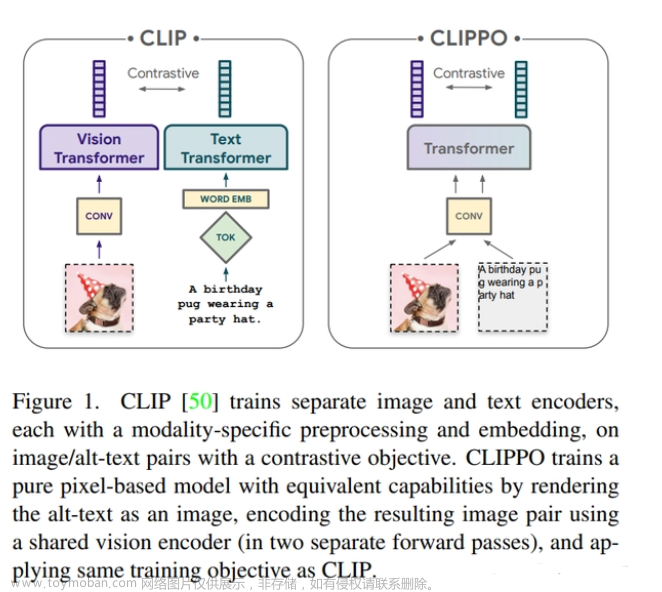
转眼就要博0了,导师开始让我看视频理解多模态方向的内容,重新一遍打基础吧,从Python,到NLP,再到视频理解,最后加上凸优化,一步一步来,疯学一个暑假。写这个博客作为我的笔记以及好文章的链接搬运,以便以后复习。
Python从入门到放弃
视频理解类Papers整理
万字长文漫谈视频理解
视频理解综述:动作识别、时序动作定位、视频Embedding
视频理解/动作分类 模型汇总(2022.06.28 更新)
计算机视觉中video understanding领域有什么研究方向和比较重要的成果?
视频多模态预训练/检索模型
视频多模态预训练/检索模型(二)
多模态视频文本时序定位
多模态预训练文章笔记
CVPR2020 Tutorial on Video Modeling
CVPR2021 2nd Tutorial on Video Modeling
ICCV2021 Tutorial on Multi-modality Learning
一.多模态大模型
1.1 统一架构
多模态大模型都是Transformer based架构,NLP对文本进行embedding,CV对图像patch进行Embedding,从图像、视频、文本、语音数据中提取特征,转换为tokens,进行不同模态特征的对齐,送入Transformer进行运算。
1.2 模型基础
预训练语言模型的前世今生 - 从Word Embedding到RNN/LSTM到Transformer到GPT到BERT 看完√
1.2.1 Transformer
Transformer 是一种基于自注意力机制(self-attention)的序列到序列(sequence-to-sequence)模型。它使用了多头注意力机制,能够并行地关注不同位置的信息。Transformer 在自然语言处理领域中广泛应用,如机器翻译和文本生成。Masked-MultiHead Attetion:独立学习得到 head 组不同的 线性投影(linear projections)来变换查询、键和值。然后,这 head 组变换后的查询、键和值将并行地进行注意力计算。最后,将这 head 个注意力计算的输出拼接在一起,允许注意力机制组合使用查询、键和值的不同的 子空间表示(representation subspaces)。


1.2.2 ViT
ViT(Vision Transformer)是一种将 Transformer 模型应用于图像分类任务的方法。它将图像分割为一系列的小块patch,并将每个小块作为序列输入 Transformer 模型。通过自注意力机制,ViT 能够在图像中捕捉全局和局部的视觉信息,实现图像分类。
1.2.3 Bert
Bert (Bidirectional Encoder Representations from Transformers)是一种 Transformer Encoder-Only 双向编码模型,通过大量无标记数据进行预训练和微调的方式,提供了深度的语言理解能力的语言特征提取模型。与传统的单向语言模型不同,Bert 同时考虑了上下文的信息,使得它在词义消歧、命名实体识别等任务上具有优势。
双向编码的Bert如何使用无监督预训练?训练时,将输入序列mask掉15%的词(token),然后做完形填空(根据上下文预测中间的词),预测mask的词。测试阶段没有mask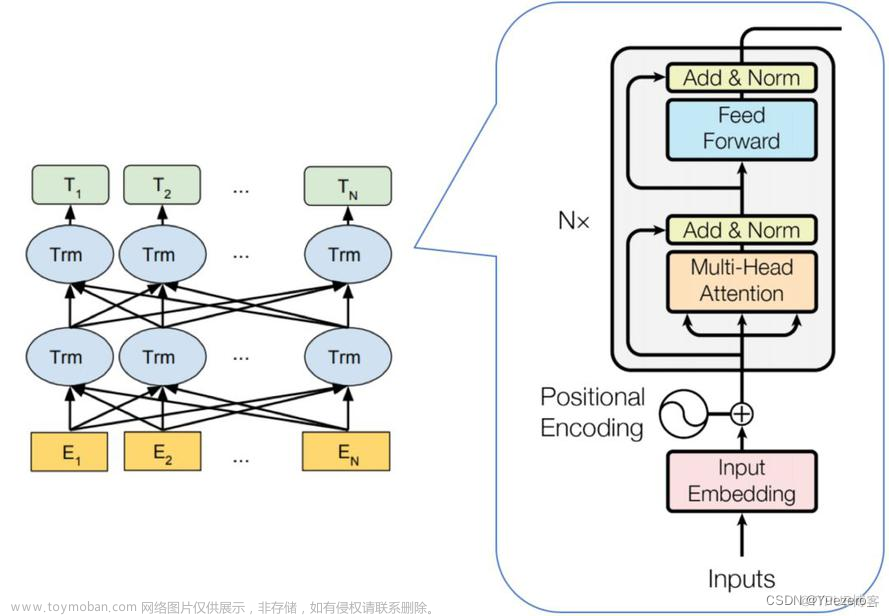
1.2.4 GPT
GPT(Generative Pretrained Transformer)是一种基于 Transformer Decoder-Only 单向编码 模型的预训练语言生成模型。GPT 通过大规模的无监督训练来学习语言的语法和语义,能够生成连贯且逼真的文本。GPT 在文本生成、对话系统等任务中取得了显著的成果。预训练语言模型之GPT-1,GPT-2和GPT-3
- GPT-1:无监督训练(
文字接龙,根据前文预测下文,不是完形填空) + 有监督微调(堆叠12层Transformer decoder) - GPT-2:无监督训练 + 多任务zero-shot(不进行有监督微调,堆叠48层Transformer decoder)
- GPT-3:无监督训练 + 更大的数据集和模型参数(堆叠96层Transformer decoder)



1.2.5 CrossAttention
CrossAttention 是 Transformer 模型中的一种注意力机制。与自注意力机制不同,CrossAttention 允许模型在处理输入序列时,同时关注另一个相关的序列。CrossAttention 在多模态任务中经常使用,例如将图像和文本进行对齐或生成多模态表示。(Q和K不同源,K和V同源)
1.2.6 CLIP
CLIP (Contrastive Language-Image Pretraining)是一种跨模态的预训练模型,它能够同时处理图像和文本。通过将图像和文本进行对比学习,CLIP 提供了一个共享的视觉和语义空间,使得图像和文本可以进行直接的匹配和检索。
1.2.7 预训练Pretrain(迁移学习)
通过 ImageNet 数据集我们训练出一个模型 A。由于上面提到 CNN 的浅层学到的特征通用性特别强,我们可以对模型 A 做出一部分改进得到模型 B(两种方法):
- 冻结(adapter):浅层参数使用模型 A 的参数,高层参数随机初始化,浅层参数一直不变,然后利用领导给出的 30 张图片训练参数。
- 微调(finetune):浅层参数使用模型 A 的参数,高层参数随机初始化,然后利用领导给出的 30 张图片训练参数,但是在这里浅层参数会随着任务的训练不断发生变化。

1.2.6 微调Finetune
在大规模无标签数据上训练Pretrain得到预训练模型,再在小规模数据集上进行微调训练Finetune,成为某个特定任务的专才,如机器翻译、摘要生成。Bert走的路线
1.2.7 提示Prompt
在大规模无标签数据上训练Pretrain得到预训练模型,人类提供一些提示指令Prompt,成为可以解决所有问题的通才,根据Prompt来完成不同的任务。GPT走的路线
1.2.8 迁移与零样本学习
迁移学习(小模型) 通常使用较小的模型,在源领域训练好的知识和参数可以被迁移到目标领域,从而加速目标任务的学习过程。这种方式可以提高模型的泛化能力和效果,在数据稀缺的情况下也能取得较好的结果。
Zero-shot(大模型) 解决从未见过类别的样本进行分类的问题。在零样本学习中,我们通常使用大模型,如GPT-3等。这些模型在训练阶段通过学习大规模数据获取了广泛的知识,并且能够通过关联不同领域的知识来进行分类。通过利用这些大模型的泛化能力,我们可以在没有见过的类别上进行分类,实现零样本学习。
1.2.8 拓展阅读
CLIP——图文匹配
(1) 预训练图像和文本编码器:训练<图片,文本>对,进行对比学习。N个图像和N个文本,用Bert和ViT提取文本和图片的特征(768维),向量两两相乘,得到<图片,文本>对儿之间的余弦相似度(向量乘法)。标签对比学习:对角线上相匹配的图文是正样本(正确的pair=1),其他不匹配的全是负样本(错误的pair=0),这两个标签计算loss反向传播,最大化正样本对的余弦相似度,最小化负样本对的优余弦相似度,约束前面的Bert和ViT梯度下降修改参数。最终预训练得到文本和图像编码器Bert和ViT。
(2)和(3) Zero-shot实现图文匹配:根据刚刚的预训练,任意给出文本(dog、car、cat…)与图片计算余弦相似度(相乘),相似度分数最大的就是正确的<图片,文本>对
BLIP——图文匹配&图生文
(1)对比学习ITC:图片编码器提取的向量 与 第一个文本编码器提取的向量,进行对比学习。(bert的双向注意力)
(2)二分类任务ITM:图片编码器提取的向量 与 第二个文本编码器提取的向量进行cross attention,融合的向量进行二分类任务(文本和图片是不是描述的同一件事),以更细粒度的让文本和图像的难样本对齐。(bert的双向注意力)
(3)生成任务LM:图片编码器提取的向量 与 第三个文本编码器提取的向量进行cross attention,融合的向量进行文本生成任务(根据图像生成描述文本)。(gpt的单向注意力)

BLIP2——图文匹配&图生文
(1)阶段一:使用QFormer将 图像特征向量 投影到 文本特征空间,使得LLM可以理解图像向量的特征。
(2)阶段二:把图片特征输入LLM(作为prompt),生成对应的图像的文本描述。
BLIP2对细节理解不到位的原因:ViT的patch级tokenlization对细节处理不到位。
DALL·E——文生图
(1)训练过程:将图片编码为one-hot向量,再解码为一只狗,实现无损压缩图像。(loss是原图和解码图片的差别)

(2)推理过程:自回归编码器(GPT)通过文本tokens预测出多种图片tokens,再解码为对应的图片,最后使用CLIP进行图文匹配,得到解码图片中与文本最相似的图片。
VisualGLM——中文版BLIP2
使用Lora训练。
但文本生成经常胡说八道,原因在于ChatGLM的模型规模太小7B。
1.3 多模态预训练
图文音多模态数据的不断增多,多模态大模型能力也持续涌现。
大规模数据 + T r a n s f o r m e r 架构 + 自监督预训练 P r e t r a i n + 下游微调 F i n e T u n e 大规模数据 + Transformer架构 + 自监督预训练Pretrain + 下游微调Fine Tune 大规模数据+Transformer架构+自监督预训练Pretrain+下游微调FineTune

1.3.1 多模态数据集


1.3.1 多模态模型架构
- Encoder-only:Bert双向理解
- Decoder-only:GPT单向生成
- Encoder+Decoder:Transformer理解+生成(Encoder Decoder串行/并行)




1.3.3 自监督预训练
- 模态内掩码学习:在任意一个模态内部进行token级别的掩码,像Bert一样,对一句话的不同单词的token进行掩码。
- 模态间掩码学习:比如对text进行掩码,通过video信息对文本进行预测。
-
模态间的匹配学习:模态内的匹配学习(对图像进行变换角度,预测角度等自监督任务)、模态间的匹配学习(如CLIP这种对比学习的方式进行图文模态间的匹配)

1.3.4 下游微调
- 模型微调:全参数微调、部分参数微调
- 下游任务:对模态组合,定义更好的下游任务

1.3.5 前景展望
经典工作
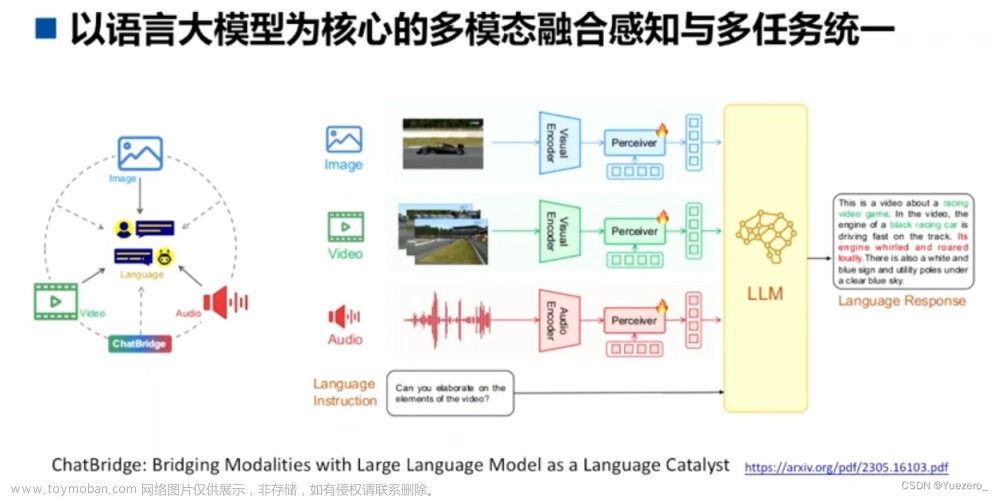
以语言大模型为核心的多模态融合感知模型





二.语言大模型分类
学习哪些大模型?(训练不同规模的模型适应不同场景)
- 在线大模型:OpneAI系列的大模型组

- 开源大模型:ChatGLM 6B 和 VisualGM 6B

2.1 在线大模型
需要OpenAI的key,私人数据被openai共享,不能部署在本地,只能调用API接口在线微调Openai公司的大模型。
语言大模型:
图文多模态大模型:
语音大模型:
文本嵌入大模型:根据文本语义编码,语义越接近,向量越接近。
审查大模型:
编程大模型:
2.2 开源大模型
根据下游任务使用开源微调框架进行微调训练,也可以本地部署。
实时更新的OPEN LLM排行榜
ChatGLM——中文语言开源大模型





VisualGLM——中文多模态开源大模型



三. 大模型微调
-
全量微调(Full Fine-tuning,FT)将预训练好的模型的所有参数都进行微调,包括底层的特征提取器和顶层的分类器。这种方法通常需要较大的计算资源和长时间的训练,但可以获得相对较好的性能。
-
高效微调(Partial Fine-tuning,PEFT)则是一种更加高效的微调方法,它仅对部分参数进行微调。具体来说,我们冻结预训练模型的底层参数(如特征提取器)不进行微调,只微调顶层的分类器或一部分顶层参数。这样可以更快地完成微调过程,减少计算资源和训练时间的消耗,同时在一定程度上保留了底层参数的知识。
-
基于强化学习的进阶微调(Reinforcement Learning-based Hierarchical Fine-tuning,RLHF)使用强化学习的思想来指导微调的过程。通常,在微调过程中,我们定义一个奖励函数并通过强化学习的方式来最大化奖励。这样可以使得模型在微调过程中更加智能地进行参数更新,从而获得更好的性能和泛化能力。


3.1 高效微调 PEFT

3.1.1 LoRA


3.1.2 Prefix Tuning

3.1.3 Prompt Tuning

3.1.4 P-Tuning V2

3.2 RLHF


四.硬件和操作系统要求

4.1 显卡





4.2 操作系统

五. LangChian










六.视频理解
6.1 TASK
4个基础任务:动作识别(Action Recognition)、时序动作定位(Temporal Action Localization)、时空动作检测(Spation Temporal Action Detection)、视频Embedding
6.1.1 行为识别——Action Recognition

6.1.2 时序动作检测——Temporal Action Detction

基于内容的检索——Moment Retrieval
关键片段定位——Highlight Detection
6.1.3 时空动作检测——Spation Temporal Action Detection

挑战:
挑战1方案:静态的外观特征 + 帧间空间运动特征
思路1:先提取静态外观特征,再使用不同帧的静态外观特征,提取动态运动特征。
思路2:同时并行提取静态外观特征 和 时序运动特征,再进行融合。
思路3:使用更加强大的架构,直接提取综合特征。
挑战2: 视频数据包含的帧数太多,计算量巨大

挑战3: 难以标注海量视频数据
6.2 经典工作


-
深度学习视频理解方法开山始祖(2014):
DeepVideo(AlexNet用于视频分类) -
双流网络系列(2014-2017):
Two Stream Network(增加光流分支学习时序信息)、TDD(提出轨迹卷积,感受野按照轨迹的偏移在时序上将卷积位置偏移到对应的点上去)、LRCN(将CNN提取的特征送入LSTM进行时序建模)、Fusion(探究early and late fusion)、TSN(分段抽帧进行长时间建模) -
3D CNN系列(2015-2020):
C3D(三维卷积核来建模视频时间信息)、I3D(膨胀2D预训练权重到3D进行初始化)、R(2+1)D(将3D卷积分解为2D+1D减少计算量)、Non-local(在I3D基础上使用self-attention进行长距离时空序列建模)、SlowFast(双流快慢帧采样分支进行3D卷积侧向链接融合) -
Video Transformer系列(2020-至今):
TimeSformer、VidTr、ViViT、MviT、Video Swin Transformer、VATT、BeiT

6.2.1 光流Optical Flow 传统方法

光流估计:
轨迹追踪:

光流可视化:
稀疏光流与稠密光流:
稠密轨迹方法 Dense Trajectories(DT)

按轨迹对齐的局部特征:
特征编码:对提取到的轨迹特征进行聚类,得到不同的聚类中心(视觉词语),构成直方图来表示整个视频特征。
稠密轨迹方法 iDT

6.2.2 2D卷积
DeepVideo
DeepVideo [CVPR 14] 是在Alexnet出现之后,在深度学习时代,使用超大规模的数据集,使用比较深的卷积神经网络去做的视频理解(DeepVideo是处理视频理解的最早期工作之一)。
DeepVideo论文中的方法是比较直接的,论文中的想法就是如何将卷积神经网络从图片识别应用到视频识别中。视频与图片的不同在于,视频多了一个时间轴(有更多的视频帧)。所以论文中尝试了以下几个变体(下图后3种):

- Single frame单帧,其实就是一个图片分类的任务。在视频里任选一帧,然后把这一帧通过一个卷积神经网络,然后通过两个FC,最后得到分类结果,这个其实就是一个baseline。它完全没有时间信息,也没有视频信息在里面。
- Late Fusion晚融合,之所以叫Late,就是因为它在网络输出层做的一些结合。如上图,从视频中,随机选几帧,然后每一帧都单独通过一个卷积神经网络,这两个神经网络是权值共享的,将两个特征合并,再通过FC全连接层,最后做输出。 这样就稍微有一些时序上的信息了。
- Early Fusion早融合,作者在输入层就做了融合。具体做法就是在RGB在Channel上直接合起来。原来一张图片,有3个channel,现在有5张图片,就有3x5=15个channel。那就意味着网络结构要进行一定的改变了,尤其是第一层。这样的做法,可以在输入层就可以感受到时序上的改变,希望能学到一些全局的运动或者时间信息。
- Slow Fusion是在Late Fusion 和 Early Fusion的基础上提出,Late Fusion合并太晚,Early Fusion合并太早了,Slow Fusion在特征层面做了一些融合。具体做法就是选19个视频帧的1个小的视频片段,每4个视频帧就通过一个卷积神经网络,刚开始的层也是权值共享的,在抽出最开始的这些特征之后,由最开始的4个输入片段,慢慢合并成2个输入片段,再去做一些卷积操作,去学习更深层的特征。然后在融合2个特征,最后把学习到的特征给FC。
实验结结果表明,Slow Fusion结果较好(相对于前三个)。但是从总体看来,这几种方法的差别都不大。即使在100万个视频上去做了预训练之后,在UCF101小数据集上去做迁移学习的时候,效果竟然还比不上之前的手工特征。
其实这篇文章的意义,不在于它的效果,作者不仅提出了当时最大的视频理解数据集Sport1M,而且把你能想到的,最直接的方式,全都试了一遍,为后续的工作做了一个很好的铺垫。这才有了深度学习在视频领域的飞速发展。所以到了18、19年,视频理解(或者动作识别),已经是CV领域排名前5、6的关键词。
Two-Stream Networks 双流网络
所谓two-stream是指空间stream和时间stream,视频可以分成空间与时间两个部分:Spatio Stream Convet处理静态的帧画面,输入是单个帧画面,得到画面中物体的特征,还可以使用ImageNet challenge数据集种有标注的图像数据进行预训练。Temporal Stream Convet则是通过多帧画面的光流位移来获取画面中物体的运动信息,其输入由多个连续帧之间的光流位移场叠加而成,这种输入显式地描述了视频帧之间的运动,这使得识别更加容易,因为网络不需要隐式地估计运动。两个不同的stream都通过CNN实现,最后进行信息融合。

光流(Optical flow) 是由一些位移矢量场(displacement vector fields)(每个矢量用dt表示)组成的,其中dt是一个向量,表示第t帧的displacement vector,是通过第t和第t+1帧图像得到的。dt包含水平光流
d
t
x
dt_x
dtx和竖直光流
d
t
y
dt_y
dty。因此如果一个video有L帧,那么一共可以得到2L个channel的optical flow,然后才能作为temporal stream convnet网络的输入。(一般用TVL1算法)
所以如果假设一个video frame的宽和高分别是w和h,那么Temporal stream convnet输入的光流图像维度应该是下面这样的。其中 t 表示任意的一帧。
I
t
⊆
R
w
×
h
×
2
L
I_t\subseteq R^{w \times h \times 2L}
It⊆Rw×h×2L
本文实验讨论了2种光流:光流栈(Optical flow stacking)(计算起始帧与每帧之间的光流,然后简单的stacking)、轨迹叠加(Trajectory stacking)(计算相邻两帧之间的光流,假设第一帧的某个像素点,我们可以通过光流来追踪它在视频中的轨迹,即用来描述一个对应特征点连续的光流变化)
multi-task learning:首先原来的网络(temporal stream convnet)在全连接层后只有一个softmax层,现在要变成两个softmax层,一个用来计算HDMB-51数据集的分类输出,另一个用来计算UCF-101数据集的分类输出,这就是两个task。这两条支路有各自的loss,最后回传loss的时候采用的是两条支路loss的和。
问题:1.缺乏长时间建模(LSTM、3D CNN、TSN);2.双流网络的early fusion效果怎么样?(early fusion)3.为什么轨迹光流比光流栈效果差?(TDD)
TSN 时序分段网络

做对了什么?
抽帧策略
一段完整的视频,包含的视频帧是非常多的,那么全部处理这些视频帧数据显然是不现实的,所以只能采用抽帧策略,TSN中的抽帧策略,个人感觉比较不错。
按照新的视频时间分段采样方式,而不是按照固定频率去采样,使得网络分析的时间范围更长。每个双流网络是共享参数的。
在TSN中,视频首先被等间隔分为K个片段,根据视频的时间分布来设置K,比如K=16,即一段视频被分成了16个片段,在每个片段中随机抽取一帧数据作为输入(测试的时需要固定,一般测试的时候可以选择中间帧),这样避免了采用过于连续帧之间的信息冗余,同时又尽可能利用到更多的视频信息。
数据增强
由于数据有限,为了更好的训练模型,作者采用了数据增强,主要包括location jittering, horizontal flipping, corner cropping, and scale jittering,作者通过实验证明了在图像领域常用的数据增强手段,在视频分类的任务中同样有效。
多帧融合
TSN中,作者采用的多帧融合(不同时间片段分类结果的融合)方式比较简单,直接取了平均(先空间融合,再时间融合,最后时空取平均),后续会介绍更为复杂的视频帧融合的方式。
多模态融合
这里的多模态融合是指RGB输入和光流输入的融合,作者采用的是结果融合。由于这篇论文是16年的文章,所以多模态融合的方式也相对简单,而且多模态还包括视频、文本之间的多模态,后续也会专门讲多模态视频分类。


TSM 时间转移模块
使用2D的复杂度,达到3D CNN的性能。TSM的核心思想是将部分通道C沿时间T维进行移位,便于相邻帧之间的信息交换。可以插入到任何二维CNN中,以实现时间建模。
时间转移模块如下图所示。为了简单起见,只显示了时间T和通道C维度,而忽略了批大小N、高度H和宽度W,因为它们与我们的讨论无关。

在图a中,我们描述了一个包含C通道和T帧的张量。不同时间戳的特征在每行中表示为不同的颜色。传统的二维CNN在不同的信道间进行操作,即在不进行时间融合的情况下,沿每一行单独进行操作。在时间维度上,我们将1 / 4通道C在时间维度T上移动了- 1个单位,将另一个单位移动了+1个单位,剩下的一半没有移动(图2b)。“四分之一”是我们将在消融研究中讨论的超参数。哪一1/4shift并不重要,因为下一层的权重会在训练中适应。因此,我们将帧 t - 1、t 、t + 1 的时间信息混合在一起,类似于核大小为3的一维卷积,但计算成本为零。乘法累加被推到下一层。利用二维卷积的信道间融合能力,实现了原始的时域间融合。

将视频分成N段,每段采样一帧。采样的帧跨越整个视频,支持长期的时间关系建模。然后将二维CNN应用于每一帧,提取空间特征。在每个二维残差块内,我们的时间移位模块将部分通道沿时间维数移动±1,融合时间信息。然后,通过沿通道的二维卷积处理移位激活。
我们发现,将时间移位模块插入到残差分支中是有益的,而不是外部的,这样就不会损害主干二维CNN的空间特征学习能力。我们还添加了一个额外的时间最大池层来减少时间维度,与纯2D CNN相比,实现了更少的计算。
6.2.3 3D卷积
能不能不用计算光流(计算光流即麻烦又耗时,无法实现工业实时落地),直接从多帧图像中提取时序与运动信息?
3D卷积:增加时间维度time(帧)
C3D 三维卷积
3D ConvNets 更适合学习时空特征,通过3D卷积(3x3x3)和3D池化(1x2x2时序上不做下采样,保留时序信息;2x2x2时序上也做下采样),可以对时间信息建模,而2D卷积只能在空间上学习特征。
video clips size:
c
∗
l
∗
h
∗
w
c*l*h*w
c∗l∗h∗w,其中,c是通道数量,l是帧长度,h是帧高,w是帧宽(实际上是3 x 16 x 112 x 112)
3D kernel size:
d
∗
k
∗
k
d*k*k
d∗k∗k, d是 kernel 时域深度(d<l),k是 kernel 空间尺寸(实际上就是把3x3卷积核,都变成3x3x3)

class C3D(nn.Module):
# C3D模型的实现挺简单的。想要得到时序上的关系,那么把时序也纳入卷积,即二维卷积变三维,实现可以看作是3D版VGG
def __init__(self):
super(C3D, self).__init__()
# 所有3D卷积滤波器均为3×3×3,步长为1×1×1
self.conv1 = nn.Conv3d(3, 64, kernel_size=(3, 3, 3), padding=(1, 1, 1))
# 为了保持早期的时间信息,pool1有些许不同
self.pool1 = nn.MaxPool3d(kernel_size=(1, 2, 2), stride=(1, 2, 2))
self.conv2 = nn.Conv3d(64, 128, kernel_size=(3, 3, 3), padding=(1, 1, 1))
self.pool2 = nn.MaxPool3d(kernel_size=(2, 2, 2), stride=(2, 2, 2))
self.conv3a = nn.Conv3d(128, 256, kernel_size=(3, 3, 3), padding=(1, 1, 1))
self.conv3b = nn.Conv3d(256, 256, kernel_size=(3, 3, 3), padding=(1, 1, 1))
self.pool3 = nn.MaxPool3d(kernel_size=(2, 2, 2), stride=(2, 2, 2))
self.conv4a = nn.Conv3d(256, 512, kernel_size=(3, 3, 3), padding=(1, 1, 1))
self.conv4b = nn.Conv3d(512, 512, kernel_size=(3, 3, 3), padding=(1, 1, 1))
self.pool4 = nn.MaxPool3d(kernel_size=(2, 2, 2), stride=(2, 2, 2))
self.conv5a = nn.Conv3d(512, 512, kernel_size=(3, 3, 3), padding=(1, 1, 1))
self.conv5b = nn.Conv3d(512, 512, kernel_size=(3, 3, 3), padding=(1, 1, 1))
self.pool5 = nn.MaxPool3d(kernel_size=(2, 2, 2), stride=(2, 2, 2), padding=(0, 1, 1))
# 3个FC输出单元
self.fc6 = nn.Linear(8192, 4096)
self.fc7 = nn.Linear(4096, 4096)
self.fc8 = nn.Linear(4096, 487) #最后对应着487个类别(视数据集而定)
self.dropout = nn.Dropout(p=0.5)
self.relu = nn.ReLU()
self.softmax = nn.Softmax() #得到对应类别的预测概率
def forward(self, x):
# forward按模型架构图来就好
h = self.relu(self.conv1(x))
h = self.pool1(h)
h = self.relu(self.conv2(h))
h = self.pool2(h)
h = self.relu(self.conv3a(h))
h = self.relu(self.conv3b(h))
h = self.pool3(h)
h = self.relu(self.conv4a(h))
h = self.relu(self.conv4b(h))
h = self.pool4(h)
h = self.relu(self.conv5a(h))
h = self.relu(self.conv5b(h))
h = self.pool5(h)
h = h.view(-1, 8192)
h = self.relu(self.fc6(h))
h = self.dropout(h)
h = self.relu(self.fc7(h))
h = self.dropout(h)
logits = self.fc8(h)
probs = self.softmax(logits)
return probs
C3D的性能瓶颈:其优点就是可以同时提取时空信息;缺点也显而易见,即具有更庞大的参数数量从而更难训练,因此一般3D网络的深度都较浅,单这样又影响了模型的表达能力,此外,没有办法能够有效的把2D网络的预训练权重迁移到3D网络。
I3D 膨胀三维卷积
视频分类相较于图像分类等任务,多了一个时间维度。而Imagenet挑战赛中的各种2D卷积网络没有办法同时提取时空信息,怎么把2D卷积预训练的权重,扩展到3D卷积上呢? 作者通过了Inflated膨胀(模型和权重从2D变成3D),提出了Two-Stream Inflated 3D ConvNets (I3D) 模型。

Inflated膨胀:
-
对于模型,本文直接把2D卷积或2D池化的 NxN 的kernel变成 NxNxN 的kernel。
-
对于预训练权重,首先把2D卷积核在时间维度上复制N份,然后除以时间维度的维度N,这样做是为了扩展到3D卷积之后,每一层都仍然获取到类似大小的输出相应。如果不除以N,就会出现输出相应会增大N倍,改变了预训练时网络所学习到的数据分布。

Imagenet挑战赛中有很多优秀的模型,作者使用Inception-V1作为骨干网络,将其从2D扩展为3D。


实验表明:加上光流分支的双流I3D网络效果更好。同时I3D把UCF-101和HMDB-51两个数据集刷爆了,后续大家都开始使用Kinetics-400数据集进行测试。

I3D局限性:虽然证明了2D迁移到3D的可行性,但3D卷积计算量非常大,如何改进仍需进一步探索。
3D卷积计算量 解决办法:
由于I3D把分类做到98%之后已经又没有什么提升空间了,所以人们转向提升效率,著名的有P3D(伪3D),S3D(分开3D),R(2+1)D(把3D变成2+1),这三种模型都考虑把3D CNN拆开,以求得到更好的效率。
-
P3D用一个1×3×3的空间方向卷积和一个3×1×1的时间方向卷积近似原3×3×3卷积,通过组合三种不同的模块结构,进而得到P3D ResNet。 -
S3D,将 3x3x3 卷积核都换成 1x3x3 + 3x1x1 卷积,在每个 3x1x1 卷积后加入了 Self-attention 模块 (即文中的 spatio-temporal feature gating)。 -
ResNet (2+1)D,把一个3D卷积分解成为一个2D卷积空间卷积和一个1D时间卷积,改进ResNet内部连接中的卷积形式,然后堆叠成超深网络,明显降低了3D卷积的参数量。 -
D3D,那么自然可以想到能否结合光流的方法,如D3D等。它的着手点是由于一般的3D方法加入光流仍有提升,说明3D CNN的学习并没有很充分,但是加入光流之后免不了速度又慢,怎么才比较好?于是D3D使用蒸馏,让3D模型在光流的监督下进行teacher-student的学习。
①R(2+1)D——混合2D 3D
②分解卷积核

③减少通道关联

Non-Local 非局部神经网络
Non-local Neural Networks非局部神经网络模型(即插即用模块),为了有效捕捉序列中各个元素间的依赖关系,将Self Attention(替代LSTM)用于长距离时空建模。在这里,所谓的序列可以是单幅图像的不同位置(空间序列),也可以是视频中的不同帧(时间序列),还可以是视频中不同帧的不同位置(时空序列)。
Non-Local bolck:其实就是self attention。
设输入的视频一共有 T 帧(在上图中 T=5 ),针对每一帧图像获取的特征图维度为 H × W × d v H \times W \times d_v H×W×dv ,其中 H , W , d v H,W,d_v H,W,dv 分别为每帧图像特征图的高度、宽度以及通道数(通道数即特征维度),那么输入序列 x x x 可以表达为一个 T × H × W × d v T \times H \times W \times d_v T×H×W×dv 维张量。Non-local块的处理过程为:
第一步,对输入序列分别进行三个 1x1x1 的卷积操作(输出特征图通道数为 d v / 2 d_v/2 dv/2 ),得到三个尺寸为 T × H × W × ( d v / 2 ) T \times H \times W \times (d_v/2) T×H×W×(dv/2) 的特征图;
第二步,对三个特征图进行形状变换(“reshape”操作),得到三个特征图的矩阵表示,将这三个矩阵分别记作 Q , K , V Q,K,V Q,K,V,其维度分别为 T H W × ( d v / 2 ) THW \times (d_v/2) THW×(dv/2) 、 ( d v / 2 ) × T H W (d_v/2) \times THW (dv/2)×THW 和 T H W × ( d v / 2 ) THW \times (d_v/2) THW×(dv/2) (这里 Q , K , V Q,K,V Q,K,V 即为 W θ x , W ϕ x , W g x W_{\theta}x,W_{\phi}x,W_{g}x Wθx,Wϕx,Wgx );
第三步,利用 s o f t m a x ( Q T K ) softmax(Q^TK) softmax(QTK) 计算归一化的注意力权重系数;
第四步,将注意力权重系数作用到 V 上,即计算 s o f t m a x ( Q T K ) V softmax(Q^TK)V softmax(QTK)V ,得到一个 T H W × ( d v / 2 ) THW \times (d_v/2) THW×(dv/2) 矩阵;
第五步,将第四步得到的矩阵进行形状变换,得到一个 T × H × W × ( d v / 2 ) T \times H \times W \times (d_v/2) T×H×W×(dv/2) 维张量,将该张量记为 y ;
第六步,对张量 y 进行 1x1x1 的卷积操作(输出特征图通道数为 d y d_y dy ),得到一个 T × H × W × ( d v / 2 ) T \times H \times W \times (d_v/2) T×H×W×(dv/2) 维张量,该张量即为 W z y W_zy Wzy ,然后再将其与 x 相加得到输出 z 。
SlowFast 快慢网络
SlowFast使用了一个慢速高分辨率3DCNN(Slow通道)来分析视频中的静态内容(环境),同时使用一个快速低分辨率3DCNN(Fast通道)来分析视频中的动态内容(动作)。为了更好的提取slow分支特征,slow通道的计算会更加复杂,Slow通道的计算成本要比Fast通道高4倍。

双分支提取
Slow通道和Fast通道都使用i3D RestNet模型,捕捉若干帧之后立即运行3D卷积操作:
- Slow通道使用一个较大的时序跨度(即每秒跳过的帧数),通常每隔16帧取1帧(共32帧取4帧)。
- Fast通道使用一个非常小的时序跨度τ/α,其中α通常设置为8,每隔1帧取1帧(共32帧取32帧)。Fast通道通过
使用小得多的卷积宽度(kernel数量=out_channel)来保持轻量化,通常设置为慢通道卷积宽度的⅛,这个值被标记为β。使用小一些的卷积宽度的原因是Fast通道需要的计算量要比Slow通道小4倍,虽然它的时序频率更高。
特征融合
来自Fast通道的数据通过侧向连接被送入Slow通道,这使得Slow通道可以了解Fast通道的处理结果。单一数据样本的shape在两个通道间是不同的,这要求SlowFast对Fast通道的结果进行数据维度变换,然后融入Slow通道。论文给出了三种进行数据维度变换的技术思路,其中第三个思路在实践中最有效。
效果:(3)>(1)>(2)
- (1)Time-to-channel:将{αT, S², βC} 变形转置为 {T , S², αβC},就是说把α帧压入一帧
- (2)Time-strided采样:简单地每隔α帧进行采样,{αT , S², βC} 就变换为 {T , S², βC}
- (3)Time-strided卷积: 用一个5×12的核进行3d卷积, 2βC输出频道,跨度= α.
有趣的是,研究人员发现双向侧链接,即将Slow通道结果也送入Fast通道,对性能没有改善。
在每个通道的末端,SlowFast执行全局平均池化,一个用来降维的标准操作,然后组合两个通道的结果并送入一个全连接分类层,该层使用softmax来识别图像中发生的动作。
6.2.4 弱监督


IG-65M

OmniSource


6.2.5 Transformer based
基于Transformer的video工作看这篇:Transformer-based Video Understanding
TimeSformer
FBAI团队的TimeSformer,这也是第一篇使用纯Transformer结构在视频识别上的文章。
https://zhuanlan.zhihu.com/p/449323671

ViViT
https://zhuanlan.zhihu.com/p/451386368
Video Swin Transformer

VATT
对比学习引入视频特征学习

BeiT
Bert预训练
完形填空

BeiT
解耦表征学习



高效计算
视频帧内部、帧之间的自注意力计算,计算复杂度非常高
VideoSwin

Video MobileFormer

DynamicViT and AdaViT

AdaFrame

Ada3D

STTS





6.3 Dataset
Video领域的数据集(按时间划分):Videos Understanding Dataset
 文章来源:https://www.toymoban.com/news/detail-666219.html
文章来源:https://www.toymoban.com/news/detail-666219.html
七、多模态video预训练
多模态video预训练看这篇:Multimodal Video Pre-trainin文章来源地址https://www.toymoban.com/news/detail-666219.html
到了这里,关于视频理解多模态大模型(大模型基础、微调、视频理解基础)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!