2 = MyThread(2)
t1.start()
t2.start()

1.3 GIL限制
由于Python解释器设计中的全局解释器锁(Global Interpreter Lock,GIL)的存在,使得Python的多线程并不能利用多核优势。GIL是计算机程序设计语言解释器用于同步线程的工具,使得任何时刻只有一个线程在执行,即使在多核CPU平台上,Python的线程也无法同时执行。

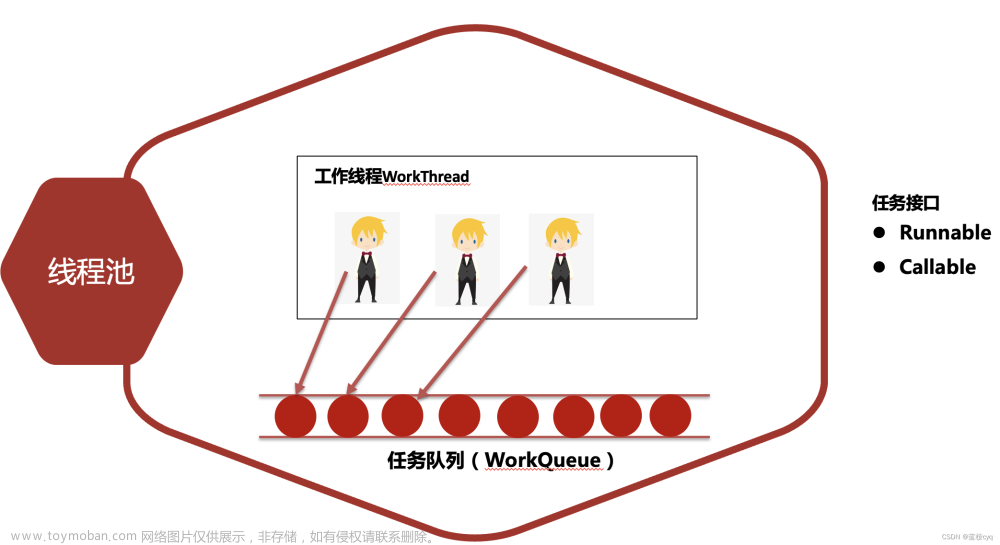
二、线程池
线程池是一种基于池化思想管理线程的工具。在开始任务时不再重新创建新的线程,而是直接从线程池中获取一个空闲线程来执行。如果线程池中没有空闲线程,新的任务就会等待(排队),直到有线程空闲。当任务执行完毕后,线程并不立即销毁,而是返回线程池等待下次被利用。
2.1 Python中的线程池
Python的concurrent.futures模块提供了高级别的异步执行封装,包括线程池ThreadPoolExecutor和进程池ProcessPoolExecutor,它们都是Executor的子类。
from concurrent.futures import ThreadPoolExecutor
def func(n):
print(n)
with ThreadPoolExecutor(max_workers=4) as executor:
executor.map(func, range(1,5))
其中max_workers参数表示线程池中最多可以同时运行的线程数量。

线程池优势
Python线程池具有以下优势:
-
控制并发数:Python的线程池可以控制系统中运行的线程数量,避免了因为创建过多线程而导致系统资源耗尽。
-
提高性能:通过复用已经创建的线程,可以避免频繁地创建和销毁线程所带来的性能开销。
-
简化代码:使用线程池,我们只需要将任务提交给线程池,无需手动管理每个线程的生命周期。
-
异步处理:Python的线程池提供了异步处理任务的能力。当我们提交任务给线程池后,线程池会在后台进行处理,不会阻塞主程序的执行。
-
调度方便:线程池还提供了一些调度功能,如定时执行、周期执行等。
-
任务队列:线程池内部维护了一个任务队列,如果线程池中的所有线程都在忙,新来的任务会被放入队列中等待执行,这样可以保证所有提交给线程池的任务都会被执行,不会丢失。
总的来说,使用Python线程池可以简化并发编程的复杂性,提高程序的性能和稳定性。
三、代码分析
import requests
from requests.models import PreparedRequest
import json
import concurrent.futures
def get_score_models(url):
url_score = "https://bizapi.csdn.net/trends/api/v1/get-article-score"
headers = {
"accept": "application/json, text/plain, */*",
"x-ca-key": "203930474",
"x-ca-nonce": "22cd11a0-760a-45c1-8089-14e53123a852",
"x-ca-signature": "RaEczPkQ22Ep/k9/AI737gCtn8qX67CV/uGdhQiPIdQ=",
"x-ca-signature-headers": "x-ca-key,x-ca-nonce",
"x-ca-signed-content-type": "multipart/form-data"
}
data = {"url": url}
response = send_request(url_score, data, headers)
data1 = response.json()
score_model = data1["data"]
return score_model
def send_request(url, data, headers):
session = requests.Session()
prepared_request = PreparedRequest()
prepared_request.prepare(method='POST', url=url,
headers=headers, data=data)
return session.send(prepared_request)
def process_article_json(article):
# score_model = get_score_models(article['article_url'])
score_model = get_score_models(article['url'])
article['article_score'] = score_model['score']
print(article["url"])
return article
if __name__ == '__main__':
# 读取articles.json文件
with open('articles.json', 'r') as f:
articles = json.load(f)
# 创建一个 ThreadPoolExecutor 实例,max_workers 表示线程池中最多可以同时运行的线程数量
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
# 使用 map 函数将 process_article_json 应用到每个元素,并在多线程环境下并行处理
processed_articles = list(executor.map(process_article_json, articles))
# 保存处理后的结果到新的JSON文件
output_file = 'processed_articles.json'
with open(output_file, 'w') as f:
json.dump(processed_articles, f, ensure_ascii=False, indent=4)
import requests
from requests.models import PreparedRequest
import json
import concurrent.futures
def get_score_models(url):
url_score = “https://bizapi.csdn.net/trends/api/v1/get-article-score”
headers = {
“accept”: “application/json, text/plain, /”,
“x-ca-key”: “203930474”,
“x-ca-nonce”: “22cd11a0-760a-45c1-8089-14e53123a852”,
“x-ca-signature”: “RaEczPkQ22Ep/k9/AI737gCtn8qX67CV/uGdhQiPIdQ=”,
“x-ca-signature-headers”: “x-ca-key,x-ca-nonce”,
“x-ca-signed-content-type”: “multipart/form-data”
}
data = {“url”: url}
response = send_request(url_score, data, headers)
data1 = response.json()
score_model = data1[“data”]
return score_model
def send_request(url, data, headers):
session = requests.Session()
prepared_request = PreparedRequest()
prepared_request.prepare(method=‘POST’, url=url,
headers=headers, data=data)
return session.send(prepared_request)
def process_article_json(article):
# score_model = get_score_models(article[‘article_url’])
score_model = get_score_models(article[‘url’])
article[‘article_score’] = score_model[‘score’]
print(article[“url”])
return article
if name == ‘main’:
# 读取articles.json文件
with open(‘articles.json’, ‘r’) as f:
articles = json.load(f)
# 创建一个 ThreadPoolExecutor 实例,max_workers 表示线程池中最多可以同时运行的线程数量
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
# 使用 map 函数将 process_article_json 应用到每个元素,并在多线程环境下并行处理
processed_articles = list(executor.map(process_article_json, articles))
# 保存处理后的结果到新的JSON文件
output_file = ‘processed_articles.json’
with open(output_file, ‘w’) as f:
json.dump(processed_articles, f, ensure_ascii=False, indent=4)

以上给出的代码片段主要涉及到的是线程池的使用。具体来说,首先从一个名为articles.json的文件中读取文章信息,然后利用线程池并发地获取每篇文章的评分,并将评分添加到文章信息中,最后将处理后的文章信息保存到新的JSON文件。
代码的主要部分如下:
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
processed_articles = list(executor.map(process_article_json, articles))

这里,首先创建了一个ThreadPoolExecutor实例,并设置最大并发线程数为5。然后使用executor.map()函数将process_article_json函数应用到articles列表的每个元素上,这样就可以在多线程环境下并行处理每篇文章了。由于executor.map()函数返回的是一个迭代器,因此需要用list()函数将其转换为列表。
这种方式可以有效地提高处理大量文章信息的效率,特别是当获取文章评分的过程涉及到网络请求等I/O操作时,通过线程池并发处理可以显著减少总的处理时间。

四、参考资料
- Python官方文档:threading — Thread-based parallelism
- Python官方文档:concurrent.futures — Launching parallel tasks
- Python线程池使用示例
- Python多线程与GIL
- 3. 爬取自己CSDN博客列表(分页查询)(网站反爬虫策略,需要在代码中添加合适的请求头User-Agent,否则response返回空)
20230817
with concurrent.futures.ThreadPoolExecutor(max_workers=20) as executor:
future_to_ip = {executor.submit(check_ping, ip): ip for ip in ips}
for future in concurrent.futures.as_completed(future_to_ip):
ip = future_to_ip[future]
try:
if future.result():
print(f"IP [{ip}] 可以ping通")
return True
except Exception as exc:
print('%r generated an exception: %s' % (ip, exc))
这段代码是使用Python的concurrent.futures模块创建一个线程池来并发执行任务。每个任务都在一个独立的线程中运行,最大并发线程数由max_workers参数指定。
-
with concurrent.futures.ThreadPoolExecutor(max_workers=20) as executor:这一行创建了一个线程池执行器(ThreadPoolExecutor),最大工作线程数量为20。
-
future_to_ip = {executor.submit(check_ping, ip): ip for ip in ips}这一行通过线程池执行器提交任务。每个任务都是对函数
check_ping的调用,并传入一个IP地址。这会返回一个Future对象,表示待完成的操作。然后将每个Future对象与对应的IP地址映射到字典future_to_ip中。 -
for future in concurrent.futures.as_completed(future_to_ip):这一行遍历所有已完成的Future对象。
as_completed函数返回一个迭代器,当一个Future对象完成时,它就会产生一个新的值。for future in concurrent.futures.as_completed(future_to_ip)这段代码是阻塞等待的。这个语句会迭代返回已经完成的Future实例。如果没有完成的Future实例,它就会等待,直到有Future实例完成。concurrent.futures.as_completed函数返回一个迭代器,这个迭代器会在每次Future实例完成(无论成功还是失败)时产生该Future。所以,在这个循环中,你可以立即处理已完成的任务,而不必等待所有任务都完成。但是,如果所有的Future都还未完成,那么这个循环就会阻塞,直到至少有一个Future完成。 -
ip = future_to_ip[future]这一行从字典中获取与当前Future对象对应的IP地址。
-
if future.result():这一行获取Future对象的结果。如果
check_ping函数返回True,那么就打印出可以ping通的IP地址,并返回True。文章来源:https://www.toymoban.com/news/detail-662499.html -
如果在获取Future对象的结果时发生异常,那么就捕获这个异常,并打印出引起异常的IP地址和异常信息。文章来源地址https://www.toymoban.com/news/detail-662499.html
到了这里,关于Python多线程与线程池(python线程池ThreadPoolExecutor)concurrent.futures高级别异步执行封装的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!