hbase-phoenix 总结
客户端设置
phoenix 客户端,文章来源地址https://www.toymoban.com/news/detail-665362.html
source bigdata_env -- 环境认证
kinit -kt admin.keytab admin -- 用户认证
设置phoenix 参数
-- 设置客户端宽度
!set maxwidth 3000
-- 让结果竖着显示
!set outputformat vertical
!set outputformat table
phoenix 导出数据
-- 设置数据导出格式
!outputformat csv
-- 设置导出数据的存储位置
!record /home/test/result.csv
-- 查询数据
select * from test;
-- 结束导出
!record
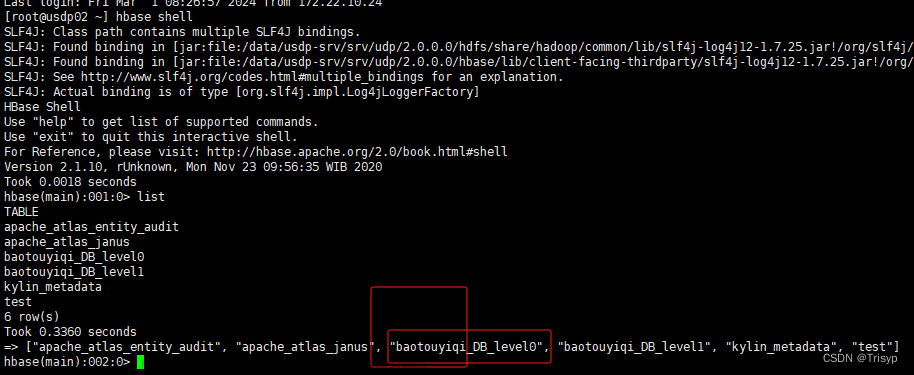
查看所有的表
!tables
文章来源:https://www.toymoban.com/news/detail-665362.html
到了这里,关于hbase-phoenix的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!