引言
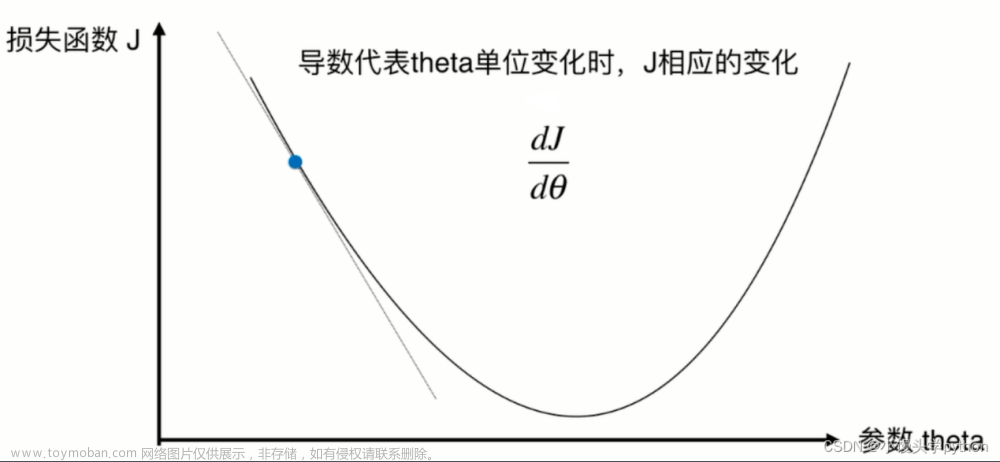
上一节介绍并证明了:梯度下降法在强凸函数上的收敛速度满足
Q
\mathcal Q
Q-线性收敛。
本节将介绍:在更强的条件下:函数
f
(
⋅
)
f(\cdot)
f(⋅)在其定义域内二阶可微,梯度下降法在
f
(
⋅
)
f(\cdot)
f(⋅)上的收敛速度存在什么样的结论。
回顾:梯度下降法在强凸函数的收敛性
关于梯度下降法在
m
m
m-强凸函数上的收敛性定理表示如下:
条件:
- 函数 f ( ⋅ ) f(\cdot) f(⋅)向下有界,在其定义域内可微,并且 f ( ⋅ ) f(\cdot) f(⋅)是 m m m-强凸函数;
- 关于 f ( ⋅ ) f(\cdot) f(⋅)的梯度函数 ∇ f ( ⋅ ) \nabla f(\cdot) ∇f(⋅)满足 L \mathcal L L-利普希兹连续;
- 梯度下降法迭代过程中,其步长 α k \alpha_k αk存在明确的约束范围: α k ∈ ( 0 , 2 L + m ) \begin{aligned}\alpha_k \in \left(0,\frac{2}{\mathcal L+ m} \right)\end{aligned} αk∈(0,L+m2);
结论:
数值解序列
{
x
k
}
k
=
0
∞
\{x_k\}_{k=0}^{\infty}
{xk}k=0∞以
Q
\mathcal Q
Q-线性收敛的收敛速度收敛于最优数值解
x
∗
x^*
x∗。
根据
Q
\mathcal Q
Q-线性收敛的定义,关于结论的证明可转化为下述公式成立:
∣
∣
x
k
+
1
−
x
∗
∣
∣
∣
∣
x
k
−
x
∗
∣
∣
≤
a
∈
(
0
,
1
)
k
=
1
,
2
,
3
,
⋯
\begin{aligned}\frac{||x_{k+1} - x^*||}{||x_k - x^*||} \leq a \in (0,1) \quad k = 1,2,3,\cdots\end{aligned}
∣∣xk−x∗∣∣∣∣xk+1−x∗∣∣≤a∈(0,1)k=1,2,3,⋯
其证明过程见上一节——梯度下降法在强凸函数上的收敛性证明,这里不再赘述。最终我们得证:
∣
∣
x
k
−
α
⋅
∇
f
(
x
k
)
−
x
∗
∣
∣
∣
∣
x
k
−
x
∗
∣
∣
≤
1
−
α
⋅
2
L
m
L
+
m
\begin{aligned}\frac{||x_k - \alpha \cdot \nabla f(x_k) - x^*||}{||x_k- x^*||} \leq \sqrt{1 - \alpha \cdot \frac{2\mathcal L m}{\mathcal L + m}}\end{aligned}
∣∣xk−x∗∣∣∣∣xk−α⋅∇f(xk)−x∗∣∣≤1−α⋅L+m2Lm
并有:
1
−
α
⋅
2
L
m
L
+
m
∈
(
0
,
1
)
\begin{aligned}\sqrt{1 - \alpha \cdot \frac{2\mathcal L m}{\mathcal L + m}}\end{aligned} \in (0,1)
1−α⋅L+m2Lm∈(0,1)恒成立。
二阶可微——梯度下降法在强凸函数的收敛性推论
-
如果函数 f ( ⋅ ) f(\cdot) f(⋅)向下有界,并且 f ( ⋅ ) f(\cdot) f(⋅)是 m m m-强凸函数,在其定义域内二阶可微。在凸函数 VS \text{VS} VS强凸函数中介绍的:根据强凸函数的二阶条件, f ( ⋅ ) f(\cdot) f(⋅)对应的 Hessian Matrix ⇒ ∇ 2 f ( ⋅ ) \text{Hessian Matrix} \Rightarrow \nabla^2 f(\cdot) Hessian Matrix⇒∇2f(⋅)存在,并且必然有:
其中I \mathcal I I是单位矩阵。
∇ 2 f ( ⋅ ) ≽ m ⋅ I \nabla^2 f(\cdot) \succcurlyeq m \cdot \mathcal I ∇2f(⋅)≽m⋅I
也就是说: ∇ 2 f ( ⋅ ) − m ⋅ I ≽ 0 \nabla^2 f(\cdot) - m \cdot \mathcal I \succcurlyeq 0 ∇2f(⋅)−m⋅I≽0,即:矩阵 ∇ 2 f ( ⋅ ) − m ⋅ I \nabla^2 f(\cdot) - m \cdot \mathcal I ∇2f(⋅)−m⋅I是半正定矩阵。 -
继续观察条件:如果梯度函数 ∇ f ( ⋅ ) \nabla f(\cdot) ∇f(⋅)满足 L \mathcal L L-利普希兹连续,并且 f ( ⋅ ) f(\cdot) f(⋅)二阶可微,则有:
使用拉格朗日中值定理进行表示:∀ x , y ∈ R n , ∃ ξ ∈ ( x , y ) ⇒ ∣ ∣ ∇ 2 f ( ξ ) ∣ ∣ = ∣ ∣ ∇ f ( x ) − ∇ f ( y ) ∣ ∣ ∣ ∣ x − y ∣ ∣ \begin{aligned}\forall x,y \in \mathbb R^n,\exist \xi \in (x,y) \Rightarrow ||\nabla^2 f(\xi)|| = \frac{||\nabla f(x) - \nabla f(y)||}{||x - y||}\end{aligned} ∀x,y∈Rn,∃ξ∈(x,y)⇒∣∣∇2f(ξ)∣∣=∣∣x−y∣∣∣∣∇f(x)−∇f(y)∣∣
∣ ∣ ∇ 2 f ( ⋅ ) ∣ ∣ ≤ L ||\nabla^2 f(\cdot)|| \leq \mathcal L ∣∣∇2f(⋅)∣∣≤L
将范数符号去掉,可表示为:
− L ⋅ I ≼ ∇ 2 f ( ⋅ ) ≼ L ⋅ I -\mathcal L \cdot \mathcal I \preccurlyeq \nabla^2 f(\cdot) \preccurlyeq\mathcal L \cdot \mathcal I −L⋅I≼∇2f(⋅)≼L⋅I
但又由于 f ( ⋅ ) f(\cdot) f(⋅)是 m m m-强凸函数的性质,因而 ∇ 2 f ( ⋅ ) \nabla^2 f(\cdot) ∇2f(⋅)存在更强的下界: m ⋅ I ≥ − L ⋅ I m \cdot \mathcal I \geq -\mathcal L \cdot \mathcal I m⋅I≥−L⋅I,因而只需认知它的上界即可:
∇ 2 f ( ⋅ ) ≼ L ⋅ I \nabla^2 f(\cdot) \preccurlyeq\mathcal L \cdot \mathcal I ∇2f(⋅)≼L⋅I
也就是说: L ⋅ I − ∇ 2 f ( ⋅ ) ≽ 0 \mathcal L \cdot \mathcal I - \nabla^2 f(\cdot) \succcurlyeq 0 L⋅I−∇2f(⋅)≽0,即:矩阵 L ⋅ I − ∇ 2 f ( ⋅ ) \mathcal L \cdot \mathcal I - \nabla^2 f(\cdot) L⋅I−∇2f(⋅)是半正定矩阵。
将上述两个结论合并,有:
m ⋅ I ≼ ∇ 2 f ( ⋅ ) ≼ L ⋅ I m \cdot \mathcal I\preccurlyeq \nabla^2 f(\cdot) \preccurlyeq \mathcal L \cdot \mathcal I m⋅I≼∇2f(⋅)≼L⋅I
继续观察
∇
2
f
(
⋅
)
\nabla^2 f(\cdot)
∇2f(⋅),由于
∇
2
f
(
⋅
)
≽
m
⋅
I
\nabla^2 f(\cdot) \succcurlyeq m\cdot \mathcal I
∇2f(⋅)≽m⋅I且
m
>
0
m > 0
m>0,因此
∇
2
f
(
⋅
)
\nabla^2 f(\cdot)
∇2f(⋅)自身不仅是一个实对称矩阵,并且还是一个正定矩阵。因而可以对
∇
2
f
(
⋅
)
\nabla^2 f(\cdot)
∇2f(⋅)进行特征值分解:其中
λ
1
,
λ
2
,
⋯
,
λ
n
\lambda_1,\lambda_2,\cdots,\lambda_n
λ1,λ2,⋯,λn表示
Hessian Matrix
:
[
∇
2
f
(
⋅
)
]
n
×
n
\text{Hessian Matrix} :[\nabla^2 f(\cdot)]_{n \times n}
Hessian Matrix:[∇2f(⋅)]n×n的
n
n
n个特征值。而
n
n
n表示特征空间维数,与
x
,
y
∈
R
n
x,y \in \mathbb R^n
x,y∈Rn是同一个
n
n
n。
∇
2
f
(
⋅
)
=
Q
Λ
Q
−
1
=
Q
(
λ
1
λ
2
⋱
λ
n
)
Q
−
1
\nabla^2 f(\cdot) = \mathcal Q \Lambda \mathcal Q^{-1} = \mathcal Q \begin{pmatrix} \lambda_1 &\quad&\quad&\quad \\ \quad &\lambda_2& \quad&\quad \\ \quad &\quad& \ddots&\quad \\ \quad & \quad& \quad & \lambda_n \end{pmatrix}\mathcal Q^{-1}
∇2f(⋅)=QΛQ−1=Q
λ1λ2⋱λn
Q−1
假设对角矩阵
Λ
\Lambda
Λ中的特征值按照大到小的顺序排列:在降维——最大投影方差角度中对特征值的大小关系进行描述过。可以将
λ
1
\lambda_1
λ1对应的特征向量视作第一主成分,后续以此类推。
λ
m
a
x
=
λ
1
≥
λ
2
≥
λ
3
≥
⋯
≥
λ
n
=
λ
m
i
n
\lambda_{max} = \lambda_1 \geq \lambda_2 \geq \lambda_3 \geq \cdots \geq \lambda_n = \lambda_{min}
λmax=λ1≥λ2≥λ3≥⋯≥λn=λmin
- 观察矩阵:
∇
2
f
(
⋅
)
−
m
⋅
I
\nabla^2 f(\cdot) - m\cdot \mathcal I
∇2f(⋅)−m⋅I,将特征值分解结果代入,有:
由于单位矩阵I = Q Q − 1 \mathcal I = \mathcal Q \mathcal Q^{-1} I=QQ−1,因此m ⋅ I = Q m Q − 1 m \cdot \mathcal I = \mathcal Q m \mathcal Q^{-1} m⋅I=QmQ−1
∇ 2 f ( ⋅ ) − m ⋅ I = Q Λ Q − 1 − Q m Q − 1 = Q ( λ 1 − m λ 2 − m ⋱ λ n − m ) Q − 1 \nabla^2 f(\cdot) - m\cdot \mathcal I = \mathcal Q \Lambda \mathcal Q^{-1} - \mathcal Q m \mathcal Q^{-1} = \mathcal Q\begin{pmatrix} \lambda_1-m &\quad&\quad&\quad \\ \quad &\lambda_2-m& \quad&\quad \\ \quad &\quad& \ddots&\quad \\ \quad & \quad& \quad & \lambda_n-m \end{pmatrix} \mathcal Q^{-1} ∇2f(⋅)−m⋅I=QΛQ−1−QmQ−1=Q λ1−mλ2−m⋱λn−m Q−1
由于矩阵 ∇ 2 f ( ⋅ ) − m ⋅ I \nabla^2 f(\cdot) - m\cdot \mathcal I ∇2f(⋅)−m⋅I是半正定矩阵,因而必然有:
λ i − m ≥ 0 i = 1 , 2 , ⋯ , n \lambda_i - m \geq 0 \quad i=1,2,\cdots,n λi−m≥0i=1,2,⋯,n
也就是说: λ m i n − m ≥ 0 ⇒ λ m i n ≥ m \lambda_{min} - m \geq 0 \Rightarrow \lambda_{min} \geq m λmin−m≥0⇒λmin≥m - 同理,观察矩阵:
L
⋅
I
−
∇
2
f
(
⋅
)
\mathcal L \cdot \mathcal I - \nabla^2 f(\cdot)
L⋅I−∇2f(⋅),必然有:
{ L ⋅ I − ∇ 2 f ( ⋅ ) = Q ( L − λ 1 L − λ 2 ⋱ L − λ n ) Q − 1 L − λ i ≥ 0 i = 1 , 2 , ⋯ , m L − λ m a x ≥ 0 ⇒ λ m a x ≤ L \begin{cases} \begin{aligned} & \mathcal L \cdot \mathcal I - \nabla^2 f(\cdot) = \mathcal Q\begin{pmatrix} \mathcal L - \lambda_1 &\quad&\quad&\quad \\ \quad &\mathcal L - \lambda_2& \quad&\quad \\ \quad &\quad& \ddots&\quad \\ \quad & \quad& \quad & \mathcal L - \lambda_n \end{pmatrix} \mathcal Q^{-1} \\ & \mathcal L - \lambda_i \geq 0 \quad i=1,2,\cdots,m \\ & \mathcal L - \lambda_{max} \geq 0 \Rightarrow \lambda_{max} \leq \mathcal L \end{aligned} \end{cases} ⎩ ⎨ ⎧L⋅I−∇2f(⋅)=Q L−λ1L−λ2⋱L−λn Q−1L−λi≥0i=1,2,⋯,mL−λmax≥0⇒λmax≤L
对上述大小关系进行整理,最终有:
0
<
m
≤
λ
m
i
n
≤
λ
m
a
x
≤
L
0 < m \leq \lambda_{min} \leq \lambda_{max} \leq \mathcal L
0<m≤λmin≤λmax≤L
回顾上一节——梯度下降法在强凸函数上的收敛性证明过程中,关于辅助函数
G
(
⋅
)
\mathcal G(\cdot)
G(⋅)的梯度
∇
G
(
⋅
)
\nabla \mathcal G(\cdot)
∇G(⋅)满足余强制性时,有如下式子成立:
[
∇
G
(
x
)
−
∇
G
(
y
)
]
T
(
x
−
y
)
≥
1
L
−
m
∣
∣
∇
G
(
x
)
−
∇
G
(
y
)
∣
∣
2
[\nabla \mathcal G(x) - \nabla \mathcal G(y)]^T(x - y) \geq \frac{1}{\mathcal L - m} ||\nabla \mathcal G(x) - \nabla \mathcal G(y)||^2
[∇G(x)−∇G(y)]T(x−y)≥L−m1∣∣∇G(x)−∇G(y)∣∣2
当时我们对
L
,
m
\mathcal L,m
L,m之间的大小关系仅限于
L
≥
m
\mathcal L \geq m
L≥m,但一旦二阶可微的函数
f
(
⋅
)
f(\cdot)
f(⋅)被确定,那么对应的
Hessian Matrix
⇒
∇
2
f
(
⋅
)
\text{Hessian Matrix} \Rightarrow \nabla^2 f(\cdot)
Hessian Matrix⇒∇2f(⋅)以及
λ
m
a
x
,
λ
m
i
n
\lambda_{max},\lambda_{min}
λmax,λmin都是被确定的。也就是说:关于常数
L
,
m
\mathcal L,m
L,m满足:
0
<
m
≤
λ
m
i
n
≤
λ
m
a
x
≤
L
0 < m \leq \lambda_{min} \leq \lambda_{max} \leq \mathcal L
0<m≤λmin≤λmax≤L,才有该函数
f
(
⋅
)
f(\cdot)
f(⋅)满足
L
\mathcal L
L-利普希兹连续,以及
m
m
m-强凸函数的条件。
如果令: m = λ m i n ; L = λ m a x ; α = 1 L \begin{aligned}m = \lambda_{min};\mathcal L = \lambda_{max};\alpha = \frac{1}{\mathcal L}\end{aligned} m=λmin;L=λmax;α=L1,这相当于对 L \mathcal L L-利普希兹连续、 m m m-强凸函数两个条件进行了更严苛的约束,继续对上述 Q \mathcal Q Q-线性收敛公式: ∣ ∣ x k − α ⋅ ∇ f ( x k ) − x ∗ ∣ ∣ ∣ ∣ x k − x ∗ ∣ ∣ ≤ 1 − α ⋅ 2 L m L + m \begin{aligned}\frac{||x_k - \alpha \cdot \nabla f(x_k) - x^*||}{||x_k- x^*||} \leq \sqrt{1 - \alpha \cdot \frac{2\mathcal L m}{\mathcal L + m}}\end{aligned} ∣∣xk−x∗∣∣∣∣xk−α⋅∇f(xk)−x∗∣∣≤1−α⋅L+m2Lm进行化简:
-
关于步长变量α \alpha α的取值,我们将L \mathcal L L-利普希兹连续条件下的最优步长 1 L \begin{aligned}\frac{1}{\mathcal L}\end{aligned} L1代入其中。关于最优步长的推导过程详见二次上界引理,这里不再赘述。
0 < 1 L = 2 L + L ≤ 2 L + m L > 0 ; L ≥ m \begin{aligned}0 < \frac{1}{\mathcal L} = \frac{2}{\mathcal L + \mathcal L} \leq \frac{2}{\mathcal L + m} \quad \mathcal L>0;\mathcal L\geq m\end{aligned} 0<L1=L+L2≤L+m2L>0;L≥m -
由于条件中自身存在关于步长的约束:α ∈ ( 0 , 2 L + m ) \begin{aligned}\alpha \in \left(0,\frac{2}{\mathcal L + m}\right)\end{aligned} α∈(0,L+m2),需要观察一下1 L \begin{aligned}\frac{1}{\mathcal L}\end{aligned} L1是否位于该范围内见上式~。
∣
∣
x
k
−
α
⋅
∇
f
(
x
k
)
−
x
∗
∣
∣
∣
∣
x
k
−
x
∗
∣
∣
≤
1
−
α
⋅
2
L
m
L
+
m
=
1
−
1
L
⋅
2
L
m
L
+
m
=
L
−
m
L
+
m
=
λ
m
a
x
−
λ
m
i
n
λ
m
a
x
+
λ
m
i
n
\begin{aligned} \frac{||x_k - \alpha \cdot \nabla f(x_k) - x^*||}{||x_k- x^*||} & \leq \sqrt{1 - \alpha \cdot \frac{2\mathcal L m}{\mathcal L + m}} \\ & = \sqrt{1 - \frac{1}{\mathcal L} \cdot \frac{2 \mathcal L m}{\mathcal L + m}} \\ & = \sqrt{\frac{\mathcal L - m}{\mathcal L + m}} = \sqrt{\frac{\lambda_{max} - \lambda_{min}}{\lambda_{max} + \lambda_{min}}} \end{aligned}
∣∣xk−x∗∣∣∣∣xk−α⋅∇f(xk)−x∗∣∣≤1−α⋅L+m2Lm=1−L1⋅L+m2Lm=L+mL−m=λmax+λminλmax−λmin
将根号内分子、分母同时除以
λ
m
i
n
\lambda_{min}
λmin:
-
其中λ m a x λ m i n \begin{aligned}\frac{\lambda_{max}}{\lambda_{min}}\end{aligned} λminλmax被称作Hessian Matrix ⇒ ∇ 2 f ( ⋅ ) \text{Hessian Matrix} \Rightarrow \nabla^2 f(\cdot) Hessian Matrix⇒∇2f(⋅)的条件数 ( Condition Number ) (\text{Condition Number}) (Condition Number),记作K [ ∇ 2 f ( ⋅ ) ] \mathcal K[\nabla^2 f(\cdot)] K[∇2f(⋅)]。这里并不关注它的性质,仅从推倒的角度观察K [ ∇ 2 f ( ⋅ ) ] \mathcal K [\nabla^2 f(\cdot)] K[∇2f(⋅)]变化对收敛速度的影响。这里推荐一篇关于条件数的文章,见文章末尾链接。 -
分子、分母同时除以K [ ∇ 2 f ( ⋅ ) ] \mathcal K[\nabla^2 f(\cdot)] K[∇2f(⋅)]。
∣ ∣ x k − α ⋅ ∇ f ( x k ) − x ∗ ∣ ∣ ∣ ∣ x k − x ∗ ∣ ∣ ≤ λ m a x λ m i n − 1 λ max λ m i n + 1 = K [ ∇ 2 f ( ⋅ ) ] − 1 K [ ∇ 2 f ( ⋅ ) ] + 1 = 1 − 1 K [ ∇ 2 f ( ⋅ ) ] 1 + 1 K [ ∇ 2 f ( ⋅ ) ] \begin{aligned}\frac{||x_k - \alpha \cdot \nabla f(x_k) - x^*||}{||x_k- x^*||} & \leq \sqrt{\frac{\frac{\lambda_{max}}{\lambda_{min}} - 1}{\frac{\lambda_{\max}}{\lambda_{min}} + 1}} \\ & = \sqrt{\frac{\mathcal K [\nabla^2 f(\cdot)] - 1}{\mathcal K[\nabla^2 f(\cdot)] + 1}} \\ & = \sqrt{\frac{1 - \frac{1}{\mathcal K [\nabla^2 f(\cdot)]}}{1 + \frac{1}{\mathcal K [\nabla^2 f(\cdot)]}}} \end{aligned} ∣∣xk−x∗∣∣∣∣xk−α⋅∇f(xk)−x∗∣∣≤λminλmax+1λminλmax−1=K[∇2f(⋅)]+1K[∇2f(⋅)]−1=1+K[∇2f(⋅)]11−K[∇2f(⋅)]1
通过观察可以发现:如果
K
[
∇
2
f
(
⋅
)
]
\mathcal K[\nabla^2 f(\cdot)]
K[∇2f(⋅)]充分大,有:
lim
K
[
∇
2
f
(
⋅
)
]
⇒
∞
1
−
1
K
[
∇
2
f
(
⋅
)
]
1
+
1
K
[
∇
2
f
(
⋅
)
]
=
1
−
0
1
+
0
=
1
\mathop{\lim}\limits_{\mathcal K[\nabla^2 f(\cdot)] \Rightarrow \infty}\sqrt{\frac{1 - \frac{1}{\mathcal K [\nabla^2 f(\cdot)]}}{1 + \frac{1}{\mathcal K [\nabla^2 f(\cdot)]}}} = \sqrt{\frac{1 - 0}{1 + 0}} = 1
K[∇2f(⋅)]⇒∞lim1+K[∇2f(⋅)]11−K[∇2f(⋅)]1=1+01−0=1
这意味着:
∣
∣
x
k
−
α
⋅
∇
f
(
x
k
)
−
x
∗
∣
∣
∣
∣
x
k
−
x
∗
∣
∣
≤
1
\begin{aligned}\frac{||x_k - \alpha \cdot \nabla f(x_k) - x^*||}{||x_k- x^*||} \leq 1\end{aligned}
∣∣xk−x∗∣∣∣∣xk−α⋅∇f(xk)−x∗∣∣≤1,而这意味着此时的收敛速度位于退化边缘。如果上式取等的话,那么收敛速度会从
Q
\mathcal Q
Q-线性收敛退化至次线性收敛。
因而通常称条件数
K
[
∇
2
f
(
⋅
)
]
\mathcal K[\nabla^2 f(\cdot)]
K[∇2f(⋅)]过大的现象称作病态问题。
这也体现了梯度下降法的弊端:如果函数
f
(
⋅
)
f(\cdot)
f(⋅)二阶可微,其对应
∇
2
f
(
⋅
)
\nabla^2 f(\cdot)
∇2f(⋅)的条件数过大可能会导致梯度下降法收敛速度的退化。而条件数的大小依赖
λ
m
a
x
λ
m
i
n
\begin{aligned}\frac{\lambda_{max}}{\lambda_{min}}\end{aligned}
λminλmax,也就是说:它依赖
λ
m
a
x
\lambda_{max}
λmax与
λ
m
i
n
\lambda_{min}
λmin的差异性的大小。因而这个条件数仅取决于
f
(
⋅
)
f(\cdot)
f(⋅)是否二阶可微这条性质上。而这条性质同样是
f
(
⋅
)
f(\cdot)
f(⋅)的自身性质。一旦
f
(
⋅
)
f(\cdot)
f(⋅)确定且二阶可微,那么其
∇
2
f
(
⋅
)
\nabla^2 f(\cdot)
∇2f(⋅)确定,从而条件数确定。文章来源:https://www.toymoban.com/news/detail-663431.html
相关参考:
【优化算法】梯度下降法-强凸函数的收敛性分析(下)
条件数、奇异值与海森矩阵文章来源地址https://www.toymoban.com/news/detail-663431.html
到了这里,关于机器学习笔记之优化算法(十七)梯度下降法在强凸函数的收敛性分析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!