前言
- 由于本人水平有限,难免出现错漏,敬请批评改正。
- 更多精彩内容,可点击进入YOLO系列专栏、自然语言处理
专栏或我的个人主页查看- 基于DETR的人脸伪装检测
- YOLOv7训练自己的数据集(口罩检测)
- YOLOv8训练自己的数据集(足球检测)
- YOLOv5:TensorRT加速YOLOv5模型推理
- YOLOv5:IoU、GIoU、DIoU、CIoU、EIoU
- 玩转Jetson Nano(五):TensorRT加速YOLOv5目标检测
- YOLOv5:添加SE、CBAM、CoordAtt、ECA注意力机制
- YOLOv5:yolov5s.yaml配置文件解读、增加小目标检测层
- Python将COCO格式实例分割数据集转换为YOLO格式实例分割数据集
- YOLOv5:使用7.0版本训练自己的实例分割模型(车辆、行人、路标、车道线等实例分割)
- 使用Kaggle GPU资源免费体验Stable Diffusion开源项目
前提条件
- 安装 Python 3.10.6 :https://www.python.org/downloads/release/python-3106/
- 安装 git:https://git-scm.com/download/win
- 安装 Visual Studio 2015, 2017, 2019, and 2022 redistributable:https://aka.ms/vs/17/release/vc_redist.x64.exe
相关介绍
- Python是一种跨平台的计算机程序设计语言。是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越多被用于独立的、大型项目的开发。
- PyTorch 是一个深度学习框架,封装好了很多网络和深度学习相关的工具方便我们调用,而不用我们一个个去单独写了。它分为 CPU 和 GPU 版本,其他框架还有 TensorFlow、Caffe 等。PyTorch 是由 Facebook 人工智能研究院(FAIR)基于 Torch 推出的,它是一个基于 Python 的可续计算包,提供两个高级功能:1、具有强大的 GPU 加速的张量计算(如 NumPy);2、构建深度神经网络时的自动微分机制。
- AIGC(人工智能生成内容)是指由人工智能系统创建或生成的内容。它涉及使用人工智能技术,如机器学习、自然语言处理和计算机视觉,生成各种形式的内容,包括文本、图像、视频、音乐等。
- 稳定扩散(Stable Diffusion)是一种用于概率建模和图像处理的方法。它基于扩散过程的理论,旨在对图像进行平滑和去噪处理,同时保持重要的图像结构和细节。
- 稳定扩散方法通过在图像上应用非线性扩散算子来实现平滑和去噪。与传统的线性扩散方法不同,稳定扩散引入了非线性项,以更好地保留图像的边缘和细节。
- 稳定扩散的核心思想是在扩散过程中考虑梯度信息,并根据梯度大小和方向来调整扩散速度。这样可以在平滑图像的同时,有效地抑制边缘的模糊和细节的丢失。
- 稳定扩散方法在图像去噪、边缘保持、纹理增强等方面具有广泛应用。它提供了一种平衡平滑和保持图像结构的方法,可以应用于计算机视觉、图像处理和模式识别等领域。
- LoRA模型全称是:Low-Rank Adaptation of Large Language Models,可以理解为Stable-Diffusion中的一个插件,仅需要少量的数据就可以进行训练的一种模型。
- LoRA模型可以用于大语言模型的微调,可以用来降低微调成本。
- LoRA模型可以和大模型结合使用,干涉大模型产生的结果。
- LoRA采用的方式是向原有的模型中插入新的数据处理层,从而避免了去修改原有的模型参数,从而避免将整个模型进行拷贝的情况,同时其也优化了插入层的参数量,最终实现了一种很轻量化的模型调校方法。
- LoRA建议冻结预训练模型的权重并在每个Transformer块中注入可训练层(秩-分解矩阵)。 LoRA还可以用于Stable-diffusion中的交叉关注层,从而改善用文字生成图片的效果。
- LoRA模型的个头都比较小,常见的都是144MB左右,使用的时候要与精简版(prund)的Stable Diffusion1.5模型配合使用。

微调训练LoRA模型
下载kohya_ss项目
- 官方源地址:https://github.com/bmaltais/kohya_ss.git
 下载解压后,项目目录,如下图所示。
下载解压后,项目目录,如下图所示。
安装kohya_ss项目
-
打开终端并导航到所需的安装目录。
进入kohya_ss目录:cd kohya_ss -
执行如下命令运行setup脚本:
.\setup.bat
如果没有报错,则安装成功。
运行kohya_ss项目
在Windows上,使用gui.bat脚本并在终端中运行它,命令如下:
gui.bat --listen 127.0.0.1 --server_port 7860 --inbrowser --share
运行成功后,可在浏览器输入http://127.0.0.1:7860/打开,如下图所示。
注:详细使用教程可查阅此项目中的
README.md文件
准备数据集
在kohya_ss项目下,创建一个train目录,具体内容如下:
- image : 图片放在这里。
- log:训练记录
- model:模型保存路径
- image目录还有一个子目录,比如本文这里是100_Freeman,100表示100个steps,会直接影响训练的步数和效果,Freeman表示图片人物名称。
- 创建好目录,将处理好的图片放在00_Freeman目录,然后就要准备做关键词生成。
生成关键词
- 具体步骤:Utilities->Captioning->BLIP Captioning

成功生成,会出现TXT文件,如下图所示。


模型参数设置
预训练模型设置

文件夹设置

训练参数设置

开始训练LoRA模型







训练完成后,会在model文件夹里生成一个.safetensors模型文件
TensorBoard查看训练情况
在页面上,点击Start TensorBoard,打开网址http://127.0.0.1:6006,即可查看。


测试训练的LoRA模型
测试模型,需要使用到stable-diffusion-webui项目,具体安装方法,可查阅Window下部署使用Stable Diffusion AI开源项目绘图
-
将kohya_ss/train/Freeman/model目录里的
Freeman_bs2_epoch50_fp16.safetensors模型文件分别拷贝到stable-diffusion-webui项目里的stable-diffusion-webui/models/Lora目录和stable-diffusion-webui/models/Stable-diffusion目录下。

-
在stable-diffusion-webui目录下,使用
webui-user.bat脚本并在终端中运行它,命令如下:
webui-user.bat

运行成功后,可在浏览器输入http://127.0.0.1:7861/打开,如下图所示。
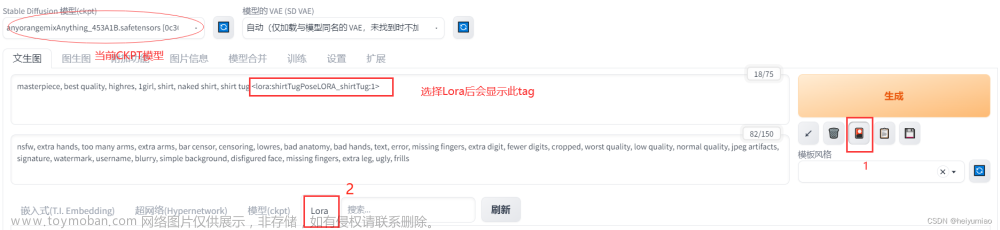
- 选择自己训练的LoRA模型



文字生成图像(txt2img)
<lora:Freeman_bs2_epoch50_fp16:1>Freeman a beautiful woman with glasses and a white dress,modelshoot style,beautiful light,photo realistic game cg
 文章来源:https://www.toymoban.com/news/detail-664102.html
文章来源:https://www.toymoban.com/news/detail-664102.html
参考
[1] https://github.com/bmaltais/kohya_ss.git
[2] https://github.com/AUTOMATIC1111/stable-diffusion-webui
[3] https://github.com/camenduru/stable-diffusion-webui
[4] https://www.kaggle.com/code/camenduru/stable-diffusion-webui-kaggle
[5] https://blog.csdn.net/wpgdream/article/details/130607099
[6] https://zhuanlan.zhihu.com/p/620583928文章来源地址https://www.toymoban.com/news/detail-664102.html
- 由于本人水平有限,难免出现错漏,敬请批评改正。
- 更多精彩内容,可点击进入YOLO系列专栏、自然语言处理
专栏或我的个人主页查看- 基于DETR的人脸伪装检测
- YOLOv7训练自己的数据集(口罩检测)
- YOLOv8训练自己的数据集(足球检测)
- YOLOv5:TensorRT加速YOLOv5模型推理
- YOLOv5:IoU、GIoU、DIoU、CIoU、EIoU
- 玩转Jetson Nano(五):TensorRT加速YOLOv5目标检测
- YOLOv5:添加SE、CBAM、CoordAtt、ECA注意力机制
- YOLOv5:yolov5s.yaml配置文件解读、增加小目标检测层
- Python将COCO格式实例分割数据集转换为YOLO格式实例分割数据集
- YOLOv5:使用7.0版本训练自己的实例分割模型(车辆、行人、路标、车道线等实例分割)
- 使用Kaggle GPU资源免费体验Stable Diffusion开源项目
到了这里,关于Stable Diffusion:使用自己的数据集微调训练LoRA模型的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!