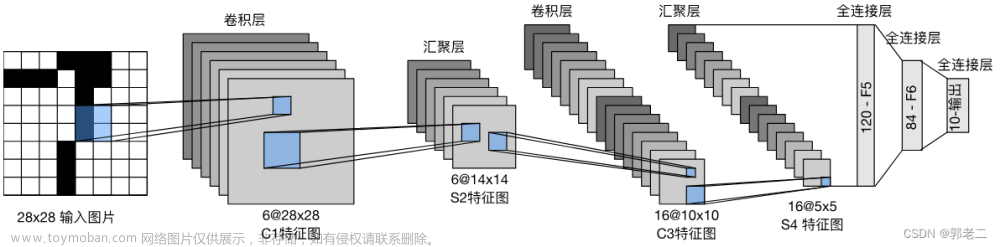
5、卷积神经网络
5.1、卷积
5.1.1、理论部分
全连接层后,卷积层出现的意义?
一个足够充分的照片数据集,输入,全连接层参数,GPU成本,训练时间是巨大的。
(convolutional neural networks,CNN)是机器学习利用自然图像中一些已知结构的创造性方法,需要更少的参数,在处理图像和其他类型的结构化数据上各类成本,效果,可行性普遍优于全连接层。
卷积层做了什么?
将输入和核矩阵进行互相关运算,加上偏移后得到输出。
图片中找模式的原则
- 平移不变性
- 局部性
对全连接层使用如上原则得到卷积层。
(详细待补充)
二维卷积层

Y = X ★ W + b Y = X ★ W + b Y=X★W+b
输入 X X X: n h × n w n_h × n_w nh×nw
图中,h:高、w:宽、输入大小 n = 3。
核 W W W: k h × k w k_h × k_w kh×kw
图中,卷积核大小 k = 2,超参数。
偏差 b∈ R
输出 Y Y Y: ( n h − k h + 1 ) × ( n w − k w + 1 ) ( n_h - k_h + 1)×(n_w - k_w + 1) (nh−kh+1)×(nw−kw+1)
图中 (3-2 +1)*(3-2 +1) = 4 ,计算的是 Y 的形状。
★:二维交叉操作子 | 外积
W 和 b是可学习的参数
卷积效果举例

5.1.2、代码实现
(1)实现互相关运算
卷积运算 ≠ 互相关运算
卷积运算:在卷积运算中,核心(也称为滤波器)在进行滑动时,会被翻转(180度旋转)后与输入数据进行逐元素相乘,并将乘积求和作为输出。这意味着核心的权重是翻转的。在卷积运算中,处理核心的边界像素会被覆盖,所以输出的大小通常会小于输入的大小。
互相关运算:在互相关运算中,核心与输入数据进行逐元素相乘,并将乘积求和作为输出,但核心不进行翻转。互相关运算不会覆盖核心的边界像素,所以输出的大小与输入的大小通常是一致的。
在深度学习中,人们通常使用卷积运算的术语来描述这种操作,尽管实际实现可能使用了互相关运算。卷积运算和互相关运算在数学上的操作相似,但在处理核心边界像素时存在微小的差异。在实际深度学习应用中,这两个术语通常可以互换使用。
import torch
from torch import nn
from d2l import torch as d2l
def corr2d(X, K): #@save
"""计算二维互相关运算"""
h, w = K.shape
Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
#点积求和
Y[i, j] = (X[i:i + h, j:j + w] * K).sum()
return Y
验证运算结果
X = torch.tensor([[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]])
K = torch.tensor([[0.0, 1.0], [2.0, 3.0]])
corr2d(X, K)
result:
tensor([[19., 25.], [37., 43.]])
实现二维卷积层
class Conv2D(nn.Module):
def __init__(self,kernel_size):
super().__init__()
self.weight =nn.Parameter(torch.rand(kernel_size))
self.bias = nn.Parameter(torch.zeros(1))
def forward(sekf, x):
return corr2d(x,self.weight) + self.bias
(2)学习由X生成Y卷积核
#一个输入通道、一个输出通道,不使用偏置
conv2d = nn.Conv2d(1,1,kernel_size=(1,2),bias =False)
X = X.reshape((1,1,6,8))
Y = Y.reshape((1,1,6,7))
for i in range(10):
Y_hat = conv2d(X)
l = (Y_hat - Y) **2
conv2d.zero_grad()
l.sum().backward()
conv2d.weight.data[:] -=3e-2 * conv2d.weight.grad
if(i + 1)% 2 == 0:
print(f'batch{i + 1}, loss {l.sum():.3f}')
所学卷积核权重
conv2d.weight.data.reshape((1,2))
tensor([[ 1.0084, -0.9816]])
5.1.3、边缘检测
利用卷积层检测 图像中的不同边缘
输入
X = torch.ones((6,8))
X[:, 2:6] =0
X
tensor([[1., 1., 0., 0., 0., 0., 1., 1.], [1., 1., 0., 0., 0., 0., 1., 1.], [1., 1., 0., 0., 0., 0., 1., 1.], [1., 1., 0., 0., 0., 0., 1., 1.], [1., 1., 0., 0., 0., 0., 1., 1.], [1., 1., 0., 0., 0., 0., 1., 1.]])
核矩阵
K = torch.tensor([[1,-1]])
输出
Y = corr2d(X,K)
Y
tensor([[ 0., 1., 0., 0., 0., -1., 0.], [ 0., 1., 0., 0., 0., -1., 0.], [ 0., 1., 0., 0., 0., -1., 0.], [ 0., 1., 0., 0., 0., -1., 0.], [ 0., 1., 0., 0., 0., -1., 0.], [ 0., 1., 0., 0., 0., -1., 0.]])
只能检测垂直边缘
Y = corr2d(X.t(),K) Ytensor([[0., 0., 0., 0., 0.], [0., 0., 0., 0., 0.], [0., 0., 0., 0., 0.], [0., 0., 0., 0., 0.], [0., 0., 0., 0., 0.], [0., 0., 0., 0., 0.], [0., 0., 0., 0., 0.], [0., 0., 0., 0., 0.]])将核矩阵一起转置
Y = corr2d(X.t(),K.t()) Y水平边缘检测可行。
tensor([[ 0., 0., 0., 0., 0., 0.], [ 1., 1., 1., 1., 1., 1.], [ 0., 0., 0., 0., 0., 0.], [ 0., 0., 0., 0., 0., 0.], [ 0., 0., 0., 0., 0., 0.], [-1., -1., -1., -1., -1., -1.], [ 0., 0., 0., 0., 0., 0.]])
5.2、填充和步幅
5.2.1、理论部分
填充操作
更大的卷积核可以更快地减小输出大小。
如果不想结果太小,也可以通过填充实现输出更大尺寸的X,实现控制输出形状的减少量。

填充 p h p_h ph行 p w p_w pw列,输出形状:
( n h − k h + p h + 1 ) × ( n w − k w + p w + 1 ) (n_h -k_h +p_h +1)×(n_w - k_w + p_w +1) (nh−kh+ph+1)×(nw−kw+pw+1)
填充的是外围的一层:上下各填充 p h p_h ph,宽度填充同理。
在卷积层代码中有个参数叫做
padding=,假设padding=p,代入上述公式:( n h − k h + p ∗ 2 + 1 ) × ( n w − k w + p ∗ 2 + 1 ) (n_h -k_h +p*2 +1)×(n_w - k_w + p*2 +1) (nh−kh+p∗2+1)×(nw−kw+p∗2+1)
计算错误就是把 p h p_h ph和 p p p混为一谈了。
通常取 p h = k h − 1 , p w = k w − 1 p_h = k_h -1, \ \ \ p_w =k_w -1 ph=kh−1, pw=kw−1
- k h k_h kh奇数:上下两侧填充 p h / 2 p_h/2 ph/2
- k h k_h kh偶数:上侧填充 ⌈ p h / 2 ⌉ ⌈p_h/2⌉ ⌈ph/2⌉下侧填充 ⌊ p h / 2 ⌋ ⌊p_h/2⌋ ⌊ph/2⌋
步幅
步幅指行/列滑动步长。
设置步幅的效果?
成倍减少输出形状。
下图为高3宽2步幅示意图:

(图片来自 《DIVE INTO DEEP LEARNING》)
给定步幅,高度 s h s_h sh宽度 s w s_w sw,输出形状:
⌊ ( n h − k h + p h + s h ) / s h ⌋ × ⌊ ( n w − k w + p w + s w ) / s w ⌋ ⌊(n_h - k_h + p_h + s_h)/s_h⌋ ×⌊(n_w - k_w + p_w + s_w)/s_w⌋ ⌊(nh−kh+ph+sh)/sh⌋×⌊(nw−kw+pw+sw)/sw⌋
如果输入高度宽度可被步幅整除,形状为:
( n h / s h ) × ( n w / s w ) (n_h / s_h)×(n_w / s_w) (nh/sh)×(nw/sw)
5.2.2、代码实现
填充、步幅是卷积层超参数。
所有侧边填充一个像素
import torch
from torch import nn
def comp_conv2d(conv2d, X):
X = X.reshape((1,1) + X.shape)
Y =conv2d(X)
return Y.reshape(Y.shape[2:])
conv2d = nn.Conv2d(1,1,kernel_size=3,padding=1)
X= torch.rand(size=(8,8))
comp_conv2d(conv2d,X).shape
填充相同高度宽度
import torch
from torch import nn
def comp_conv2d(conv2d, X):
X = X.reshape((1,1) + X.shape)
#执行一次卷积操作
Y =conv2d(X)
return Y.reshape(Y.shape[2:])
#padding=1 在输入数据的边界填充一行和一列的零值
conv2d = nn.Conv2d(1,1,kernel_size=3,padding=1)
X= torch.rand(size=(8,8))
comp_conv2d(conv2d,X).shape
torch.Size([8, 8])
不同高度宽度
conv2d = nn.Conv2d(1,1,kernel_size=(5,3),padding=(2,1))
comp_conv2d(conv2d,X).shape
torch.Size([8, 8])
增设步幅,其宽高为2
conv2d = nn.Conv2d(1,1,kernel_size=3,padding=1,stride =2)
comp_conv2d(conv2d,X).shape
torch.Size([4, 4])成倍缩小。
5.3、多输入多输出通道
5.3.1、理论部分
彩色RGB图片,是三通道输入数据。
每个通道都有一个卷积核,结果为各通道卷积的和。

1×1卷积层
不识别空间,用途是融合通道。
二维卷积层(多通道)
Y = X ★ W + B Y = X ★ W + B Y=X★W+B
输入 X X X: c i × n h × n w c_i × n_h × n_w ci×nh×nw
c i c_i ci输入通道数、h高、w宽、输入大小 n。
核 W W W: c o × c i × k h × k w c_o × c_i × k_h × k_w co×ci×kh×kw
c o c_o co输出通道数、卷积核大小 k。其中, c o c_o co是卷积层的超参数。
偏差 B B B : c o × c i c_o × c_i co×ci
一共有 c o × c i c_o × c_i co×ci个卷积核 每个卷积核都有一个偏差
输出 Y Y Y: c o × m h × m w c_o × m_h × m_w co×mh×mw
m h m w m_h \ m_w mh mw大小与 填充p、核大小k有关。
★:二维交叉操作子 | 外积
怎么理解每个输出通道有独立的三维卷积核?
具有三个维度:高度、宽度和通道数。
通道变化的意义
通道变化是非线性变换。
- 通道变大的意义: 增加通道数可以增强网络的表达能力和特征提取能力。通过引入更多的卷积核,网络可以学习更多不同尺度和不同抽象级别的特征。它们有助于捕获图像的细节和纹理,以及高级别的抽象特征。在更高的层次上学习到更丰富的特征。
- 通道变小的意义: 减小通道数可以降低网络的计算成本和参数数量,同时也可以起到特征压缩和维度约减的作用。通过将较大通道数的特征图进行降维,从而实现网络的轻量化。还可以起到正则化的作用,减少过拟合的风险。在某些情况下,通道数的减小也可以帮助网络更好地学习到一些共享的、更为重要的特征。
5.3.2、代码实现
(1)实现多通道互相关运算
定义多通道输入
import torch
from d2l import torch as d2l
#先遍历“X”和“K”的第0个维度(通道维度),再把它们加在一起
def corr2d_multi_in(X,K):
return sum(d2l.corr2d(x,k) for x,k in zip(X,K))
多通道第零维度的几何意义?
图中X第零维度有两组,几何上就是通道数。
X :(tensor([[[0., 1., 2.], [3., 4., 5.], [6., 7., 8.]], [[1., 2., 3.], [4., 5., 6.], [7., 8., 9.]]]),

定义X,K
# X 2*3*3
X = torch.tensor([[[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]],
[[1.0, 2.0, 3.0], [4.0, 5.0, 6.0], [7.0, 8.0, 9.0]]])
#K 2*2*2
K = torch.tensor([[[0.0, 1.0], [2.0, 3.0]], [[1.0, 2.0], [3.0, 4.0]]])
X,K,corr2d_multi_in(X, K)
(tensor([[[0., 1., 2.], [3., 4., 5.], [6., 7., 8.]], [[1., 2., 3.], [4., 5., 6.], [7., 8., 9.]]]), tensor([[[0., 1.], [2., 3.]], [[1., 2.], [3., 4.]]]), tensor([[ 56., 72.], [104., 120.]]))
定义多通道输出
def corr2d_multi_in_out(X,K):
# 使用 PyTorch 的 torch.stack 函数,它将一组张量沿着指定的维度(这里是维度0)进行堆叠,生成一个新的张量。
return torch.stack([corr2d_multi_in(X,k) for k in K],0)
# K+1 K的每个值加一,K规模扩成了原来3倍。
K = torch.stack((K,K+1,K+2),0)
K,K.shape
(tensor([[[[0., 1.], [2., 3.]], [[1., 2.], [3., 4.]]], [[[1., 2.], [3., 4.]], [[2., 3.], [4., 5.]]], [[[2., 3.], [4., 5.]], [[3., 4.], [5., 6.]]]]), torch.Size([3, 2, 2, 2]))返回值那一行为什么用小k对应X,多通道输入那里不是用的大K对应X,然后第零维度展开,抽出x,k对应计算吗?
K扩了三倍,所以用小k规模和原来的K相当,因此X 对应扩充前的K,扩充后的小k。
corr2d_multi_in_out(X,K)
tensor([[[ 56., 72.], [104., 120.]], [[ 76., 100.], [148., 172.]], [[ 96., 128.], [192., 224.]]])
(2)实现1*1卷积核
def corr2d_multi_in_out_1x1(X, K):
c_i, h, w = X.shape
c_o = K.shape[0]
X = X.reshape((c_i, h * w))
K = K.reshape((c_o, c_i))
# 全连接层中的矩阵乘法
Y = torch.matmul(K, X)
return Y.reshape((c_o, h, w))
X = torch.normal(0, 1, (3, 3, 3))
K = torch.normal(0, 1, (2, 3, 1, 1))
Y1 = corr2d_multi_in_out_1x1(X, K)
Y2 = corr2d_multi_in_out(X, K)
# 进行断言,验证使用 1x1 卷积操作得到的输出 Y1 与多通道卷积操作得到的输出 Y2 是否非常接近,以确保两种方法的结果一致
assert float(torch.abs(Y1 - Y2).sum()) < 1e-6
5.4、池化层 | 汇聚层
5.4.1、理论部分
最大池化,每个窗口最强的模式信号,它针对卷积对空间位置敏感(边缘检测案例),允许输入有一定的偏移。
也有平均池化层。
特点
- 具有填充,步幅;
- 没有可学习的参数;
- 输出通道 = 输入通道,一一对应。
5.4.2、代码实现
池化层向前传播
import torch
from torch import nn
from d2l import torch as d2l
def pool2d(X, pool_size, mode='max'):
p_h, p_w = pool_size
Y = torch.zeros((X.shape[0] - p_h + 1, X.shape[1] - p_w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
if mode == 'max':
Y[i, j] = X[i: i + p_h, j: j + p_w].max()
elif mode == 'avg':
Y[i, j] = X[i: i + p_h, j: j + p_w].mean()
return Y
验证最大池化层
X = torch.tensor([[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]]) pool2d(X, (2, 2))tensor([[4., 5.], [7., 8.]])验证平均池化层
pool2d(X, (2,2), 'avg')tensor([[2., 3.], [5., 6.]])
使用内置的最大池化层
X = torch.arange(16, dtype=torch.float32).reshape((1, 1, 4, 4))
X
tensor([[[[ 0., 1., 2., 3.], [ 4., 5., 6., 7.], [ 8., 9., 10., 11.], [12., 13., 14., 15.]]]])
pool2d = nn.MaxPool2d(3, padding=1, stride=2)#等价于nn.MaxPool2d((3,3), padding=(1,1), stride=(2,2))
pool2d(X)
tensor([[[[ 5., 7.], [13., 15.]]]])
pool2d = nn.MaxPool2d((2, 3), stride=(2, 3), padding=(0, 1))
pool2d(X)
tensor([[[[ 5., 7.], [13., 15.]]]])
验证多通道
汇聚层在每个输入通道上单独运算,输出通道数与输入通道数相同。
拼接上
torch.cat和torch.stack的区别torch.cat是在现有维度上进行拼接。文章来源:https://www.toymoban.com/news/detail-664269.html
torch.stack用于创建一个新的维度,并将多个张量沿该新维度进行堆叠。文章来源地址https://www.toymoban.com/news/detail-664269.html
# 将两个张量 X, X + 1 进行拼接
X = torch.cat((X, X + 1), 1)
X
tensor([[[[ 0., 1., 2., 3.], [ 4., 5., 6., 7.], [ 8., 9., 10., 11.], [12., 13., 14., 15.]], [[ 1., 2., 3., 4.], [ 5., 6., 7., 8.], [ 9., 10., 11., 12.], [13., 14., 15., 16.]]]])
pool2d = nn.MaxPool2d(3, padding=1, stride=2)
pool2d(X)
tensor([[[[ 5., 7.], [13., 15.]], [[ 6., 8.], [14., 16.]]]])
到了这里,关于卷积神经网络——上篇【深度学习】【PyTorch】【d2l】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!