(为了节约时间,后面关于机器学习和有关内容哦就是用中文进行书写了,如果有需要的话,我在目前手头项目交工以后,用英文重写一遍)
(祝,本文同时用于比赛学习笔记和机器学习基础课程)
俺前两天参加了一个ai类的比赛,其中用到了一种名为baseline的模型来进行一些数据的识别。而这个识别的底层原理就是决策树。正好原本的学习进度刚刚完成这部分,所以集成一个笔记了,本文中所有的截图绝大多数来自吴恩达老师的公开课程,为了方便理解,把相关的图片搬过来了)
决策树是什么
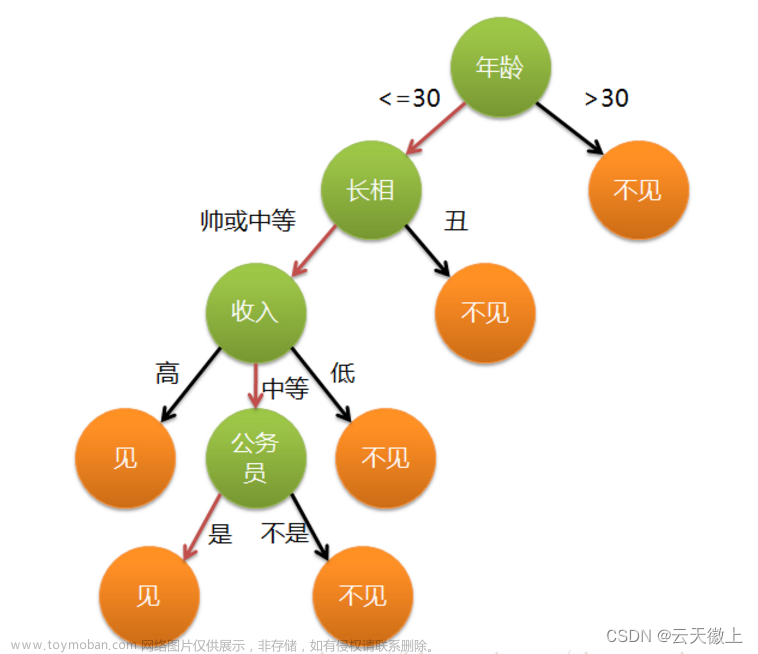
决策树是一种机器学习算法,在一个类似二叉树的结构上实现的分支判断算法。每个节点都视为一个“判断语句”,将一批数据划分成不同的部分。节点上(除了叶子)都要判断“是”/“否”。
![[Machine Learning] decision tree 决策树,机器学习,机器学习,决策树,人工智能](https://imgs.yssmx.com/Uploads/2023/08/665843-1.png)
一个具体化以后的模型差不多长这样子:给出一堆宠物的数据,根据不同的特征(耳朵,脸型什么的),我们判断输入案例是狗还是猫猫。
如果还是不好理解,那么想象一下我们平时在写代码时候大量if else嵌套,展开以后也是一模一样的结构。去别在于可能if构成的判断树的后代可能多于决策树,决策树只能是二叉树,输出“是”“不是”这种问题,当面对多个离散的特征值的时候,我们还有别的技术可以使用.
简而言之,决策树是一种区别于神经网络的另一种判断算法,在一些数据的处理上可能比神经网络更快更有效,由于其结构类似二叉树,所以称之为决策树(decision tree).决策树的生成是要根据已经给出的数据案例创建的,数据有多少特征用于区分,就会有多少个节点进行分裂(split).
具体的训练过程和训练中遇到的问题会在下面解释
在训练之前要接触的一些名词
纯净(purity)/杂质(impurity):纯度和不纯是根据某个节点来说的,例如我们输入一堆宠物的数据(包括耳朵形状,毛发长度,脸型这些特征),在判断某个属性的节点上,我们会根据"符合"/"不符合"把已有的数据划分为两拨.比如这样子![[Machine Learning] decision tree 决策树,机器学习,机器学习,决策树,人工智能](https://imgs.yssmx.com/Uploads/2023/08/665843-2.png)
原型的部分中,有四个是猫猫,三个是狗子.对于这个节点来说,我们可以认为这个节点的纯度是(4/7)
同理,另一个节点的纯度视为(1/3)
(纯度是一个相对的概念,如果你判断的是狗子,那么纯度就要变了)
熵:这个熵不是化学中的概念,而是代表混乱程度,当纯度和为0.5的时候,代表两种东西对半开,也就是最混乱的情况.根据纯度,我们有相关的公式可以计算出纯度对应熵的大小(假设纯度为p)
整个函数的图像大概就是这样子
![[Machine Learning] decision tree 决策树,机器学习,机器学习,决策树,人工智能](https://imgs.yssmx.com/Uploads/2023/08/665843-3.png)
信息增益:信息增益也是根据某一个点来说的,这个数值是训练时候的重要依据,信息增益越大,代表整个节点进行的划分越有效,信息增益的计算方式为
0.5对应的熵,减去左侧的熵和右侧的熵的加权平均和即可.比如上面的图,我们可以计算为
决策树如何进行训练
决策树底层的训练原理其实很简单,首先我们需要给定一个数据集合,这个数据集合中的每个事物都有一些共同的特征,类似这样,通常我们可以把有效的特征组合起来形成一个表格.
![[Machine Learning] decision tree 决策树,机器学习,机器学习,决策树,人工智能](https://imgs.yssmx.com/Uploads/2023/08/665843-4.png)
前面的特征为输入,而cat一列作为输出,决定这个宠物到底是不是猫,由此构成一系列符合监督学习要求的训练数据集合.
然后会从这些信息中,选择分裂时产生更小熵的特征,算法会基于某种标准(例如信息增益、基尼不纯度等)来评估每个可能的划分,并选择最优的划分特征。这些标准用于衡量数据的不纯度和分割后的纯度。这里我们使用上面讲到的信息增益来判断这个划分成都
![[Machine Learning] decision tree 决策树,机器学习,机器学习,决策树,人工智能](https://imgs.yssmx.com/Uploads/2023/08/665843-5.png)
由此可见,以耳朵形状作为划分所产生的分裂节点,信息增益更大,纯度也更好.
接下来再根据其他的特征进行划分即可,当遇到以下几种情况的时候,我们可以认为这个节点不用再继续分裂了
- 树的高度达到某些限制
- 纯度已经是100%
- 数据全部低于阈值
- ........
两个特殊情况
(1)分裂时候的数据不是二元的离散数值,而是一个连续的情况
这个很简单,设置一个阈值,比如0.5,0,7,....反正到最后还是二元的
(2)分裂的时候,可能数据是多元的离散数值,比如毛发可能是长发,短发,卷发这三种.我们总不能搞出三叉树来,所以这里我们把"是什么"转变为"是不是"的问题.比如这样一个特征,我们可以划分为"是不是长发,是不是短发,是不是卷毛"三个二元的特征
随机森林算法
给定一个数据集合,我们可以计算出一个决策树来进行一些判断,给定一个动物,决策树最红会给出我们这个是不是猫猫的答案.但是这有两个问题,节点不一定是纯净的(虽然大多数情况下,只要不超过我们的限定高度,是可以把一个决策树修炼到高度纯净的),造成判断结果不一定准确.
另一个问题就是,一些数据发生扰动以后,可能会影响决策树这个依托信息增益产生的精密系统.
最简单粗暴的方法就是,训练多个树,形成一个森林.但是一个数据集合练出来的树是一样的,没啥必要,所以我们产生了随机森林算法.
sampling with replacement(放回抽样)这东西我们在高中就学过,所以这里不加简述了.我们要做的就是确定一个规模,比如10,每次从原始数据集中抽取10个案例,然后用来训练一棵树.
如此循环多次,我们就能得到多个决策树,组成一个森林,这其中难免会有一些决策树是一样的,我们忽视掉它
![[Machine Learning] decision tree 决策树,机器学习,机器学习,决策树,人工智能](https://imgs.yssmx.com/Uploads/2023/08/665843-6.png)
这样我们计算结果的时候,要考虑到整个森林所有树木的输出效果,然后综合考虑我们怎样确定输出效果
XGBoost算法和使用
在众多随机森林算法中,XGBoost是一种使用很广泛的随机森林算法,并且XGBoost也是一个开源库(不是放在tf或者pytorch的库中的).XGBoost非常像我们之前聊过的增强算法(啥,哦博客还没写出来,8好意思,尽快补上)
XGBoost算法和普通决策树的区别在于放回抽样的不疯魔,传统的决策树是平等地抽取,xgb算法则是会根据上一次,估计错了哪些数值,在本次抽取中优先提取上一次参与训练并且估计失败的数值案例.
比如![[Machine Learning] decision tree 决策树,机器学习,机器学习,决策树,人工智能](https://imgs.yssmx.com/Uploads/2023/08/665843-7.png)
构建某一次决策树的时候,2,6,8号数据估计错误,则下一次会优先提取出这些作为训练案例之一.
当然这些主要是底层实现了(注意对应的函数从xgboost包中导入,这个包需要提前下载)
下面来看一下具体的使用案例.
pip3 install xgboost#xgboost算法 这里没有使用训练集合什么de
# 定义特征矩阵和标签
X = np.array([[1, 2], [3, 4], [5, 6], [7, 8]])
y = np.array([0, 0, 1, 1])
# 创建并训练模型
model = XGBClassifier()
model.fit(X, y)
# 预测一个数据
data_to_predict = np.array([[2, 3]])
prediction = model.predict(data_to_predict)
print(f"预测结果: {prediction}")
#xgboost算法 这里没有使用训练集合什么de
# 定义特征矩阵和标签
X = np.array([[1, 2], [3, 4], [5, 6], [7, 8]])
y = np.array([0, 0, 1, 1])
# 创建并训练模型
model = XGBClassifier()
model.fit(X, y)
# 预测一个数据
data_to_predict = np.array([[2, 3]])
prediction = model.predict(data_to_predict)
print(f"预测结果: {prediction}")和神经网络有什么区别捏?
相比于神经网络来说,决策树和随机森林算法更适合一些有固定相似数据结构的数据集合.换句话说,更容易处理那种可以形成表格的数据.
而神经网络则用来处理一些非相似结构的数据,这一点就是他们的主要区别
决策树同样是一种很重要的监督学习算法.
关于baseline(未完待续)
baseline是一种基于决策树的大模型,适用于多重二元分析等操作,在竞赛和论文中应用很广泛.
(至少与我们之前用到tensorflow要广泛.....tf都快开摆了)文章来源:https://www.toymoban.com/news/detail-665843.html
不过这个模型我现在也不是很熟悉,仅仅是停留在"用过"这个层面上,后面有机会我会继续在这里补充这个模型的使用和优缺点,文章来源地址https://www.toymoban.com/news/detail-665843.html
到了这里,关于[Machine Learning] decision tree 决策树的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!