前言
Hadoop、Spark和Flink是目前重要的三大分布式计算系统。它们都可以用于大数据处理,但在处理方式和应用场景上有所不同。
Hadoop专为批处理而生,一次将大量数据集输入到输入中,进行处理并产生结果。它用于离线复杂的大数据处理。
Spark定义是一个批处理系统,但也支持流处理。它用于离线快速的大数据处理。
Flink为流和批处理提供了一个运行时。它用于在线实时的大数据处理。
这三个框架在不同的大数据处理场景当中,表现各有优势。因此,最好的方案就是将各自的优势结合起来,实现更高效率地完成大数据处理任务。
*注:
①在线与离线:在线大数据处理是指在应用程序由用户输入驱动时,需要及时响应用户的处理方式。例如,社交网络新闻提要、实时广告服务器、分析工具和CRM应用程序都属于在线大数据处理的范畴。离线大数据处理是指在没有承诺响应用户的情况下进行的处理方式。离线大数据处理提供了对大量数据进行转换、管理或分析的能力。
②批处理与流处理:批处理是指在数据被收集完成后再进行处理。这种方式适用于离线复杂的大数据处理,例如账单、客户订单、工资单等。批处理通常需要较长时间,更适合大量数据的处理。流处理是指实时地对数据进行处理,数据是分段发送到分析工具中的。这种方式适用于在线实时的大数据处理,例如欺诈检测、日志监控、客户行为分析和社交媒体分析等。流处理的延迟通常以秒或毫秒为单位,因为在流处理中,数据在到达磁盘之前会被分析。
Hadoop
基础架构
Hadoop是一个分布式计算系统,它由多个元素构成。最底层是Hadoop Distributed File System(HDFS),它存储Hadoop集群中所有存储节点上的文件。HDFS的上一层是MapReduce引擎,该引擎由JobTrackers和TaskTrackers组成。此外,Hadoop还包括YARN(Yet Another Resource Negotiator)资源管理器和Common库。
① HDFS:Hadoop Distributed File System(HDFS)是一种分布式文件系统,它能够在多个计算机之间存储大量数据。
② MapReduce:MapReduce是一种编程模型,用于处理大量数据。它将计算任务分解为多个小任务,分别在不同的计算节点上执行,然后将结果汇总起来。
③ YARN:YARN(Yet Another Resource Negotiator)是Hadoop的资源管理器,负责管理集群中的计算资源,并调度用户提交的作业。
④ Common:Common库包含了Hadoop所需的各种通用组件和工具,例如配置管理、日志记录和安全管理等。
这些组件共同构成了Hadoop这个强大的分布式计算系统。它们协同工作,能够处理海量数据,并提供高可靠性、高扩展性和高容错性等特性。
优点
① 高可靠性:Hadoop按位存储和处理数据的能力值得人们信赖。
② 高扩展性:Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
③ 高效性:Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
④ 高容错性:Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
不足
① 所有的metadata操作都要通过集中式的NameNode来进行,NameNode有可能是性能的瓶颈。
② 单一NameNode、单一Jobtracker的设计严重制约了整个Hadoop可扩展性和可靠性。首先,NameNode和JobTracker是整个系统中明显的单点故障源。再次,单一NameNode的内存容量有限,使得Hadoop集群的节点数量被限制到2000个左右,能支持的文件系统大小被限制在10-50PB,最多能支持的文件数量大约为1.5亿左右。
③ 部分hadoop集群的NameNode重启需要数小时,这大大降低了系统的可用性。
④ 随着Hadoop被广泛使用,面对各式各样的需求,人们期望Hadoop能提供更多特性,比如完全可读写的文件系统、Snapshot、Mirror等等。这些都是当前版本的Hadoop不支持,但是用户又有强烈需求的。
Spark
基础架构
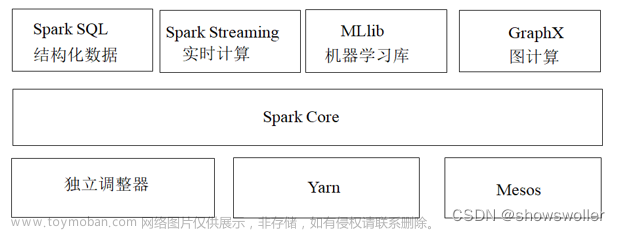
Apache Spark是一个围绕速度、易用性和复杂分析构建的大数据处理框架,最初在2009年由加州大学伯克利分校的AMPLab开发,并于2010年成为Apache的开源项目之一。Spark由SparkCore、Spark SQL、Spark Streaming、GraphX、MLlib等模块组成。
Spark运行架构包括集群资源管理器(Cluster Manager)、多个运行作业任务的工作结点(Worker Node)、每个应用的任务控制结点(Driver)和每个工作结点上负责具体任务的执行进程(Executor)。
① Cluster Manager:在Standalone模式中即为Master(主节点),控制整个集群,监控Worker。 在YARN模式中为资源管理器。
② Worker:从节点(子节点),负责控制计算节点,启动Executor或Driver。 在YARN模式中为NodeManager,负责计算节点的控制。
③ Driver:运行Appplication的main ()函数并创建SparkContext。
④ Executor:执行器,在worker node 上执行任务的组件,用于启动线程池运行任务。 每个Application拥有独立的一组Executors。
⑤ SparkContext:整个应用的上下文,控制应用的生命周期。
这些组件共同构成了Spark这个强大的分布式计算系统。它们协同工作,能够处理海量数据,并提供高可靠性、高扩展性和高容错性等特性。
优点
① 快速:Spark基于内存进行计算,能够极大地提高大数据处理速度。
② 易用:Spark支持多种语言,包括Java、Scala、Python和R,这使得更多的开发人员能够在自己熟悉的语言环境下进行工作。
③ 通用:Spark提供了多种技术组件,包括Spark RDD、Spark SQL、Spark Streaming、Spark MLlib和Spark GraphX,可以一站式地完成大数据领域的离线批处理、交互式查询、流式计算、机器学习和图计算等常见任务。
④ 随处运行:用户可以使用Spark的独立集群模式运行Spark,也可以在EC2(亚马逊弹性计算云)、Hadoop YARN或者Apache Mesos上运行Spark。并且可以从HDFS、Cassandra、HBase、Hive和任何分布式文件系统读取数据。
不足
① 学习曲线陡峭:相比于Hive,Spark的学习曲线更加陡峭,需要一定的编程基础和技能。
② 内存消耗高:由于使用内存计算引擎,因此需要更多的内存资源,相比于Hive更加消耗计算资源。
Flink
基础架构
Apache Flink是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink能够在所有常见的集群环境中运行,并能以内存速度和任意规模进行计算。Flink支持多种部署模式,包括独立部署、YARN部署、Mesos部署和Kubernetes部署。这些部署模式可以满足不同的应用场景和需求。
Flink的基础架构包括以下几个部分:
① JobManager:负责调度和协调整个Flink作业的执行。
② TaskManager:负责执行Flink作业中的具体任务。
③ Client:负责提交Flink作业到JobManager。
④ ResourceManager:负责管理集群中的资源。
优点
① 高吞吐量:Flink能够以高速度处理大量数据,满足实时数据处理的需求。
② 低延迟:Flink能够快速地对数据进行处理,减少数据处理的延迟。
③ 高性能:Flink能够在有界和无界数据流上进行有状态的计算,提供高性能的数据处理能力。
④ 灵活性:Flink支持多种部署模式,可以满足不同的应用场景和需求。
不足
① 学习曲线陡峭:与spark一样,相比于其他大数据处理框架,Flink的学习曲线更加陡峭,需要一定的编程基础和技能。
② 集成开发应用:在实际上的大数据平台应用当中,Flink也并非是完美的,作为计算引擎,Flink能满足绝大部分的数据处理需求,但是作为系统平台而言,Flink的缺点也是存在的,所以主流的趋势还是与其他平台例如Hadoop进行集成开发应用。
结语:大数据框架的选择
选择合适的大数据处理框架需要根据企业的实际需求来进行。不同的技术框架,在处理数据上各有优缺点。大数据处理框架通常可以分为三类——批处理框架、流处理框架和批处理+流处理框架。例如,Apache Hadoop是一个批处理框架,而Apache Storm和Apache Samza是流处理框架,Apache Spark和Apache Flink则是批处理+流处理框架。
在选择大数据处理框架时,需要考虑以下几个因素:
① 处理需求:根据企业的实际需求,选择适合的大数据处理框架。例如,如果企业需要对大量静态数据进行离线批处理分析,则可以选择Hadoop;如果企业需要对实时数据进行流式计算,则可以选择Storm或Samza;如果企业同时需要批处理和流处理,则可以选择Spark或Flink。
② 性能:不同的大数据处理框架在性能上有所差异,需要根据实际情况选择性能较好的框架。
③ 扩展性:大数据处理往往需要在集群环境中运行,因此需要选择具有良好扩展性的框架,以便在集群规模增加时能够快速扩展。
④ 兼容性:如果企业已经使用了某些大数据技术,例如Hadoop,则需要选择与现有技术兼容的框架。文章来源:https://www.toymoban.com/news/detail-665814.html
总之,在选择大数据处理框架时,需要根据企业的实际需求、性能、扩展性和兼容性等因素进行综合考虑。文章来源地址https://www.toymoban.com/news/detail-665814.html
到了这里,关于Hadoop、Spark与Flink的基础架构及其关系和优异的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!