疲劳驾驶检测和识别4:C++实现疲劳驾驶检测和识别(含源码,可实时检测)
目录
疲劳驾驶检测和识别4:C++实现疲劳驾驶检测和识别(含源码,可实时检测)
1.疲劳驾驶检测和识别方法
2.人脸检测方法
3.疲劳驾驶识别模型(Python)
(1) 疲劳驾驶识别模型的训练
(2) 将Pytorch模型转换ONNX模型
(3) 将ONNX模型转换为TNN模型
4.疲劳驾驶识别模型C/C++部署
(1)项目结构
(2)配置开发环境(OpenCV+OpenCL+base-utils+TNN)
(3)部署TNN模型
(4)CMake配置
(5)main源码
(6)源码编译和运行
(7)Demo测试效果
5.项目源码下载
这是项目《疲劳驾驶检测和识别》系列之《C++实现疲劳驾驶检测和识别(含源码,可实时检测)》,主要分享将Python训练后的疲劳驾驶检测和识别模型(mobilenet_v2)部署到C/C++平台。我们将开发一个简易的、可实时运行的疲劳驾驶检测和识别的C/C++ Demo。准确率还挺高的,采用轻量级mobilenet_v2模型的疲劳驾驶检测和识别准确率也可以高达97.86%左右,基本满足业务性能需求。C/C ++版本的疲劳驾驶检测和识别模型推理支持CPU和GPU加速,开启GPU(OpenCL)加速,可以达到实时的检测识别效果,基本满足业务的性能需求。

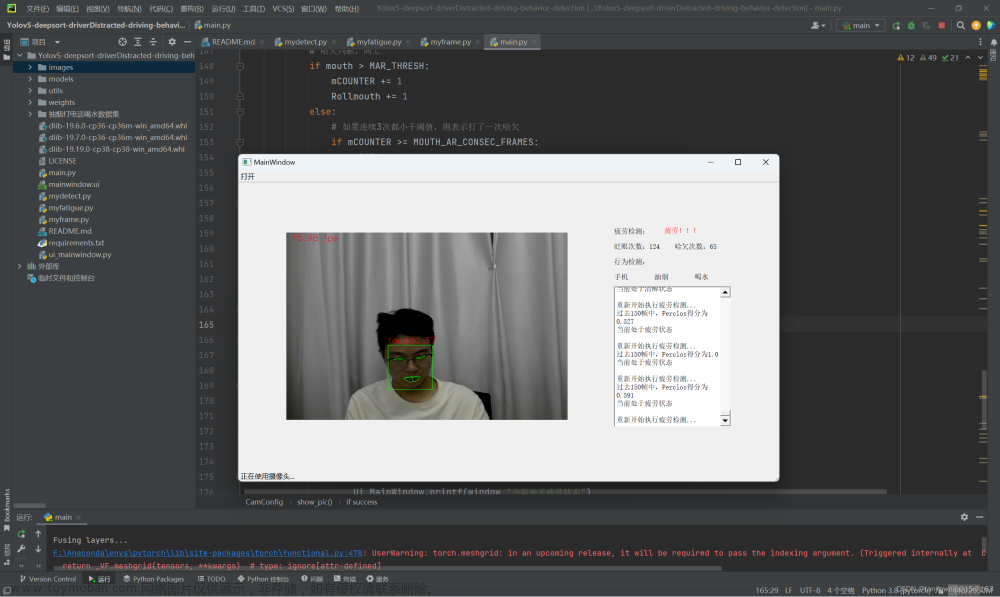
先展示一下,C/C++版本的疲劳驾驶检测和识别Demo效果(不同类别使用不同颜色表示):


【尊重原创,转载请注明出处】 https://blog.csdn.net/guyuealian/article/details/131834980
更多项目《疲劳驾驶检测和识别》系列文章请参考:
- 疲劳驾驶检测和识别1: 疲劳驾驶检测和识别数据集(含下载链接)https://blog.csdn.net/guyuealian/article/details/131718648
- 疲劳驾驶检测和识别2:Pytorch实现疲劳驾驶检测和识别(含疲劳驾驶数据集和训练代码)https://blog.csdn.net/guyuealian/article/details/131834946
-
疲劳驾驶检测和识别3:Android实现疲劳驾驶检测和识别(含源码,可实时检测)https://blog.csdn.net/guyuealian/article/details/131834970
-
疲劳驾驶检测和识别4:C++实现疲劳驾驶检测和识别(含源码,可实时检测)https://blog.csdn.net/guyuealian/article/details/131834980
1.疲劳驾驶检测和识别方法
疲劳驾驶检测和识别方法有多种实现方案,这里采用最常规的方法:基于人脸检测+疲劳驾驶分类识别方法,即先采用通用的人脸检测模型,进行人脸检测定位人体区域,然后按照一定规则裁剪人脸检测区域,再训练一个疲劳驾驶行为识别分类器,完成疲劳驾驶检测和识别任务;
这样做的好处,是可以利用现有的人脸检测模型进行人脸检测,而无需重新标注疲劳驾驶的人脸检测框,可减少人工标注成本低;而疲劳驾驶分类数据相对而言比较容易采集,分类模型可针对性进行优化。
当然,也可以直接基于目标检测的方法直接检测疲劳驾驶和非疲劳驾驶,Python版本的项目提供了疲劳驾驶目标检测的数据集
2.人脸检测方法
本项目人脸检测训练代码请参考:https://github.com/Linzaer/Ultra-Light-Fast-Generic-Face-Detector-1MB
这是一个基于SSD改进且轻量化后人脸检测模型,很slim,整个模型仅仅1.7M左右,在普通Android手机都可以实时检测。人脸检测方法在网上有一大堆现成的方法可以使用,完全可以不局限我这个方法。

关于人脸检测的方法,可以参考我的博客:
- 行人检测和人脸检测和人脸关键点检测(C++/Android源码)
- 人脸检测和行人检测2:YOLOv5实现人脸检测和行人检测(含数据集和训练代码)
3.疲劳驾驶识别模型(Python)
(1) 疲劳驾驶识别模型的训练
本篇博文不含python版本的疲劳驾驶识别分类模型以及相关训练代码,关于疲劳驾驶识别模型的训练方法,请参考本人另一篇博文:疲劳驾驶检测和识别2:Pytorch实现疲劳驾驶检测和识别(含疲劳驾驶数据集和训练代码)https://blog.csdn.net/guyuealian/article/details/131834946
(2) 将Pytorch模型转换ONNX模型
目前CNN模型有多种部署方式,可以采用TNN,MNN,NCNN,以及TensorRT等部署工具,鄙人采用TNN进行C/C++端上部署。部署流程可分为四步:训练模型->将模型转换ONNX模型->将ONNX模型转换为TNN模型->C/C++部署TNN模型。
训练好Pytorch模型后,我们需要先将模型转换为ONNX模型,以便后续模型部署。
- 原始项目提供转换脚本,你只需要修改model_file为你模型路径即可
- convert_torch_to_onnx.py实现将Pytorch模型转换ONNX模型的脚本
python libs/convert/convert_torch_to_onnx.py"""
This code is used to convert the pytorch model into an onnx format model.
"""
import sys
import os
sys.path.insert(0, os.getcwd())
import torch.onnx
import onnx
from classifier.models.build_models import get_models
from basetrainer.utils import torch_tools
def build_net(model_file, net_type, input_size, num_classes, width_mult=1.0):
"""
:param model_file: 模型文件
:param net_type: 模型名称
:param input_size: 模型输入大小
:param num_classes: 类别数
:param width_mult:
:return:
"""
model = get_models(net_type, input_size, num_classes, width_mult=width_mult, is_train=False, pretrained=False)
state_dict = torch_tools.load_state_dict(model_file)
model.load_state_dict(state_dict)
return model
def convert2onnx(model_file, net_type, input_size, num_classes, width_mult=1.0, device="cpu", onnx_type="default"):
model = build_net(model_file, net_type, input_size, num_classes, width_mult=width_mult)
model = model.to(device)
model.eval()
model_name = os.path.basename(model_file)[:-len(".pth")] + ".onnx"
onnx_path = os.path.join(os.path.dirname(model_file), model_name)
# dummy_input = torch.randn(1, 3, 240, 320).to("cuda")
dummy_input = torch.randn(1, 3, input_size[1], input_size[0]).to(device)
# torch.onnx.export(model, dummy_input, onnx_path, verbose=False,
# input_names=['input'],output_names=['scores', 'boxes'])
do_constant_folding = True
if onnx_type == "default":
torch.onnx.export(model, dummy_input, onnx_path, verbose=False, export_params=True,
do_constant_folding=do_constant_folding,
input_names=['input'],
output_names=['output'])
elif onnx_type == "det":
torch.onnx.export(model,
dummy_input,
onnx_path,
do_constant_folding=do_constant_folding,
export_params=True,
verbose=False,
input_names=['input'],
output_names=['scores', 'boxes', 'ldmks'])
elif onnx_type == "kp":
torch.onnx.export(model,
dummy_input,
onnx_path,
do_constant_folding=do_constant_folding,
export_params=True,
verbose=False,
input_names=['input'],
output_names=['output'])
onnx_model = onnx.load(onnx_path)
onnx.checker.check_model(onnx_model)
print(onnx_path)
if __name__ == "__main__":
net_type = "mobilenet_v2"
width_mult = 1.0
input_size = [128, 128]
num_classes = 2
model_file = "work_space/mobilenet_v2_1.0_CrossEntropyLoss/model/best_model_022_98.1848.pth"
convert2onnx(model_file, net_type, input_size, num_classes, width_mult=width_mult)
(3) 将ONNX模型转换为TNN模型
目前CNN模型有多种部署方式,可以采用TNN,MNN,NCNN,以及TensorRT等部署工具,鄙人采用TNN进行C/C++端上部署
TNN转换工具:
- (1)将ONNX模型转换为TNN模型,请参考TNN官方说明:TNN/onnx2tnn.md at master · Tencent/TNN · GitHub
- (2)一键转换,懒人必备:一键转换 Caffe, ONNX, TensorFlow 到 NCNN, MNN, Tengine (可能存在版本问题,这个工具转换的TNN模型可能不兼容,建议还是自己build源码进行转换,2022年9约25日测试可用)

4.疲劳驾驶识别模型C/C++部署
项目IDE开发工具使用CLion,相关依赖库主要有OpenCV,base-utils以及TNN和OpenCL(可选),其中OpenCV必须安装,OpenCL用于模型加速,base-utils以及TNN已经配置好,无需安装;
项目仅在Ubuntu18.04进行测试,Windows系统下请自行配置好开发环境。
(1)项目结构

(2)配置开发环境(OpenCV+OpenCL+base-utils+TNN)
项目IDE开发工具使用CLion,相关依赖库主要有OpenCV,base-utils以及TNN和OpenCL(可选),其中OpenCV必须安装,OpenCL用于模型加速,base-utils以及TNN已经配置好,无需安装;
项目仅在Ubuntu18.04进行测试,Windows系统下请自行配置和编译
- 安装OpenCV:图像处理
图像处理(如读取图片,图像裁剪等)都需要使用OpenCV库进行处理
安装教程:Ubuntu18.04安装opencv和opencv_contrib
OpenCV库使用opencv-4.3.0版本,opencv_contrib库暂时未使用,可不安装
- 安装OpenCL:模型加速
安装教程:Ubuntu16.04 安装OpenCV&OpenCL
OpenCL用于模型GPU加速,若不使用OpenCL进行模型推理加速,纯C++推理模型,速度会特别特别慢
- base-utils:C++库
GitHub:https://github.com/PanJinquan/base-utils (无需安装,项目已经配置了)
base_utils是个人开发常用的C++库,集成了C/C++ OpenCV等常用的算法
- TNN:模型推理
GitHub:https://github.com/Tencent/TNN (无需安装,项目已经配置了)
由腾讯优图实验室开源的高性能、轻量级神经网络推理框架,同时拥有跨平台、高性能、模型压缩、代码裁剪等众多突出优势。TNN框架在原有Rapidnet、ncnn框架的基础上进一步加强了移动端设备的支持以及性能优化,同时借鉴了业界主流开源框架高性能和良好拓展性的特性,拓展了对于后台X86, NV GPU的支持。手机端 TNN已经在手机QQ、微视、P图等众多应用中落地,服务端TNN作为腾讯云AI基础加速框架已为众多业务落地提供加速支持。
(3)部署TNN模型
项目实现了C/C++版本的疲劳驾驶检测和识别,模型推理采用TNN部署框架(支持多线程CPU和GPU加速推理);图像处理采用OpenCV库,模型加速采用OpenCL,在普通设备即可达到实时处理。
如果你想在这个 Demo部署你自己训练的模型,你可将训练好的Pytorch模型转换ONNX ,再转换成TNN模型,然后把原始的模型替换成你自己的TNN模型即可。
(4)CMake配置
这是CMakeLists.txt,其中主要配置OpenCV+OpenCL+base-utils+TNN这四个库,Windows系统下请自行配置和编译
cmake_minimum_required(VERSION 3.5)
project(Detector)
add_compile_options(-fPIC) # fix Bug: can not be used when making a shared object
set(CMAKE_CXX_FLAGS "-Wall -std=c++11 -pthread")
#set(CMAKE_CXX_FLAGS_RELEASE "-O2 -DNDEBUG")
#set(CMAKE_CXX_FLAGS_DEBUG "-g")
if (NOT CMAKE_BUILD_TYPE AND NOT CMAKE_CONFIGURATION_TYPES)
# -DCMAKE_BUILD_TYPE=Debug
# -DCMAKE_BUILD_TYPE=Release
message(STATUS "No build type selected, default to Release")
set(CMAKE_BUILD_TYPE "Release" CACHE STRING "Build type (default Debug)" FORCE)
endif ()
# opencv set
find_package(OpenCV REQUIRED)
include_directories(${OpenCV_INCLUDE_DIRS} ./src/)
#MESSAGE(STATUS "OpenCV_INCLUDE_DIRS = ${OpenCV_INCLUDE_DIRS}")
# base_utils
set(BASE_ROOT 3rdparty/base-utils) # 设置base-utils所在的根目录
add_subdirectory(${BASE_ROOT}/base_utils/ base_build) # 添加子目录到build中
include_directories(${BASE_ROOT}/base_utils/include)
include_directories(${BASE_ROOT}/base_utils/src)
MESSAGE(STATUS "BASE_ROOT = ${BASE_ROOT}")
# TNN set
# Creates and names a library, sets it as either STATIC
# or SHARED, and provides the relative paths to its source code.
# You can define multiple libraries, and CMake buil ds it for you.
# Gradle automatically packages shared libraries with your APK.
# build for platform
# set(TNN_BUILD_SHARED OFF CACHE BOOL "" FORCE)
if (CMAKE_SYSTEM_NAME MATCHES "Android")
set(TNN_OPENCL_ENABLE ON CACHE BOOL "" FORCE)
set(TNN_ARM_ENABLE ON CACHE BOOL "" FORCE)
set(TNN_BUILD_SHARED OFF CACHE BOOL "" FORCE)
set(TNN_OPENMP_ENABLE ON CACHE BOOL "" FORCE) # Multi-Thread
#set(TNN_HUAWEI_NPU_ENABLE OFF CACHE BOOL "" FORCE)
add_definitions(-DTNN_OPENCL_ENABLE) # for OpenCL GPU
add_definitions(-DTNN_ARM_ENABLE) # for Android CPU
add_definitions(-DDEBUG_ANDROID_ON) # for Android Log
add_definitions(-DPLATFORM_ANDROID)
elseif (CMAKE_SYSTEM_NAME MATCHES "Linux")
set(TNN_OPENCL_ENABLE ON CACHE BOOL "" FORCE)
set(TNN_CPU_ENABLE ON CACHE BOOL "" FORCE)
set(TNN_X86_ENABLE OFF CACHE BOOL "" FORCE)
set(TNN_QUANTIZATION_ENABLE OFF CACHE BOOL "" FORCE)
set(TNN_OPENMP_ENABLE ON CACHE BOOL "" FORCE) # Multi-Thread
add_definitions(-DTNN_OPENCL_ENABLE) # for OpenCL GPU
add_definitions(-DDEBUG_ON) # for WIN/Linux Log
add_definitions(-DDEBUG_LOG_ON) # for WIN/Linux Log
add_definitions(-DDEBUG_IMSHOW_OFF) # for OpenCV show
add_definitions(-DPLATFORM_LINUX)
elseif (CMAKE_SYSTEM_NAME MATCHES "Windows")
set(TNN_OPENCL_ENABLE ON CACHE BOOL "" FORCE)
set(TNN_CPU_ENABLE ON CACHE BOOL "" FORCE)
set(TNN_X86_ENABLE ON CACHE BOOL "" FORCE)
set(TNN_QUANTIZATION_ENABLE OFF CACHE BOOL "" FORCE)
set(TNN_OPENMP_ENABLE ON CACHE BOOL "" FORCE) # Multi-Thread
add_definitions(-DTNN_OPENCL_ENABLE) # for OpenCL GPU
add_definitions(-DDEBUG_ON) # for WIN/Linux Log
add_definitions(-DDEBUG_LOG_ON) # for WIN/Linux Log
add_definitions(-DDEBUG_IMSHOW_OFF) # for OpenCV show
add_definitions(-DPLATFORM_WINDOWS)
endif ()
set(TNN_ROOT 3rdparty/TNN)
include_directories(${TNN_ROOT}/include)
include_directories(${TNN_ROOT}/third_party/opencl/include)
add_subdirectory(${TNN_ROOT}) # 添加外部项目文件夹
set(TNN -Wl,--whole-archive TNN -Wl,--no-whole-archive)# set TNN library
MESSAGE(STATUS "TNN_ROOT = ${TNN_ROOT}")
# Detector
include_directories(src)
set(SRC_LIST
src/object_detection.cpp
src/classification.cpp
src/Interpreter.cpp)
add_library(dmcv SHARED ${SRC_LIST})
target_link_libraries(dmcv ${OpenCV_LIBS} base_utils)
MESSAGE(STATUS "DIR_SRCS = ${SRC_LIST}")
add_executable(Detector src/main.cpp)
#add_executable(Detector src/main_for_detect.cpp)
#add_executable(Detector src/main_for_yolov5.cpp)
target_link_libraries(Detector dmcv ${TNN} -lpthread)
(5)main源码
主程序中函数main实现提供了疲劳驾驶识别的使用方法,支持图片,视频和摄像头测试
- test_image_file(); // 测试图片文件
- test_video_file(); // 测试视频文件
- test_camera(); //测试摄像头
//
// Created by Pan on 2020/6/24.
//
#include "object_detection.h"
#include "classification.h"
#include <iostream>
#include <string>
#include <vector>
#include "file_utils.h"
#include "image_utils.h"
using namespace dl;
using namespace vision;
using namespace std;
const int num_thread = 1; // 开启CPU线程数目
DeviceType device = GPU; // 选择运行设备CPU/GPU
// 人脸检测模型
const char *det_model_file = (char *) "../data/tnn/face/rfb-face-mask-320-320_sim.opt.tnnmodel";
const char *det_proto_file = (char *) "../data/tnn/face/rfb-face-mask-320-320_sim.opt.tnnproto";
ObjectDetectionParam model_param = FACE_MODEL;//模型参数
// 疲劳驾驶分类模型
const char *cls_model_file = (char *) "../data/tnn/drowsy/mobilenet_v2_112_112.tnnmodel";
const char *cls_proto_file = (char *) "../data/tnn/drowsy/mobilenet_v2_112_112.tnnproto";
ClassificationParam ClassParam = DROWSY_MODEL;//模型参数
// 设置检测阈值
const float scoreThresh = 0.5;
const float iouThresh = 0.3;
ObjectDetection *detector = new ObjectDetection(det_model_file,
det_proto_file,
model_param,
num_thread,
device);
Classification *classifier = new Classification(cls_model_file,
cls_proto_file,
ClassParam,
num_thread,
device);
/***
* 测试图片文件
*/
void test_image_file() {
//测试图片的目录
string image_dir = "../data/test_image";
std::vector<string> image_list = get_files_list(image_dir);
for (string image_path:image_list) {
cv::Mat bgr_image = cv::imread(image_path);
if (bgr_image.empty()) continue;
FrameInfo resultInfo;
// 进行人脸检测
detector->detect(bgr_image, &resultInfo, scoreThresh, iouThresh);
// 进行图像分类
classifier->detect(bgr_image, &resultInfo);
// 可视化检测结果
classifier->visualizeResult(bgr_image, &resultInfo);
}
delete detector;
detector = nullptr;
delete classifier;
classifier = nullptr;
printf("FINISHED.\n");
}
/***
* 测试视频文件
* @return
*/
int test_video_file() {
//测试视频文件
string video_file = "../data/video/video-test.mp4";
cv::VideoCapture cap;
bool ret = get_video_capture(video_file, cap);
cv::Mat frame;
while (ret) {
cap >> frame;
if (frame.empty()) break;
FrameInfo resultInfo;
// 进行人脸检测
detector->detect(frame, &resultInfo, scoreThresh, iouThresh);
// 进行图像分类
classifier->detect(frame, &resultInfo);
// 可视化检测结果
classifier->visualizeResult(frame, &resultInfo, 20);
}
cap.release();
delete detector;
detector = nullptr;
delete classifier;
classifier = nullptr;
printf("FINISHED.\n");
return 0;
}
/***
* 测试摄像头
* @return
*/
int test_camera() {
int camera = 0; //摄像头ID号(请修改成自己摄像头ID号)
cv::VideoCapture cap;
bool ret = get_video_capture(camera, cap);
cv::Mat frame;
while (ret) {
cap >> frame;
if (frame.empty()) break;
FrameInfo resultInfo;
// 进行人脸检测
detector->detect(frame, &resultInfo, scoreThresh, iouThresh);
// 进行图像分类
classifier->detect(frame, &resultInfo);
// 可视化检测结果
classifier->visualizeResult(frame, &resultInfo, 20);
}
cap.release();
delete detector;
detector = nullptr;
delete classifier;
classifier = nullptr;
printf("FINISHED.\n");
return 0;
}
int main() {
test_image_file(); // 测试图片文件
//test_video_file(); // 测试视频文件
//test_camera(); //测试摄像头
return 0;
}
(6)源码编译和运行
编译脚本,或者直接:bash build.sh
#!/usr/bin/env bash
if [ ! -d "build/" ];then
mkdir "build"
else
echo "exist build"
fi
cd build
cmake ..
make -j4
sleep 1
./demo
- 如果你要测试CPU运行的性能,请修改src/main.cpp
DeviceType device = CPU;
- 如果你要测试GPU运行的性能,请修改src/main.cpp (需配置好OpenCL)
DeviceType device = GPU;
PS:纯CPU C++推理模式比较耗时,需要几秒的时间,而开启OpenCL加速后,GPU模式耗时仅需十几毫秒,性能极大的提高。
(7)Demo测试效果
C++版本与Python版本的结果几乎是一致,下面是疲劳驾驶识别效果展示(其中不同类别用不同颜色表示了)
 |
 |
 |
 |
 |
 |
5.项目源码下载
C++实现疲劳驾驶识别项目源码下载地址:C++实现疲劳驾驶检测和识别(含源码,可实时检测)
整套项目源码内容包含:
- 提供C/C++版本的人脸检测模型
- 提供C/C++版本的疲劳驾驶识别分类模型
- C++源码支持CPU和GPU,开启GPU(OpenCL)可以实时检测和识别(纯CPU推理速度很慢,模型加速需要配置好OpenCL,GPU推理约15ms左右)
- 项目配置好了base-utils和TNN,而OpenCV和OpenCL需要自行编译安装
- C/C++ Demo支持图片,视频,摄像头测试
Android疲劳驾驶检测和识别APP Demo体验:https://download.csdn.net/download/guyuealian/88088257文章来源:https://www.toymoban.com/news/detail-666092.html
如果你需要疲劳驾驶检测和识别的训练代码,请参考:《疲劳驾驶检测和识别2:Pytorch实现疲劳驾驶检测和识别(含疲劳驾驶数据集和训练代码)》https://blog.csdn.net/guyuealian/article/details/131834946文章来源地址https://www.toymoban.com/news/detail-666092.html
到了这里,关于疲劳驾驶检测和识别4:C++实现疲劳驾驶检测和识别(含源码,可实时检测)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!