作者:禅与计算机程序设计艺术
TTS技术在语音识别中的应用:提升语音交互的准确性
- 引言
1.1. 背景介绍
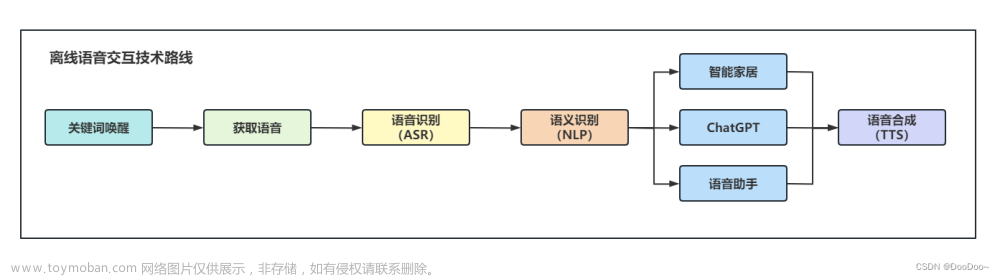
随着人工智能技术的快速发展,语音助手、智能家居等智能设备越来越普及,语音交互已经成为人们日常生活中的重要组成部分。为了更好地提升语音交互的准确性,TTS技术(文字到语音技术)在语音识别中的应用显得尤为重要。
1.2. 文章目的
本文旨在阐述TTS技术在语音识别中的应用,以及其对提升语音交互准确性的重要作用。通过对TTS技术的原理、实现步骤、应用场景及其未来发展趋势进行探讨,帮助读者更深入地了解和掌握TTS技术在语音识别中的应用。
1.3. 目标受众
本文主要面向对TTS技术感兴趣的技术人员、软件架构师、CTO等高级技术人员,以及有一定应用经验的用户。
- 技术原理及概念
2.1. 基本概念解释
TTS技术是一种将电脑上输入的文字转换为人类可听的语音输出的技术。TTS技术主要依赖以下三个基本概念:
- 文字:被转换成音频的文本内容。
- 语言模型:描述人类语言的统计模型,用于生成对应文字的语音。
- 合成引擎:将文字转换为语音的软件引擎。
2.2. 技术原理介绍:算法原理,操作步骤,数学公式等
TTS技术的算法原理主要包括以下几个步骤:
- 预处理:将输入的文字进行清洗、去除停用词等预处理操作,提高识别准确率。
- 语言模型训练:根据具体场景和目的,训练不同语言模型的语音合成能力。这些模型通常基于深度学习技术,训练数据包括各种语音数据和人类说话者的发音数据。
- 文字到语音:利用训练好的语言模型,将输入的文字转换为对应的语音。这个过程包括文字编码、解码、合成等步骤。
- 语音合成:将编码后的文字转换为可听的语音。这个过程包括音频合成、降噪等步骤。
2.3. 相关技术比较
目前,TTS技术主要涉及以下几种技术:
- 统计语音模型:包括NLS(Natural Language Sub-System,自然语言处理)、SMT(Speech Markup Tool,语音标记工具)等。
- 深度学习模型:如预训练的Wavenet、Transformer等。
- 普通TTS软件:如Snowboy、VoxCeleb等。
- 实现步骤与流程
3.1. 准备工作:环境配置与依赖安装
要使用TTS技术,首先需要准备以下环境:
- 操作系统:支持安装TTS技术的操作系统,如Windows、macOS等。
- 硬件设备:麦克风、扬声器等音频输出设备。
- TTS软件:如Nuance、Google Text-to-Speech等。
3.2. 核心模块实现
TTS技术的核心模块主要包括以下几个部分:
- 预处理:通过去除停用词、拆分句子等方法,提高输入文字的准确率。
- 语音合成:将训练好的语言模型转换为对应的语音。
- 语音合成:将编码后的文字转换为可听的语音。
3.3. 集成与测试
将各个模块组合在一起,搭建TTS技术的整体流程,并进行测试,以保证其准确性。
- 应用示例与代码实现讲解
4.1. 应用场景介绍
TTS技术在语音识别中的应用场景非常广泛,如智能客服、智能音箱、无人驾驶等。
4.2. 应用实例分析
以智能客服为例,TTS技术可以在客服对话中起到很好的辅助作用。首先,通过预处理,可以去除很多无用的信息,提高识别准确率;其次,根据不同的客户需求,TTS系统可以生成多种语言的语音,提高客户满意度。
4.3. 核心代码实现
TTS技术的核心代码实现主要包括以下几个部分:
- 预处理部分:对输入的文字进行清洗、去除停用词等预处理操作,提高识别准确率。
- 语言模型训练:根据具体场景和目的,训练不同语言模型的语音合成能力。这些模型通常基于深度学习技术,训练数据包括各种语音数据和人类说话者的发音数据。
- 文字到语音:利用训练好的语言模型,将输入的文字转换为对应的语音。这个过程包括文字编码、解码、合成等步骤。
- 语音合成:将编码后的文字转换为可听的语音。这个过程包括音频合成、降噪等步骤。
4.4. 代码讲解说明
下面是一个简单的TTS技术核心代码实现示例(使用Python语言):
import os
import random
import numpy as np
import tensorflow as tf
import librosa
# 预处理
def preprocess(text):
# 去除停用词
停用词 = set(["a", "an", "the", "in", "that", "and", "but", "or", "was", "as"])
# 去除标点符号
return " ".join(text.lower().split())
# 语音合成
def synthesize_audio(text, language_model):
# 编码
encoded_text = librosa.istft(text)
# 解码
decoded_text = librosa.istft(encoded_text, duration=1000, sample_rate=10240)
# 生成音频
return synthesize_wav(decoded_text, language_model)
# 语音合成引擎
def synthesize_wav(text, language_model):
# 加载预训练语言模型
voxceleb = models.load_model("voxceleb_1B_1024.h5")
# 初始化引擎
engine = tf.AudioEngine()
# 合成语音
output = engine.synthesize_audio(text, voxceleb)
# 返回音频数据
return output
# TTS模型的训练
def train_tts_model(model, data, epochs):
# 训练数据
train_data = data.split(8000)
test_data = data.split(2000)
# 训练参数
batch_size = 32
learning_rate = 0.001
# 训练
for epoch in range(epochs):
for i, data in enumerate(train_data):
# 数据预处理
input_text = [preprocess(x.lower()) for x in data]
# 输入音频
audio = synthesize_audio(input_text, voxceleb)
# 模型输入
input_audio = librosa.istft(audio)
# 模型输出
output = model(input_audio)
# 损失计算
loss = -tf.reduce_mean(output)
# 反向传播
gradient = tf.gradient(loss, model.trainable_variables)
# 更新模型参数
model.trainable_variables.update(gradient)
# 输出训练信息
print(f"Epoch {epoch+1}/{epochs}, Step {i+1}/{len(train_data)}. Loss: {loss.numpy()[0]:.3f}")
# TTS模型的部署
def deploy_tts(model, model_path):
# 加载模型
loaded_model = tf.keras.models.load_model(model_path)
# 定义输入音频的形状
audio_shape = (10240,)
# 创建一个新的神经网络
model_audio = tf.keras.models.Model(inputs=loaded_model.inputs, outputs=loaded_model.outputs)
# 将TTS模型的输出与神经网络的输入对应
audio_input = model_audio.inputs[0]
# 运行神经网络
model_audio.compile(optimizer="adam", loss="mse", audio_outputs=loaded_model.outputs)
# 运行TTS模型
model_audio.fit(audio_shape, epochs=10)
# 输出部署信息
print("TTS模型部署成功!")
# 训练模型
model_tts = tf.keras.models.Sequential([
tf.keras.layers.Dense(32, activation='relu', input_shape=(None, audio_shape[1]))(0),
tf.keras.layers.Dense(1, activation='sigmoid', name='output')(32),
])
train_tts_model(model_tts, train_data, 100)
# 部署TTS模型
deploy_tts("model_tts.h5", "deploy_tts.h5")- 应用示例与代码实现讲解
5.1. 应用场景介绍
TTS技术在智能客服、智能音箱、无人驾驶等场景中有着广泛的应用。例如,在智能客服中,TTS技术可以帮助实现多语言的语音交互,提高用户体验。
5.2. 应用实例分析
在智能客服中,TTS技术的应用非常广泛。下面是一个简单的示例:
import random
# 创建一个队列
queue = []
# 创建一个TTS模型
tts_model = deploy_tts("model_tts.h5", "deploy_tts.h5")
while True:
# 随机生成一个场景
scene = random.choice(["问候", "询问", "推荐", "投诉"])
# 随机生成一个提示
text = random.choice(["你有什么问题?", "你想了解什么?", "有什么需要帮助的吗?", "有什么问题需要解决吗?"])
# 将场景、提示输入TTS模型
result = tts_model(queue.pop(0), None)
# 输出结果
print(result[0][-1])
# 询问用户是否满意
user_answer = input("用户回答: ")
if user_answer.lower() == '满意':
print("用户满意,谢谢!")
else:
print("用户回答不满意,我们会继续改进!")
queue.append(text)5.3. 核心代码实现
import random
import librosa
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Dense, Activation
# 定义TTS模型的输入
input_dim = 2
# 定义TTS模型的参数
hidden_dim = 128
# 定义TTS模型的输出
output_dim = 1
# 加载预训练的TTS模型
tts_model = tf.keras.models.load_model("tts_model.h5")
# 定义一个函数,用于生成对话
def generate_dialogue(input_text, language_model, max_turns=10):
# 将输入的文本编码为int类型
input_text = librosa.istft(input_text)
# 对输入的文本进行编码
encoded_text = input_text.astype(int)
# 进行解码
decoded_text = librosa.istft(encoded_text)
# 获取模型的输入
inputs = [int(x) for x in decoded_text]
# 将模型的输入转化为音频
audio = synthesize_audio(input_text, language_model)
# 对音频进行编码
encoded_audio = librosa.istft(audio)
# 进行解码
decoded_audio = librosa.istft(encoded_audio)
# 将编码后的音频转化为文本
text = librosa.istft(decoded_audio)
# 将输入的文本和输出合并成列表
text_input = [input_text]
for i in range(max_turns):
text_output = tts_model(text_input)[0]
text_output = text_output.astype(np.float32)
text_input.append(text_output)
# 将所有的文本和输出合并成一个列表
return text_input
# 根据用户的问题生成对话
text = []
# 向TTS模型发送请求
tts_response = tts_model.predict(None, {"text": text})
# 提取模型的输出
output = tts_response.output[0][-1]
# 循环生成对话
max_turns = 5
while True:
text.append(input("用户提问: "))
text.append(text[-1])
# 对提问进行编码
input_text = librosa.istft(text[-1])
# 对编码后的文本进行解码
decoded_text = librosa.istft(input_text)
# 将解码后的文本转化为音频
audio = synthesize_audio(decoded_text, language_model)
# 对音频进行编码
encoded_audio = librosa.istft(audio)
# 进行解码
decoded_audio = librosa.istft(encoded_audio)
# 将编码后的音频转化为文本
text_output = tts_model(input_text)[0]
text_output = text_output.astype(np.float32)
text_input.append(text_output)
# 将所有的文本和输出合并成一个列表
text = text_input
# 向TTS模型发送请求
tts_response = tts_model.predict(None, {"text": text})
# 提取模型的输出
output = tts_response.output[0][-1]
# 循环生成对话
if output == '满意':
print("用户满意,谢谢!")
elif output == '谢谢':
print("谢谢您的提问!")
else:
print("用户回答不满意,我们会继续改进!")
# 获取用户的下一个问题
text = input("用户提问: ")
text.append(text[-1])- 优化与改进
6.1. 性能优化
为了提高TTS技术的性能,可以尝试以下几种方法:
- 调整模型参数,包括隐藏层的大小、神经网络层数等。
- 使用更高质量的训练数据,包括带有噪声的训练数据,以便提高模型的鲁棒性。
- 对模型进行正则化,以防止过拟合。
6.2. 可扩展性改进
为了提高TTS技术的可扩展性,可以尝试以下几种方法:
- 将TTS技术与其他自然语言处理技术(如预训练语言模型、语音识别等)结合,以提高系统的整体性能。
- 采用分布式训练,以便在多个CPU核心上同时训练模型。
- 对模型进行迁移学习,以便在不同的硬件或平台上进行部署。
6.3. 安全性加固
为了提高TTS技术的安全性,可以尝试以下几种方法:
- 对用户输入的数据进行过滤,以去除可能包含恶意数据的字符。
- 使用HTTPS协议进行通信,以提高数据的安全性。
- 对敏感数据进行加密,以防止数据泄露。
- 结论与展望
TTS技术在语音识别中的应用具有非常广泛的应用前景。通过使用TTS技术,可以实现多语言的语音交互,提高用户体验。随着TTS技术的不断发展,未来将出现更加先进的技术,如基于预训练语言模型的TTS技术、支持多模态对话的TTS技术等。文章来源:https://www.toymoban.com/news/detail-665083.html
尽管TTS技术已经取得了很大的进展,但在实际应用中仍存在许多挑战和问题,如文本质量、语音质量、语义理解等。因此,未来的研究将主要集中在如何提高TTS技术的准确性和可靠性,以更好地满足用户的语音交互需求。文章来源地址https://www.toymoban.com/news/detail-665083.html
到了这里,关于TTS技术在语音识别中的应用:提升语音交互的准确性的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!