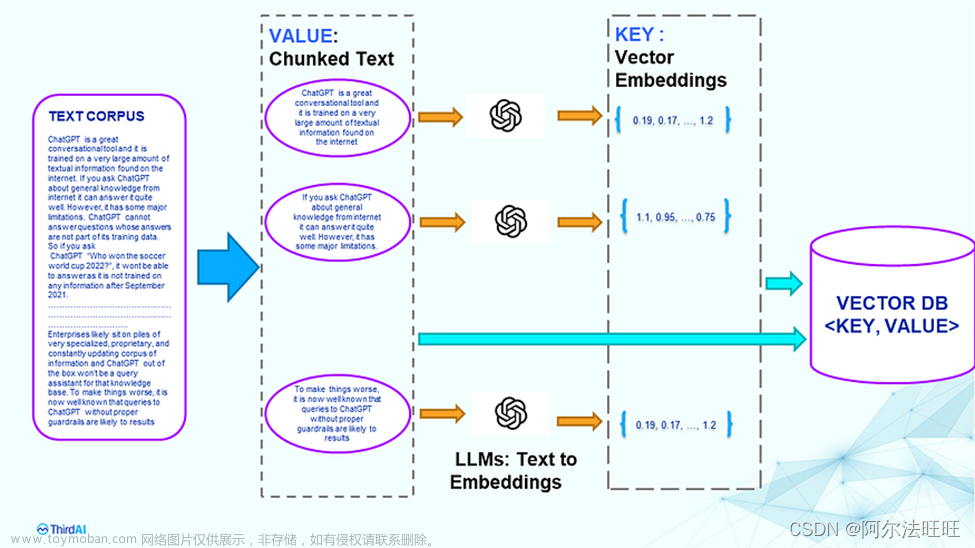
背景:现有亿级别数据(条数),其文本大小约为150G,label为字符串,content为文本。用于向量检索,采用上次的试验进行,但有如下问题需要面对:
1、向量维度及所需空间
向量维度一版采用768的bert系列的模型推理得到,openai也有类似的功能,不过是2倍的维度(即1536),至于哪个好坏,都宣称自己比较好,寡人实际应用中有实践:m3e-base似乎不错。
由于faiss需要float32的小数,根据下面试验,可以发现如果直接转成np.float32数据类型的数据然后直接进行存储(txt存储,每行进行存储),那么保留小数点后8位后存储的大小约为直接存储的数据的一半大小,同时节约了磁盘大小。在运行时,因为是大数据级别的,不建议将所有向量都求出来再进行存储,那样需要很大的内存,一般机器不支持,我这里的200G+的机器都over几次了。文章来源:https://www.toymoban.com/news/detail-663824.html
存储试验:文章来源地址https://www.toymoban.com/news/detail-663824.html
res=np.random.randn(2,768)
with open("test768.txt","w") as f :
for i in range(len(res)):
tmp = res[i].astype(np.float32).tolist()
# tmp = [round(i,8) for i in tmp]
tmp到了这里,关于大数据向量检索的细节问题的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!