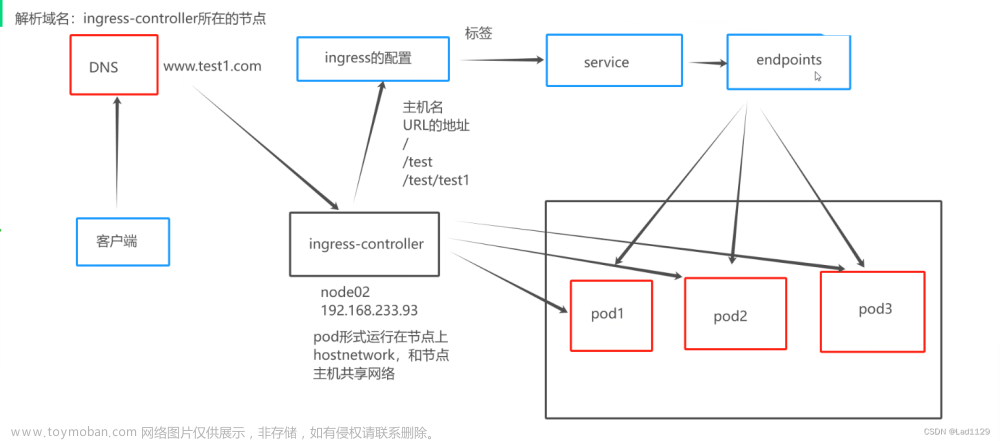
原文作者:陶辉 - 杭州智链达数据有限公司,联合创始人兼 CTO
原文链接:课程实录 | Ingress Controller 的工作原理(下)
转载来源:NGINX 开源社区
NGINX 唯一中文官方社区 ,尽在 nginx.org.cn
编者按——本文为系列课程《 K8S Ingress Controller 技术细节探讨》的第一节《 Ingress Controller 的工作原理》的课程实录。由于文章较长,将分为上下两篇发布,点击这里观看课程回放。
在本节课程中,陶辉老师介绍了 NGINX 集群是怎么工作的,并对比 NGINX 官方和 Kubernetes 官方的两个 Ingress Controller 在运行时各自的特点以及性能上的差别。
课程内容包括 Kubernetes 的网络流量场景,以及 NGINX 集群该如何管理,如何解决分布式集群中常见的高可用、容灾、扩容等问题。
数据的高可用
第二个方面,高可用体现在 Kubernetes 集群本身的管理层面上。

假如我们给 Kubernetes 的池里放 100 台物理机,当你需要新起个 NGINX 时,只需要新起个 pod 。在 pod 池里面新起一个 pod ,立刻就能搞定所有的事情。
能搞定哪些事呢?第一,可以任意分配一个 IP 地址,比如原本 10.1.2.3 ,换成 10.1.100.100 。这是由 Networking 来完成的,也就是由 CNI 插件(网桥)来完成的。网络由 Kubelet 管理,存储及 Protobuf、gRPC、JSON 等协议,都在里面。
也就是说 Kubernetes 的 Scheduler (编排)会自动管理, APIServer 做通讯。因此运维人数可以大幅度减少,只需要通过 APIServer 在控制面板做一些操作,就可以自动地把托管的容器 pod 解决。
在此基础上,我们的 NGINX Ingress Controller 也自动地得到了高可用。所以,如果不基于 Kubernetes 去做 NGINX 的集群管理,要花更多的功夫来保证 NGINX 本身的高可用。
NGINX 高可用地管理 Kubernetes 中的 pod
接下来看 NGINX 如何高可用地管理 Kubernetes 中的 pod 。

关于此处相关精彩内容,您可以点击文章《课程实录 | Ingress Controller 的工作原理(下)》进行查看。
nginx.conf 模板
下面简单介绍一下 nginx.conf 模板。

Kubernetes 官方的模板是 Go 语言的一个模板, ETCD 里面的指令通过 JSON 写进去,就会通过替换模板中的字符串变成新的 nginx.conf。
NGINX 官方的更简单一点,分了两个配置,一个叫 nginx.tmpl ,一个叫 nginx.ingress.tmpl ,这两个模板的差别就是把 server 单独放在 ingress 里了,通过 nginx.conf 的 include 功能完成。
Reload 流程
NGINX 中的 reload 流程如下图。

当基于新的 nginx.conf 起了新配置时,新老配置同时存在,理论上来讲用户是感知不到 reload 重启的,但是在高并发、高性能、高吞吐量的场景下, reload 还是会有一些影响,产生长尾效应,百分之零点零几的请求可能会受到影响。
这也是为什么 Kubernetes 官方用 OpenResty 实现 Ingress controller 的原因之一。
Kubernetes 官方 Ingress controller 架构
下面介绍一下 Kubernetes 官方的 Ingress controller 架构。

Kubernetes APIServer 里面能拿到 ETCD 的五类数据 (Ingress、Service、Endpoint、Secret、ConfigMap,ConfigMap) ,在那之后,我们需要一个 Go 语言写的进程去管理 nginx.conf ,以及向 Lua Server 发送更新请求——也就是改共享内存。
这两件事是怎么样完成的呢?
Go 语言中有很多协程,在一个 Go 语言写的进程里面,会并发很多协程——若不熟悉协程,可以将其当成一个线程理解。上图中的 store 协程,就是在跟 APIServer 通讯,以便通过 informer 模式来监听资源的变化。
也就是说,ETCD 里五类数据一旦发生变化, APIServer 就要推给 store 协程。如果有一台机器挂掉, endpoint 就改了;如果有人更新了密钥, secret 就改了;如果 worker 进程数从两个变到四个, ConfigMap 就改了;加了新的域名, ingress 就改了……发生变化之后, store 协程就会知晓。
之后, Store 协程会把 APIServer 传过来的修改/更新事件,写到 Channel ( Go 语言中,两个协程之间进行通讯的一种方式) 中, NGINX Ingress Controller 这个主程会从 Channel 中取出数据,放到一个同步队列中。另外还有一个协程 ( SyncQueue ),会把数据读出来开始处理。
处理的时候,会有些简单的判断,第一,有没有改 nginx.conf 文件,如果改了,就执行 reload 。有一种情况不需要改,就是 endpoint 发生变化时。这对大规模集群来说是一个高频事件,假如有 1 万台机器,可能每分钟都会挂掉几台,这是很常见的。
如果每分钟都去执行 NGINX reload ,性能就会很差。面对这一问题,基于 OpenResty 的 balance by Lua ,会将 endpoint 的信息保存到 shared DICT 中(一种 Lua 数据结构,通过将共享内存抽象成一个基于红黑树和 LRU 的淘汰链表而实现)。
所以判断条件分为两类:一类是只修改了共享内存中的数据,则只需发送一个 http 请求(这是一个 REST API ,它的 method 的是一个 POST 请求,内容是一个 JSON ),把信息发给 NGINX 即可;第二类是修改了 nginx.conf 配置,则执行 reload , NGINX 就可以用新的配置来服务了。
Kubernetes 官方 Ingress controller 中的流程
下面简单介绍 Kubernetes 官方 Ingress controller 中的流程。其中有个共享内存,里面保存了 Backend (即后端上游信息)、证书等,它是通过 Lua 代码来管理的。

然后,基于 Go 语言写的进程通过许多端口来服务,比如我们修改共享内存的时候,是通过本机的 10246 端口来修改的。这个进程还跟 APIServer 通过 client-go 这个 SDK 来通讯——通过 Store 这个 package ( Go 语言中有 package )。
Kubelet 是本机上的每一个机器、每个 node 上都有的进程,它通过 10254/healthz 来管理健康状态。
关于 Prometheus ,它是 CNCF 里面的第二个项目(第一个是 Kubernetes ),它是做监控的,是一个开源的、现在也被广泛使用的一个可视化的监控系统,通过 10254/metrics 来管理。
这是大概的情况,未来的课程中会详细介绍这一流程。
Ingress controller 的性能比较
最后,为大家展示两个对比测试结果,有三个 Ingress controller ,都是基于 NGINX 来实现的。
第一个是 NGINX 官方的 NGINX OSS Ingress Controller ( OSS 即 Open Source ,开源);第二个是 NGINX Plus Ingress Controller ( NGINX Plus ,是 NGINX 的商业化版本),它是闭源的;第三个是 Kubernetes 官方社区提供的 Ingress controller ,基于 OpenResty ——也是 NGINX 实现的,只不过加了 Lua 语言。(由于 NGINX Plus 是闭源的,所以下面的测试结果中,未对其进行解析。)
下面两张性能测试的图表分别为:静态部署测试、动态部署测试。Kubernetes 中有许多 Ingress controller ,它们会被部署到很多 pod 里,如果这些 pod 总是发生变化,意味着什么?
对于官方 NGINX 来说,就是 nginx.conf 变了;对于 Kubernetes 来说,意味着共享内存里的数据变了,因为它是通过 Lua 来修改的。这就是动态部署。而静态部署,意味着 nginx.conf 基本是不变的。
先看静态测试的图, x 轴是百分比, y 轴是时延 ( latency )。

每秒钟发送 3 万个请求( 3 万 RPS )的情况下, 99% 的请求时延小于 50 毫秒,到了 99.9% 的时候 OpenResty 时延就变高了,接近 100 毫秒——原因在于 Lua ,因为每处理一次请求,从 C 语言跳到 Lua 语言要执行一次 balance by Lua ,所以变慢了。
99.99% 的时候,表现最好的是开源的 NGINX ,因为它最简单,是纯 C 语言的,也不支持动态修改,动态修改需要重新 reload ,而它没有 reload 。所以开源 NGINX 表现最好,表现最差是 Lua 。
动态测试中,大概每隔 10 秒到 12 秒,就把 pod 数从 5 个到 7 个之间反复做调整。

在 3 万 RPS 的情况下,不断地去启停 NGINX 的时候,因为 Lua 走的是 balance by Lua ,根本没有执行 reload ,所以是很稳定的。
开源的 NGINX 表现最差,因为不停的 reload 导致有个别请求时延变高,因为中间会有很多信息,比如丢包,都会导致老的 worker 一直挂着,最后请求会出现一些问题。而只要 NGINX worker 不重启,性能就会非常好。
更具体的细节,大家可以去参看源代码,包括 nginx.conf 模板,以及 Go 语言相关知识等等。以上就是 Ingress controller 的原理,希望对大家有所帮助。
NGINX 唯一中文官方社区 ,尽在 nginx.org.cn文章来源:https://www.toymoban.com/news/detail-666553.html
更多 NGINX 相关的技术干货、互动问答、系列课程、活动资源: 开源社区官网 | 微信公众号文章来源地址https://www.toymoban.com/news/detail-666553.html
到了这里,关于课程实录 | Ingress Controller 的工作原理(下)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!