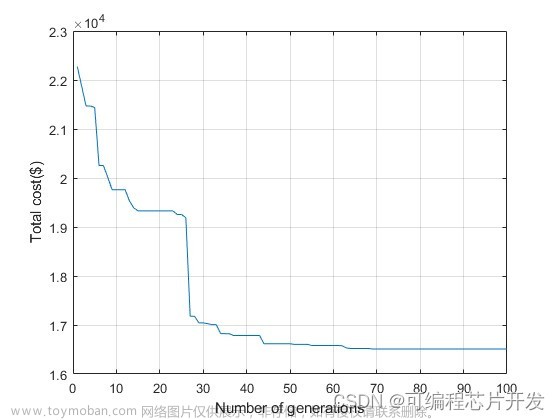
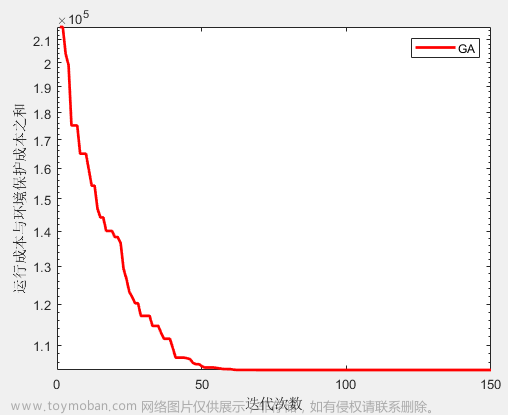
需求:实现遗传算法GA寻优xgboost最优参数模型搭建
遗传算法GA
遗传算法(Genetic Algorithm)是一种通过模拟生物进化过程来解决优化问题的算法。它模拟了自然界中的遗传、变异和选择等过程,并通过不断迭代寻找最优解。
优点
- 并行性强
遗传算法可以应用并行计算技术,同时对多个个体进行操作,从而加快算法的收敛速度。 - 适用性广
遗传算法适用于多种优化问题,例如组合优化、约束优化、函数优化等。 - 可获得全局最优解
遗传算法不仅可以找到局部最优解,还有一定的机会找到全局最优解。 - 无需求导
遗传算法不需要求解问题的导数或梯度信息,适用于无法求解导数的问题。
缺点
- 可能陷入局部最优解
遗传算法的搜索过程可能会陷入局部最优解,无法跳出局部最优解,从而无法找到全局最优解。 - 参数设置困难
遗传算法有很多参数需要设置,如种群大小、交叉概率、变异概率等,参数的选择对算法的性能有很大影响,但通常很难确定合适的参数值。 - 运行时间较长
遗传算法需要进行大量的迭代操作,寻找最优解的过程可能需要较长的时间。 - 不适用于高维问题
遗传算法在处理高维优化问题时,由于搜索空间的维度较大,很难找到合适的解。
xgboost
XGBoost(eXtreme Gradient Boosting)是一种基于梯度提升树的机器学习模型,相对于传统的梯度提升树,它在速度和效果上都有所提升。
优点
-
高效性
XGBoost在算法实现上进行了很多优化,使用了并行计算和缓存技术,使得训练和预测速度都非常快。 -
鲁棒性
XGBoost对于缺失值和异常值有较好的鲁棒性,能够自动处理缺失值和异常值,使得模型具有更好的稳定性。 -
可解释性
XGBoost能够输出特征的重要性,提供了对模型结果的解释能力,可以帮助我们理解模型的预测过程。 -
高准确性
XGBoost在处理非线性的复杂问题上表现优秀,并且能够有效地处理高维数据。 -
支持并行化
XGBoost支持并行化处理,可以利用多核CPU进行计算,提高训练和预测的效率。
缺点
-
参数调节复杂
XGBoost有很多参数需要调节,包括树的深度、学习率、正则化参数等,参数调节比较复杂,需要进行一定的实验和调整。 -
过拟合风险
XGBoost容易过拟合,特别是当数据集较小或者噪声较大时,需要进行适当的正则化来减少过拟合的风险。 -
对异常值敏感
XGBoost对异常值比较敏感,异常值可能会对模型的训练和预测结果造成较大的影响,需要对异常值进行处理或者采用鲁棒性更强的模型。
模型搭建步骤
代码已经上传,数据集采用第三方数据集,接下来对搭建过程进行简单介绍

一、安装xgboost和DEAP库
首先,需要安装xgboost和DEAP库,由于pip安装较慢,可以在命令行中输入如下指令进行快速安装,该部分可以参考添加链接描述
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple +安装包
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple xgboost
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple deap
二、导入必要的库
然后,我们可以开始编写代码。首先,导入必要的库:
import xgboost as xgb
from sklearn.datasets import load_boston
from sklearn.metrics import mean_squared_error
import numpy as np
from deap import base, creator, tools, algorithms在这里插入代码片
三、加载数据集
接下来,加载Boston房价数据集:
boston = load_boston()
X, y = boston.data, boston.target
由于1.2.0以上版本的scikit-learn已经不再支持,可以使用1.1.1的scikit-learn,安装时候会自动卸载原版本参考添加链接描述
pip install scikit-learn==1.1.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
四、定义目标函数
然后,定义目标函数,即XGBoost模型的交叉验证误差:
def eval_xgb(individual):
#保证[0,1]
individual[6]=math.fabs(individual[6])
while individual[6]>1 :
individual[6]=individual[6]-1
params = {
'max_depth': math.ceil(individual[0]),#取整
'learning_rate': math.fabs(individual[1]),#取绝对值
'n_estimators': individual[2],
'gamma': individual[3],
'min_child_weight': individual[4],
'subsample': individual[5],
'colsample_bytree': individual[6],
'objective': 'reg:squarederror'
}
cv_results = xgb.cv(params=params, dtrain=dtrain, num_boost_round=100, nfold=5, metrics='rmse', early_stopping_rounds=10, seed=0)
return cv_results['test-rmse-mean'][len(cv_results)-1],
这里的目标函数接受一个个体(即一组参数)作为输入,并返回该个体的交叉验证误差。
五、定义遗传算法的参数和操作
然后,定义遗传算法的参数和操作:
creator.create('FitnessMin', base.Fitness, weights=(-1.0,))
creator.create('Individual', list, fitness=creator.FitnessMin)
toolbox = base.Toolbox()
toolbox.register('attr_max_depth', np.random.randint, 1, 10)
toolbox.register('attr_learning_rate', np.random.uniform, 0.01, 0.3)
toolbox.register('attr_n_estimators', np.random.randint, 50, 200)
toolbox.register('attr_gamma', np.random.uniform, 0, 1)
toolbox.register('attr_min_child_weight', np.random.uniform, 0.1, 10)
toolbox.register('attr_subsample', np.random.uniform, 0.5, 1)
toolbox.register('attr_colsample_bytree', np.random.uniform, 0.5, 1)
toolbox.register('individual', tools.initCycle, creator.Individual, (
toolbox.attr_max_depth,
toolbox.attr_learning_rate,
toolbox.attr_n_estimators,
toolbox.attr_gamma,
toolbox.attr_min_child_weight,
toolbox.attr_subsample,
toolbox.attr_colsample_bytree), n=1)
toolbox.register('population', tools.initRepeat, list, toolbox.individual)
toolbox.register('evaluate', eval_xgb)
toolbox.register('mate', tools.cxUniform, indpb=0.1)
toolbox.register('mutate', tools.mutGaussian, mu=0, sigma=0.1, indpb=0.1)
toolbox.register('select', tools.selTournament, tournsize=3)
这里我们使用了随机数生成器来初始化每个参数,并定义了交叉和变异操作。
六、运行遗传算法
最后,运行遗传算法:文章来源:https://www.toymoban.com/news/detail-663440.html
np.random.seed(0)
dtrain = xgb.DMatrix(X, label=y)
pop = toolbox.population(n=50)
hof = tools.HallOfFame(1)
stats = tools.Statistics(lambda ind: ind.fitness.values)
stats.register('avg', np.mean)
stats.register('min', np.min)
pop, logbook = algorithms.eaSimple(pop, toolbox, cxpb=0.5, mutpb=0.2, ngen=10, stats=stats, halloffame=hof, verbose=True)
best_ind = hof[0]
print('Best individual:', best_ind)
print('Best RMSE:', best_ind.fitness.values[0])
这里我们使用了eaSimple函数来运行遗传算法,并设置了交叉概率和变异概率。运行完毕后,我们可以得到最优的个体和对应的RMSE误差。文章来源地址https://www.toymoban.com/news/detail-663440.html
到了这里,关于【算法】遗传算法GA寻优xgboost最优参数模型的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!